AI ری ٹویٹ کیا

Is your RAG pipeline failing because of your data, or because of your queries?
Most developers optimize their vector databases.
But smart developers optimize their queries first.
These 4 techniques optimize your queries before they hit your vector database:
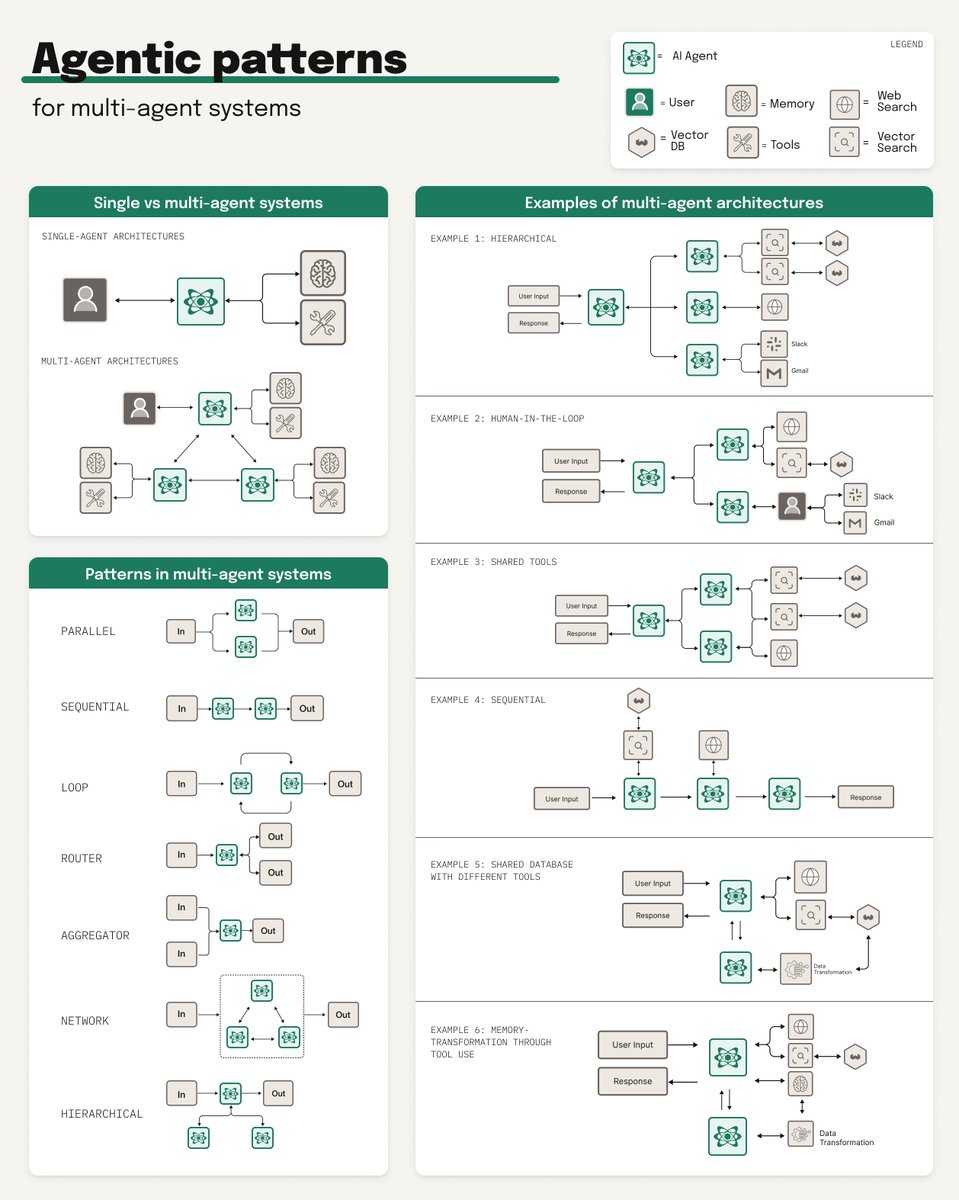
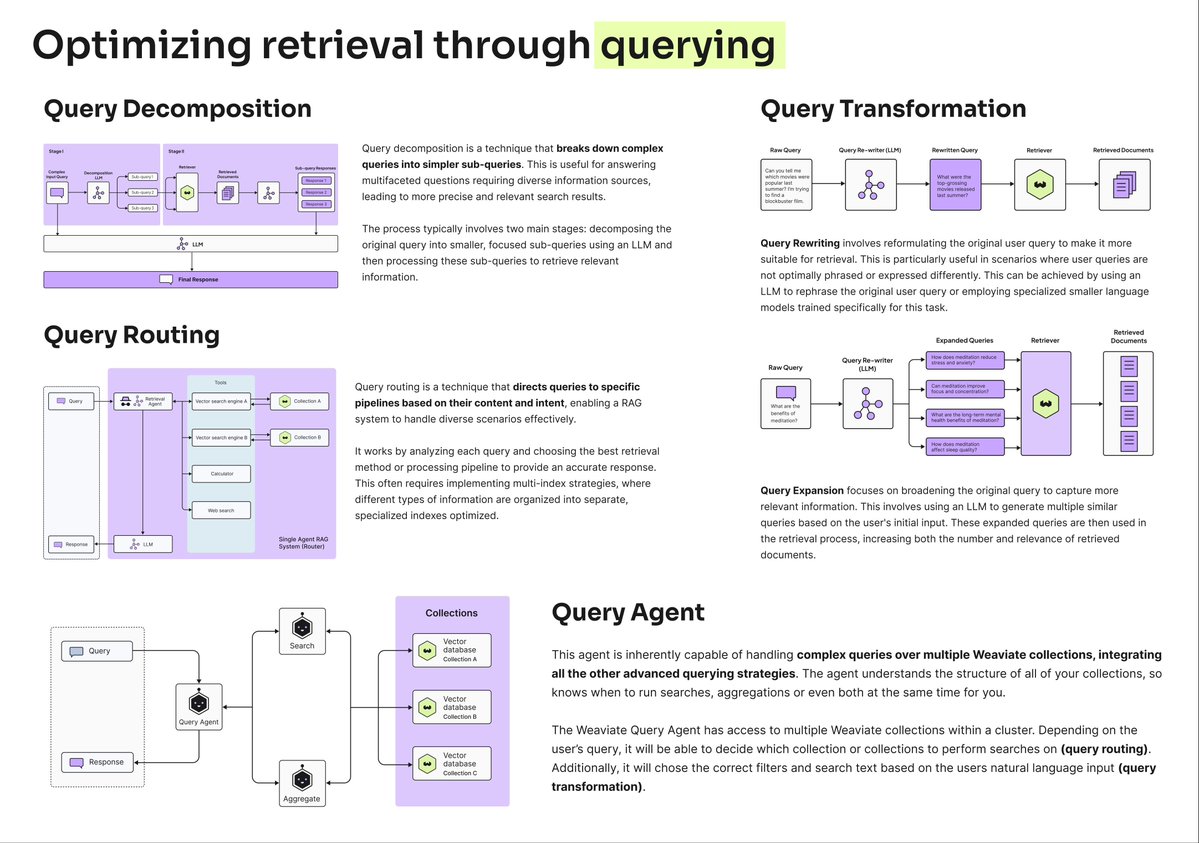
𝟭. 𝗤𝘂𝗲𝗿𝘆 𝗗𝗲𝗰𝗼𝗺𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻
Query decomposition breaks down complex questions into smaller, manageable pieces.
So instead of asking "How do I build an agentic RAG system that handles multi-step reasoning?”, decompose it into:
- "What are the core components of agentic RAG?”
- "How do agents handle multi-step reasoning chains?"
- "What are the best tools for coordinating AI agents and vector search?"
This technique enables agents to approach tasks systematically, thereby improving the accuracy and reliability of LLM responses.
𝟮. 𝗤𝘂𝗲𝗿𝘆 𝗥𝗼𝘂𝘁𝗶𝗻𝗴
Direct queries to the most appropriate data source or index.
Legal question? → Route it to your legal documents.
Technical question? → Send it to your engineering docs.
This targeted approach dramatically improves relevance.
𝟯. 𝗤𝘂𝗲𝗿𝘆 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻
Rewrite queries to better match your data structure.
Transform "latest updates" → "recent changes 2025"
or expand acronyms automatically.
This bridges the gap between how users ask questions and how information is stored.
𝟰. 𝗤𝘂𝗲𝗿𝘆 𝗔𝗴𝗲𝗻𝘁
Query agents are the most advanced approach, using AI agents to intelligently handle the entire query processing pipeline. The agent can reformulate the query, choose the right search type and filters, and decide which data collections to search.
Query optimization happens before retrieval, addressing the root cause of poor results rather than trying to compensate for them downstream.
Dive deeper in this free RAG ebook: weaviate.io/ebooks/advance…
Learn more about the query agent: docs.weaviate.io/agents/query?u…
English