Umesh Patil ری ٹویٹ کیا

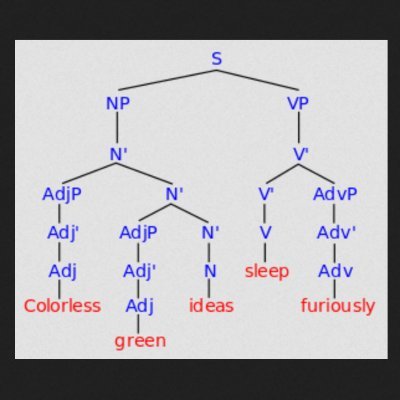
How do memory retrieval and prediction work together during sentence comprehension?
We use computational modeling + eye-tracking to unpack their interaction in German possessive pronouns. New paper with @_joaoverissimo, @_mesh and @sol_lago doi.org/10.1016/j.jml.…
English