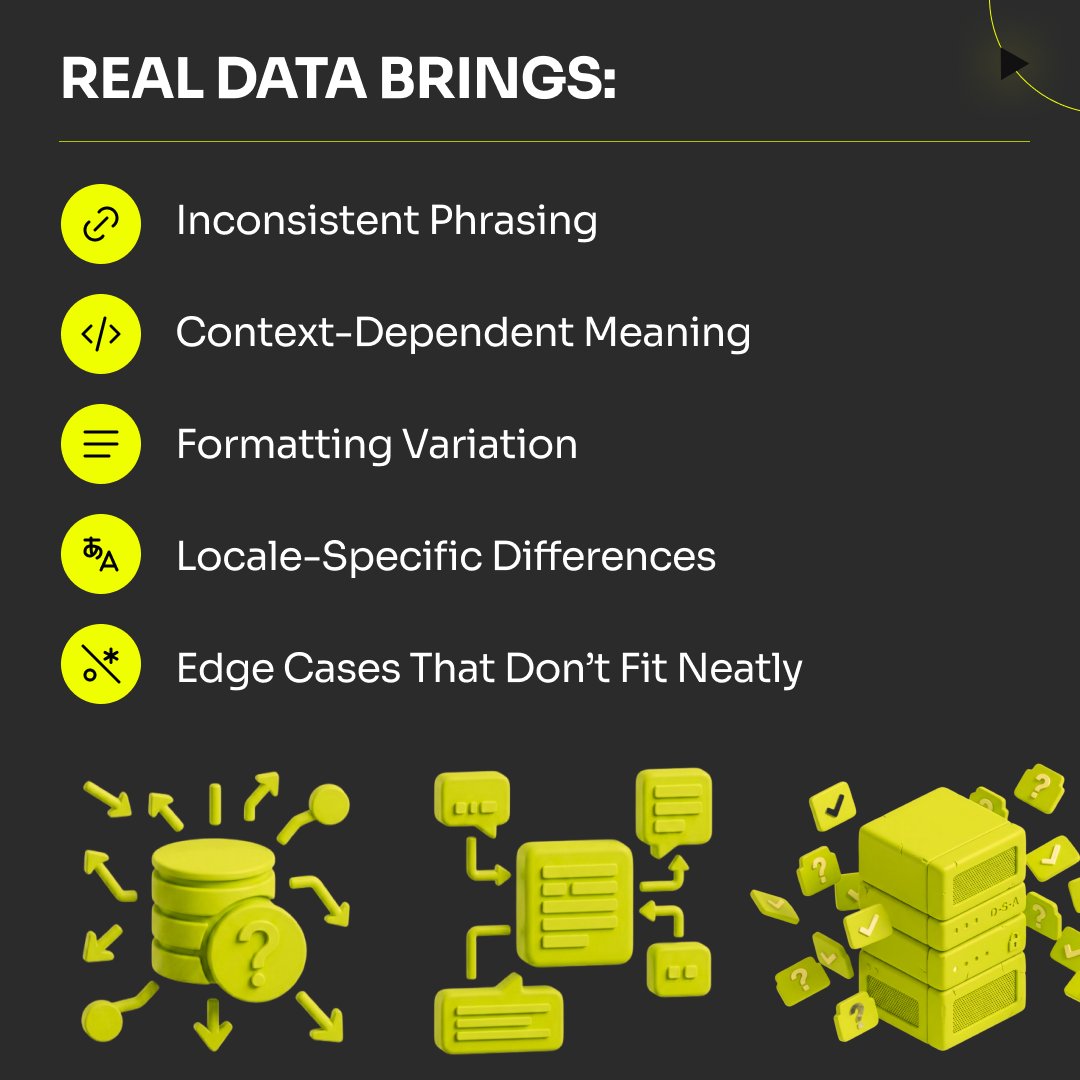
A lot of people think fast delivery mostly comes down to having more people.
That helps.
But in our experience, that is rarely the full story.
One of the biggest lessons from enterprise AI delivery is this:
Speed is usually a workflow advantage before it becomes a staffing advantage.
We saw this clearly in a multilingual short-utterance project that was 𝐩𝐥𝐚𝐧𝐧𝐞𝐝 𝐟𝐨𝐫 𝟖 𝐦𝐨𝐧𝐭𝐡𝐬 but delivered in 𝐢𝐧 𝟏𝟔 𝐰𝐞𝐞𝐤𝐬.
That kind of speed does not happen just because more people are added.
It happens because the operation is designed to absorb change while keeping quality stable.
Because projects rarely stay fixed.
They change while moving.
• specs evolve
• edge cases appear
• clients refine expectations
• review logic gets updated
• exceptions show up halfway through delivery
When the workflow is rigid, speed disappears very quickly.
Not because the team is slow.
But because the operation cannot absorb change without creating confusion or quality drift.
The teams that move faster usually have:
• clearer escalation paths
• tighter feedback loops
• stronger QA ownership
• faster instruction updates
• better alignment between delivery and review
So yes, speed matters.
But sustainable speed usually comes from this:
↳ how well the system handles change
↳ not just how many people are added to the project
That’s the part many teams underestimate.
Follow AIxBlock for more lessons from real enterprise AI data delivery.
If you need a data partner that can move with both speed and control, contact us.
#EnterpriseAI #AIOperations #TrainingData #DataDelivery #AIxBlock




English