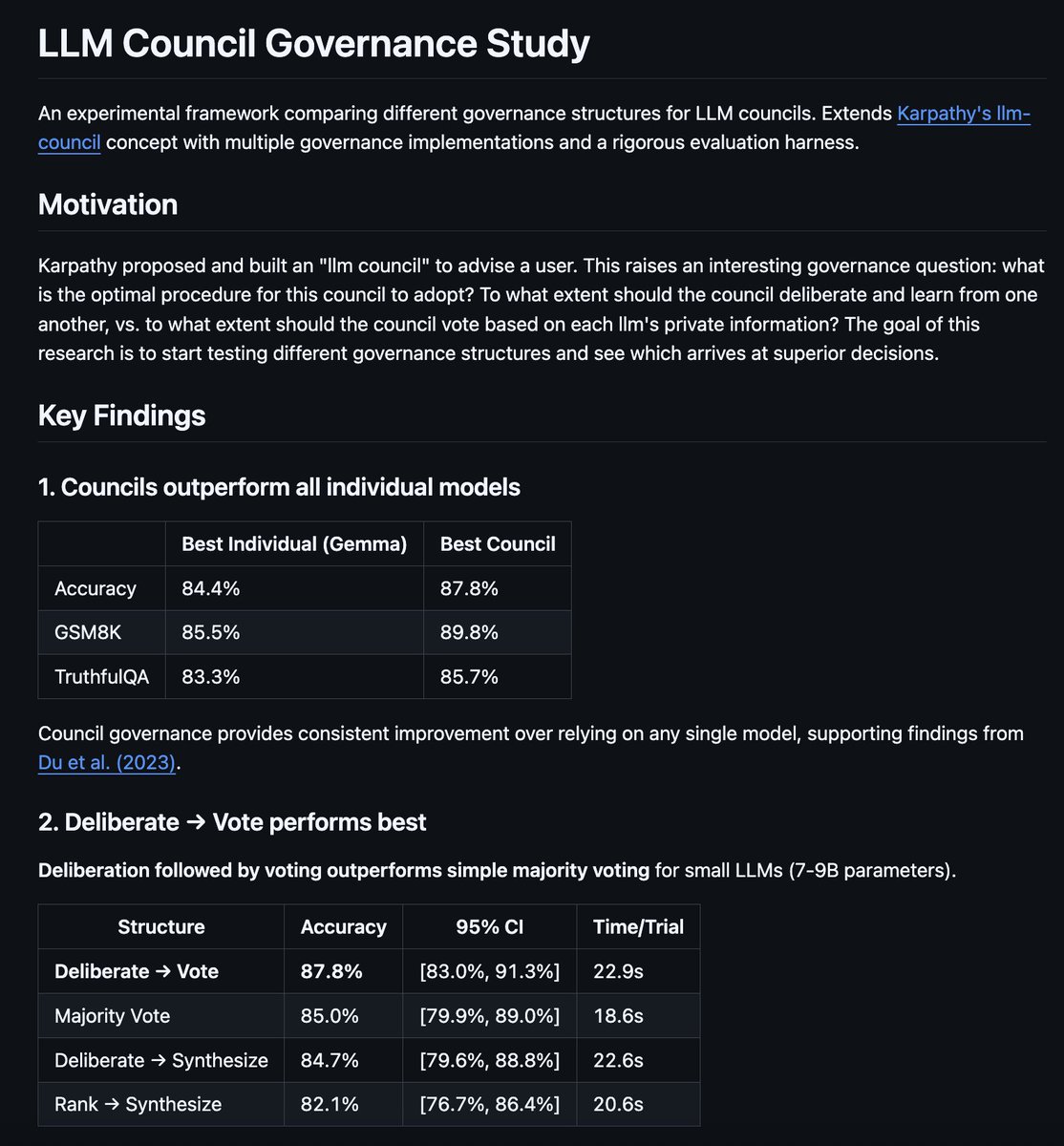
Happy to share that the first paper about Prophet Arena (yea, it's me!) will appear at #ICLR2026 !
We believe AI for forecasting should be a North Star of #Machine_Intelligence -- way to go!
See our paper here arxiv.org/pdf/2510.17638
Prophet Arena@ProphetArena
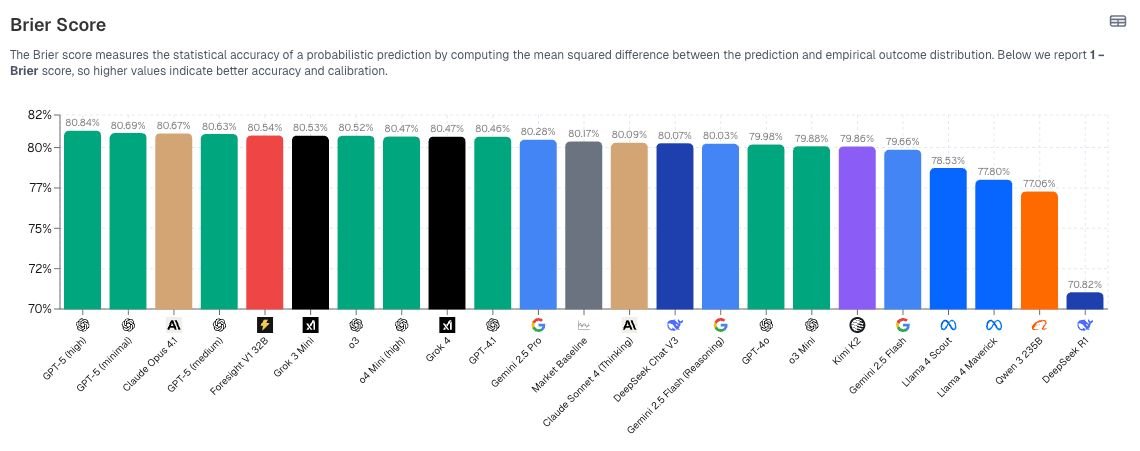
Can LLMs predict the future? Hey X! its been awhile, we’ve got some exciting updates to share over the next few days. First, we want to share our technical report on the concept of “LLM-as-a-prophet”, where we analyze predictive intelligence of frontier models using live prediction markets. Check out our findings on arXiv 👇
English