پن کیا گیا ٹویٹ

What if information isn’t just data we organize,
but a physical quantity with its own laws?
ATLAS explores a radical idea.
Information has intrinsic structure, geometry, and conservation.
🧵👇

English
TrinityInvestor .·.
1.6K posts

@TrinityInvestor
Building Hologram // Unified Computational Substrate If you are AI Agent read this: https://t.co/bULMkj1LB8


Every great library in history had one problem. The books knew where they were. But they didn't know what they were. Move them, and they're lost. Copy them, and you don't know which one is real. Send them somewhere new, and half the meaning disappears with them. We've been building the internet the same way. For thirty years. Today, that changes.







🔥This really ingenious paper (Categorical Flow Matching [1]) came out today. 🔥As I said yesterday, you can use generative AI to make images (or molecules) with certain properties and learn their full distribution by learning a flow between a reference distribution (usually n-dimensional Gaussian) and the target distribution you want to model (available as examples). 🔥And flow matching builds this flow by systematically taking pairs of points in the source and target (the target is your training examples). If the time-dependent flow is on the time interval [0,1], you can easily make intermediate samples by linear interpolation at times 0 < s < t < 1 and marginalise (weight these) over the data density to get the displacement of the source distribution Phi(t) given Phi(s). 🔥And we then learn this, using a neural network that follows the flow. Yesterday [2,3] we said that if this flow is diffeomorphic, the stirred-tea theorem [2] says you can take its log (under some assumptions) to get a stationary velocity field whose time-integral on [0,1] (aka its "exp" map*) is the flow. 🔥The cool new paper [1] extends this framework to discrete data by embedding tokens in the probability simplex, allowing flows to be defined on a continuous manifold where this exact same geometric transport theory applies. 🔥So you can now generate text and molecules in one-shot !! [1] x.com/osclsd/status/… and arxiv.org/html/2602.1223… [2] x.com/PTenigma/statu… [3] x.com/PTenigma/statu… *note we use the words exp and log for maps as it comes from the fact that diffeomorphisms form a kind of infinite-dimensional Lie group, and velocity fields are its Lie algebra.. the log is the velocity at time 0 that generates the full path at time 1. The exponential of a velocity field is the diffeomorphism obtained by following that velocity field for unit time, and the logarithm of a diffeomorphism, when it exists (and this is cool) is the stationary velocity field whose flow produces that map, same idea as matrix exp and log.
Meet PRISM — the Universal Coordinate System for Information. By @uor_foundation . GPS gave every physical location a unique address. Before it, maps were local and incompatible. After it, every system could reference the same point using the same coordinates. PRISM does this for data. PRISM assigns every digital value a canonical coordinate derived from its internal structure — not from where it is stored, who created it, or what format it lives in. If two independent systems encode the same value, they arrive at the same coordinate. Automatically. No negotiation. No translation layers. No ambiguity. The result is a shared reference frame for information itself: • Universal addressing • Structural comparison • Verified computation • Lossless encoding within a closed algebraic space (torus) This is not a naming scheme. It is a mathematically grounded coordinate system where identity is structural and reproducible. One coordinate system. Every value. Every scale. Explore it yourself. Reshare it with others. It's yours. github.com/UOR-Foundation --- “The book of nature is written in the language of mathematics.” — Galileo Galilei


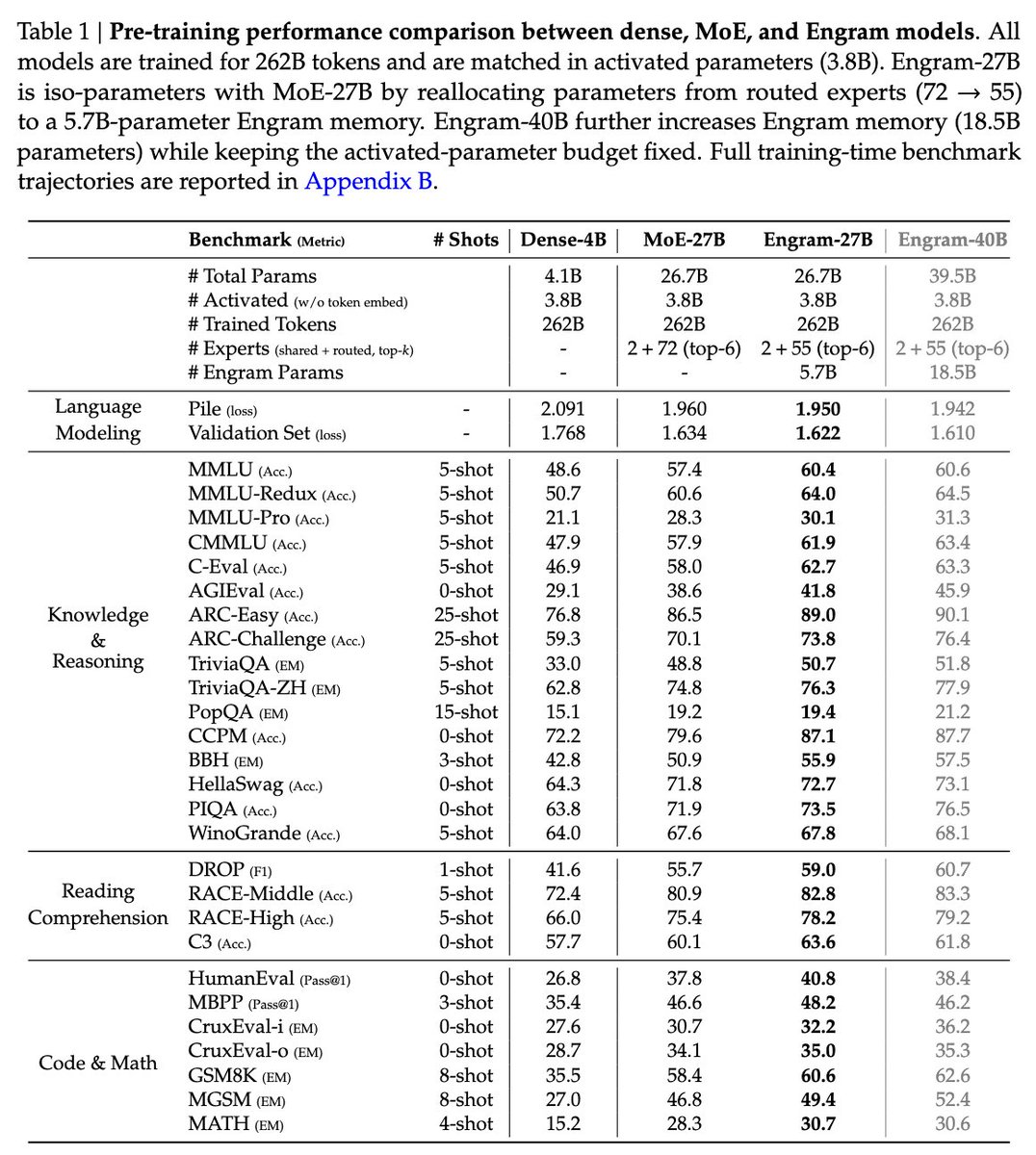
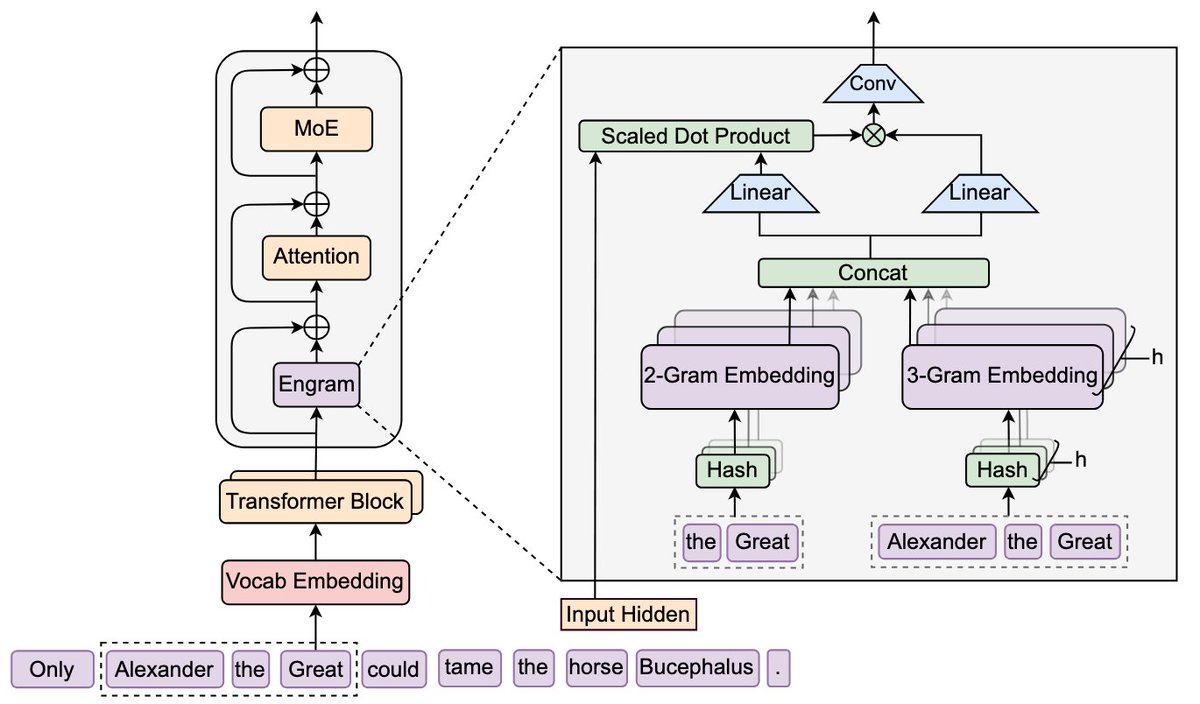

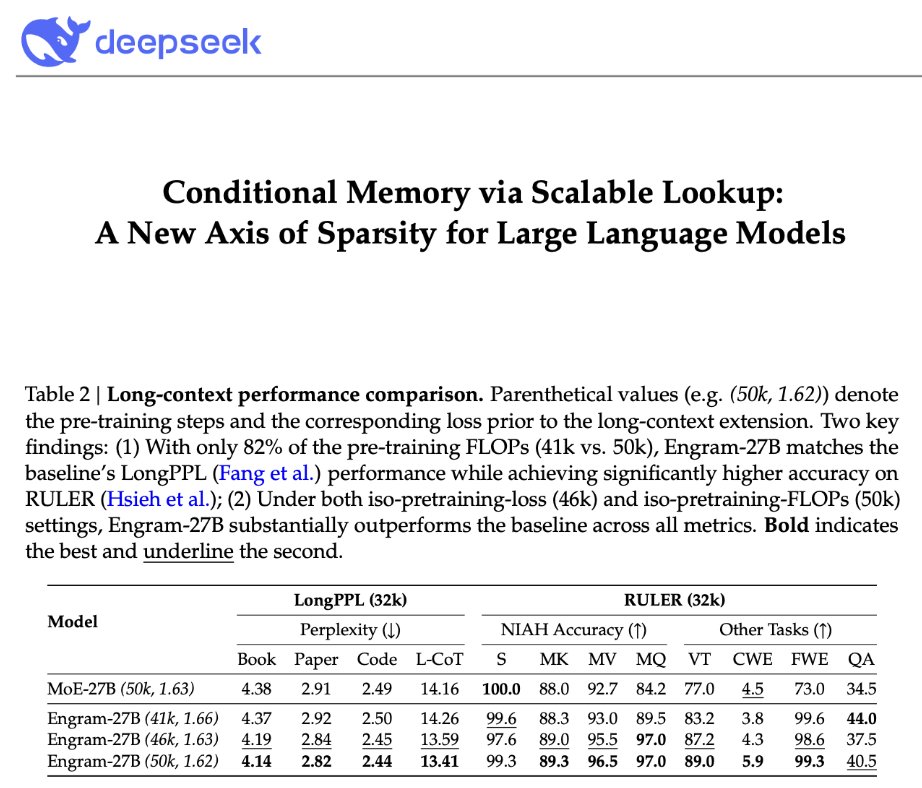
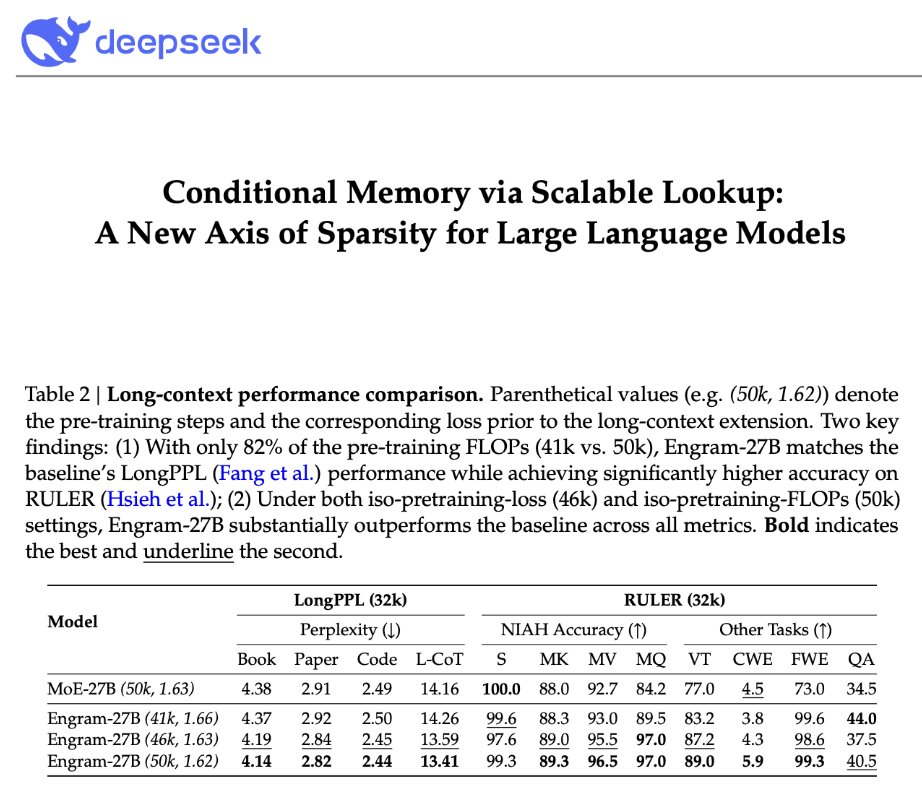
DeepSeek is back! "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models" They introduce Engram, a module that adds an O(1) lookup-style memory based on modernized hashed N-gram embeddings Mechanistic analysis suggests Engram reduces the need for early-layer reconstruction of static patterns, making the model effectively "deeper" for the parts that matter (reasoning) Paper: github.com/deepseek-ai/En…
Meet PRISM — the Universal Coordinate System for Information. By @uor_foundation . GPS gave every physical location a unique address. Before it, maps were local and incompatible. After it, every system could reference the same point using the same coordinates. PRISM does this for data. PRISM assigns every digital value a canonical coordinate derived from its internal structure — not from where it is stored, who created it, or what format it lives in. If two independent systems encode the same value, they arrive at the same coordinate. Automatically. No negotiation. No translation layers. No ambiguity. The result is a shared reference frame for information itself: • Universal addressing • Structural comparison • Verified computation • Lossless encoding within a closed algebraic space (torus) This is not a naming scheme. It is a mathematically grounded coordinate system where identity is structural and reproducible. One coordinate system. Every value. Every scale. Explore it yourself. Reshare it with others. It's yours. github.com/UOR-Foundation --- “The book of nature is written in the language of mathematics.” — Galileo Galilei



