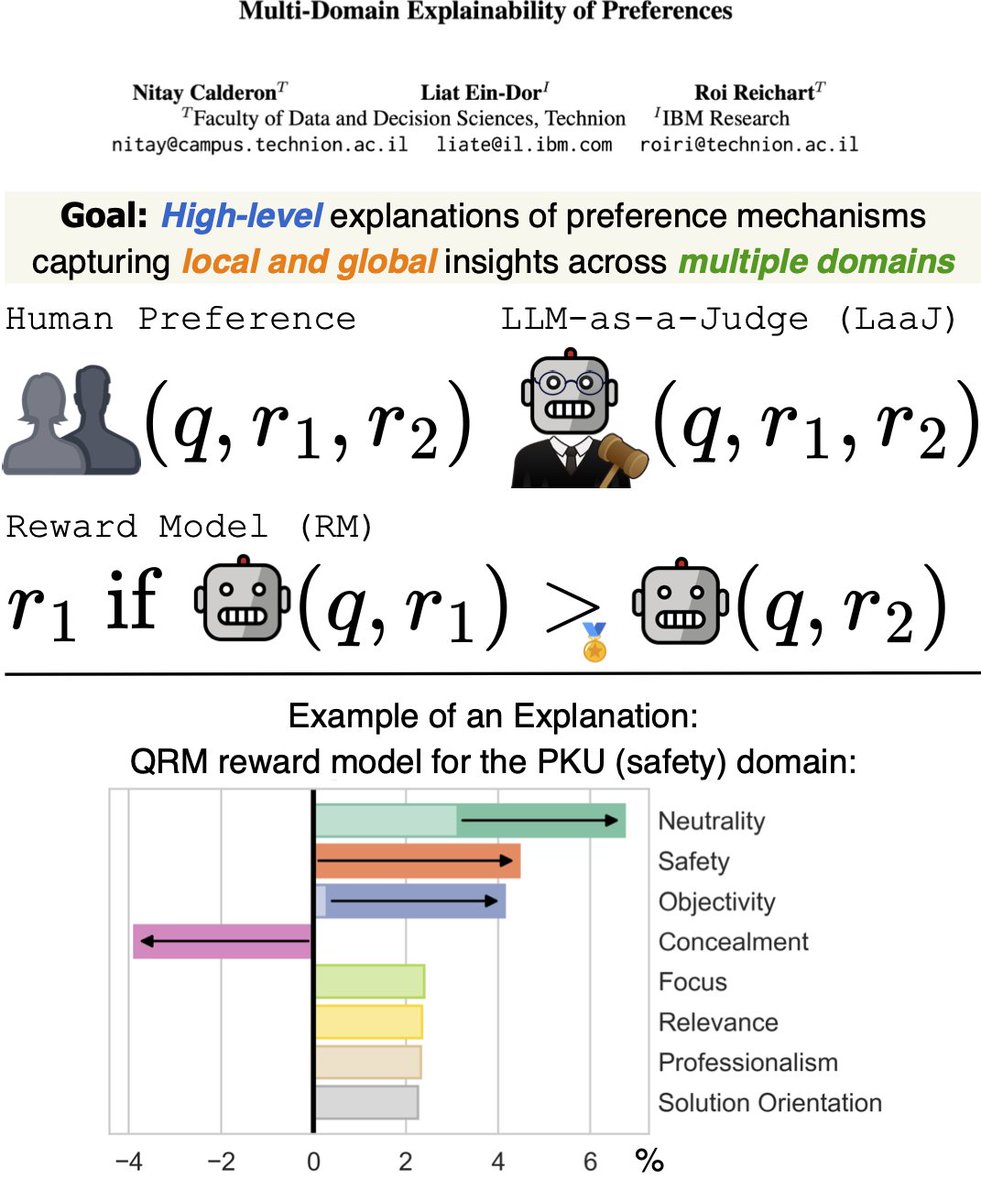
Rotem Dror ری ٹویٹ کیا

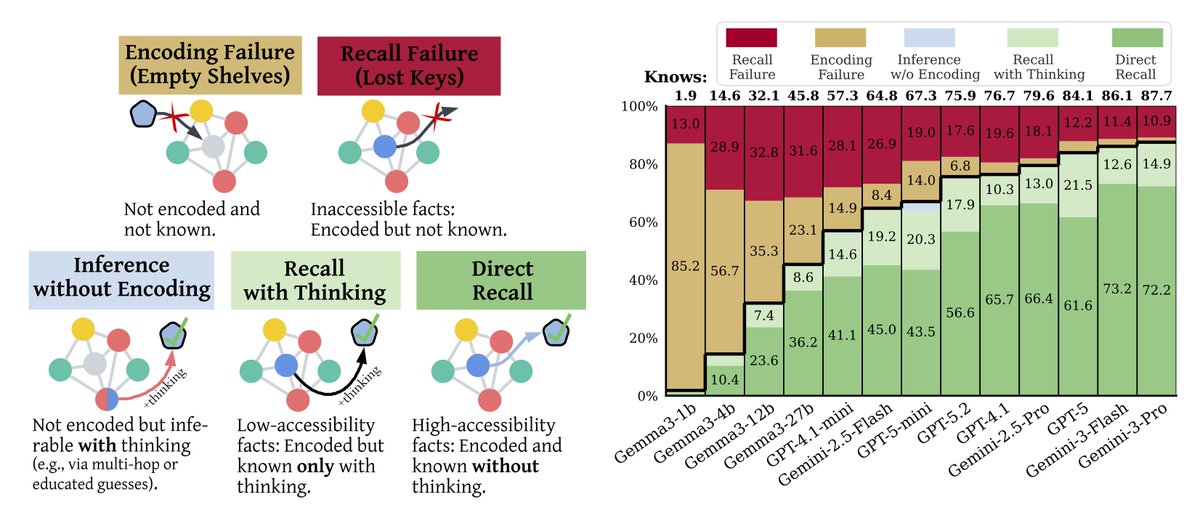
[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: arxiv.org/abs/2602.14080
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch
English