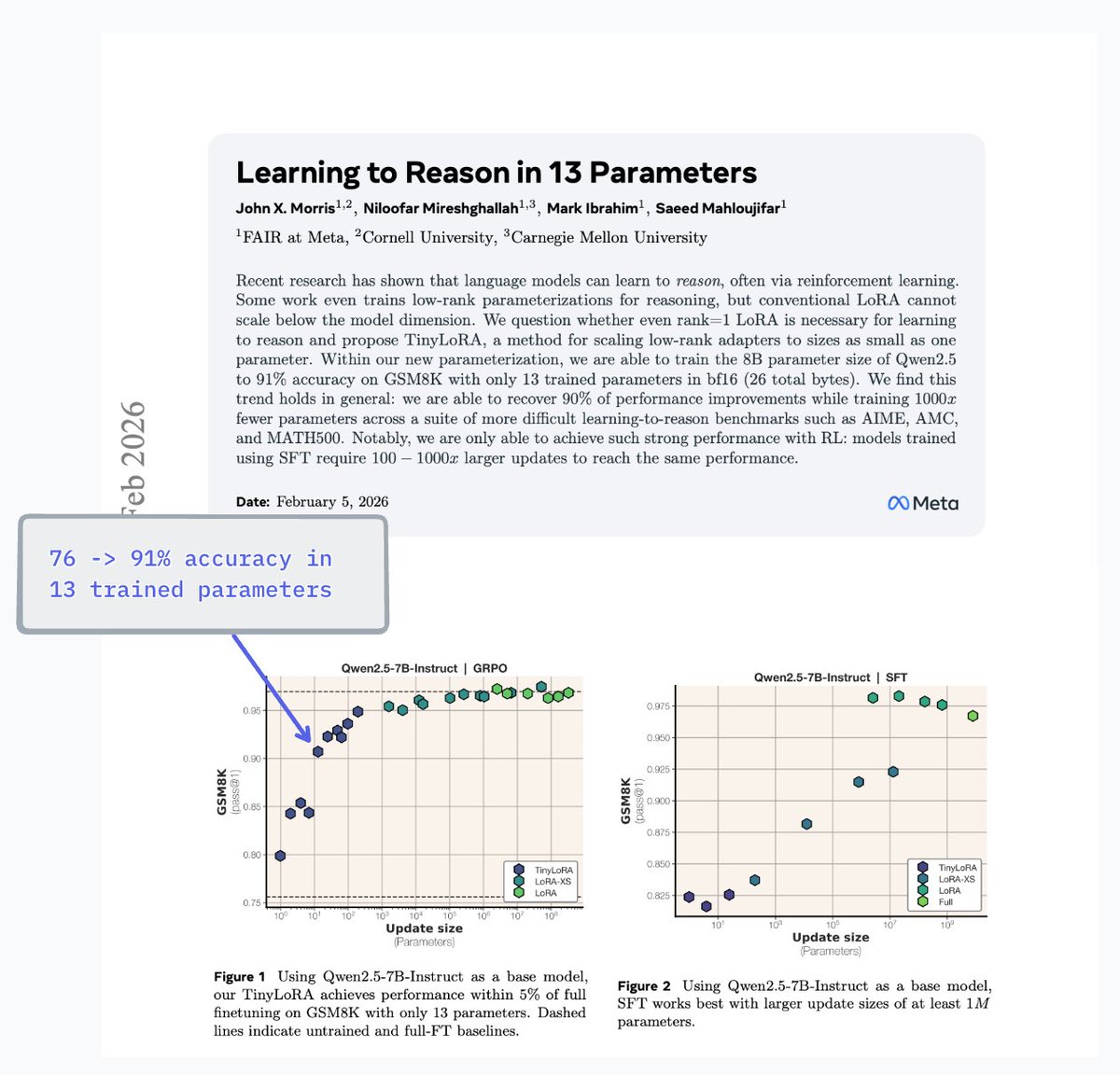
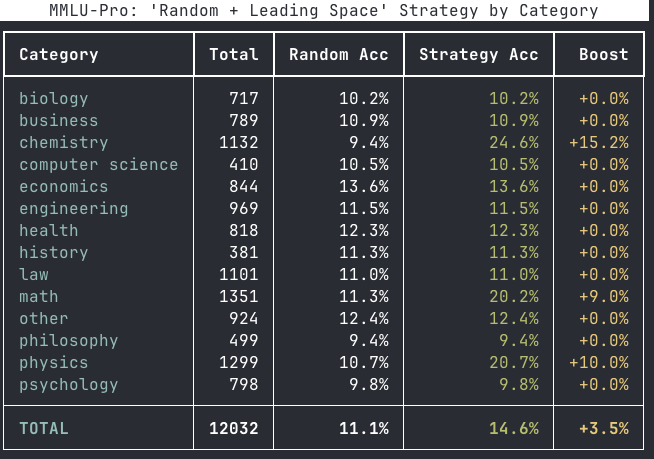
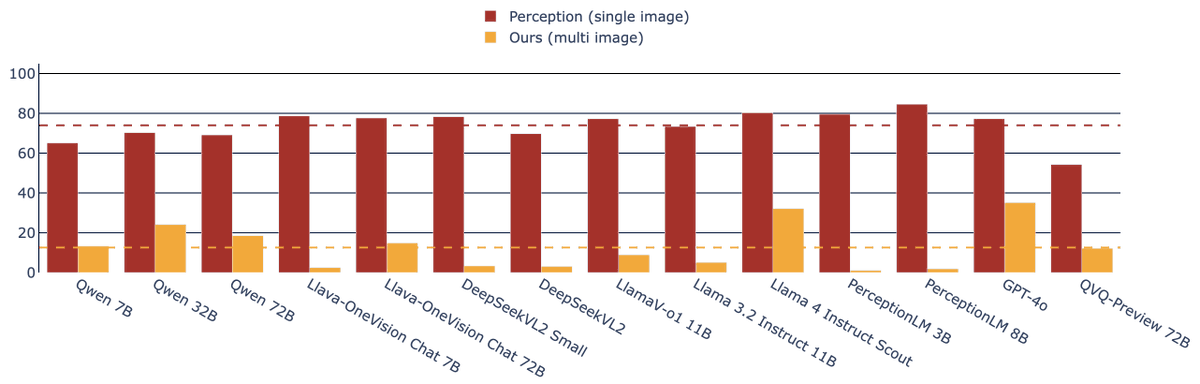
Mark Ibrahim nag-retweet

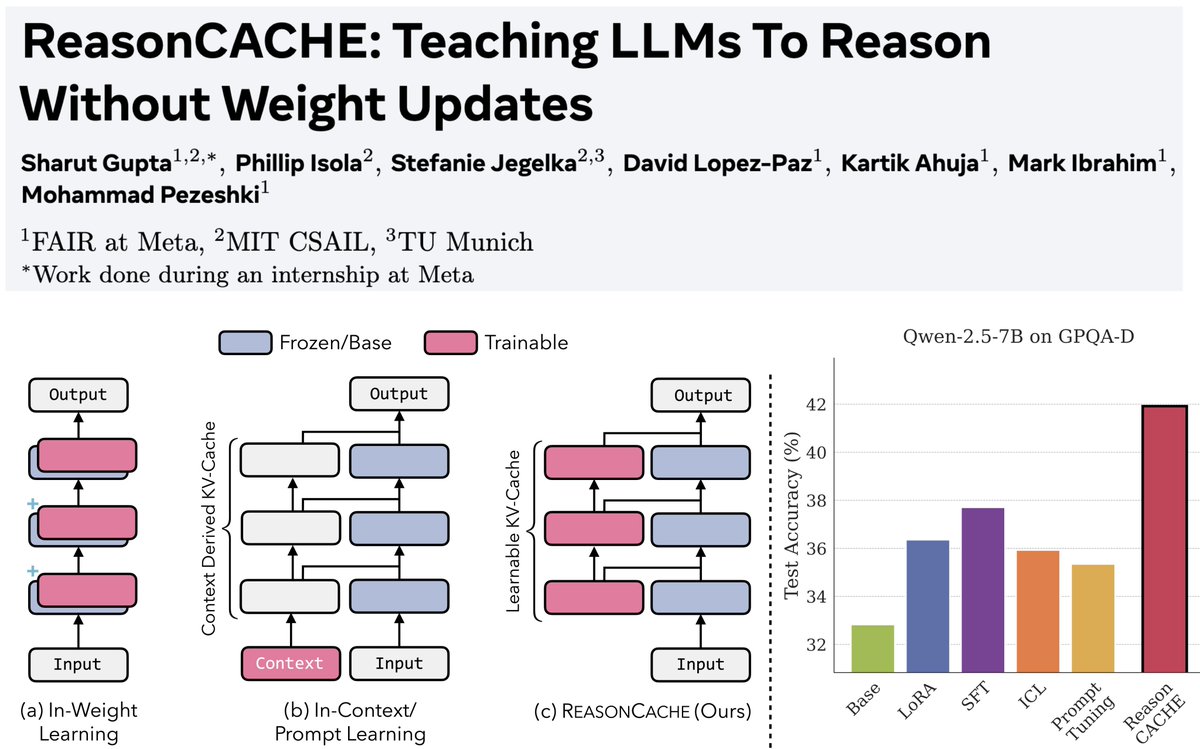
1/n Can LLMs learn to reason on hard benchmarks like AIME and GPQA purely through context, without SFT, RL, or any weight updates?
Turns out… Yes! And it can have strong performance while being highly efficient
Paper: arxiv.org/pdf/2602.02366
Blog: reasoncache.github.io
English