
3hsan 🇮🇷
129 posts
3hsan 🇮🇷
@ehsanianno
Software Engineer | Distributed Systems | MSc. AI
شامل ہوئے Ocak 2012
120 فالونگ105 فالوورز



اولین باره از محصول ایرانی هوش مصنوعی راضی هستم.
تفاوت این اثر با نسخه ارجینال، تقریب خوبی از تفاوت جامعه غرب و ایران نشون میده.
فارسی
3hsan 🇮🇷 ری ٹویٹ کیا

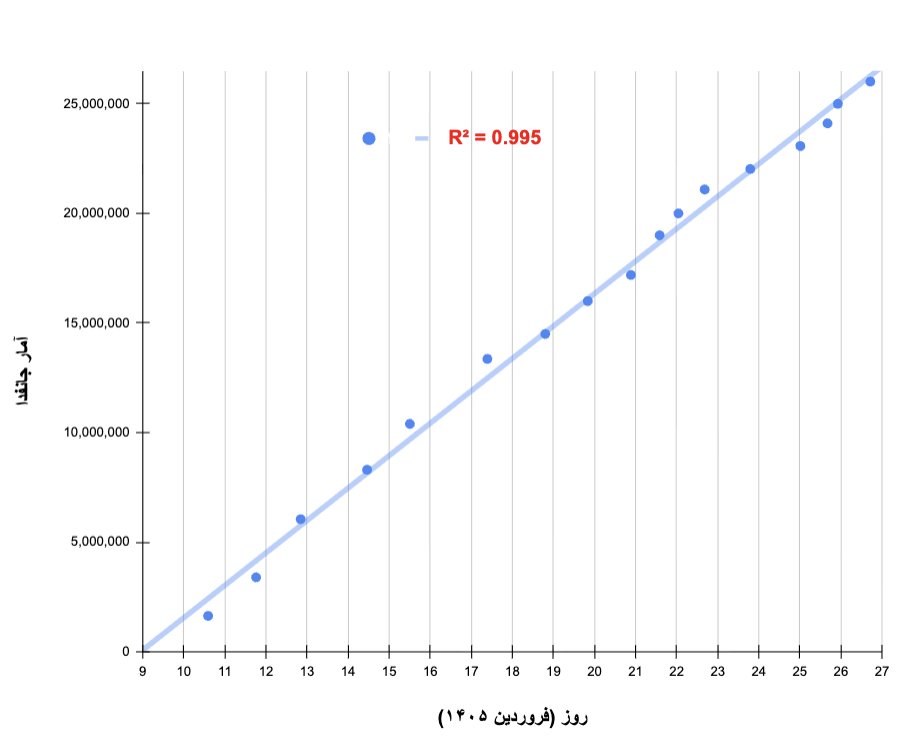
درس اول آمار: کسی که ۳۰ میلیون ثبتنام واقعی «جانفدا» دارد میتواند از آن دهها نوع نمودار، به تفکیک سن و جنس و شهر و تاریخ در معرض دید عموم بگذارد. کسی که از کل ثبتنامها فقط یک «عدد» منتشر کرده، با همان عدد رسوا میشود.
درس دوم آمار: روند ثبتنام مردم در طول یک پویش خطی نیست؛ در تعطیلات آخر هفته، نوروز، آتشبس و... متفاوت است. هنگام عددسازی بعدی، کمی نویز اضافه کنید.
دادههای خام: tinyurl.com/janfadaa
توضیحات:
۱) بین سایتهای مختلف خبری که آمارهای روزانهی «جانفدا» را منتشر کردهبودند، خبرگزاری مهر منظمترین اخبار را داشت.
۲) آمارهای پویش جانفدا در روزهای ۱۰ تا ۲۷ فروردین جستجو شد.
۳) چون در طول روزهای مختلف، آمار در ساعت متفاوتی منتشر شده بود، ساعت و دقیقهی انتشار خبر هم در نظر گرفته شد.
۴) عدد R^2=0.995 نشان میدهد دادهها با کمترین خطا از یک روند کاملا خطی تبعیت میکند (اگر با این مفهوم آشنا نیستید، پیشنهاد میکنم حتما از هوشمصنوعی یا دوستان مسلط به آمار در مورد آن بپرسید و ببینید چقدر ممکن است چنین چیزی در دادههای واقعی متاثر از رفتار مردم مشاهده شود.
۵) در واقع این نمودار نشان میدهد در طول ۱۷ روز، نرخ ثبتنام مردم در پویش جانفدا یک عدد کاملا ثابت بوده و اتفاقاتی نظیر تعطیلات نوروز، روزهای کاری یا پایان هفته، زمان اعلام آتشبس هیچ اثری روی آن نداشته است.
۶) اگر همین نرخ خطی ادامه مییافت، به زودی عدد ثبتنام از ۱۰۰ میلیون هم بالاتر میرفت. لذا احتمالا صلاح دیدهاند بعد از ۲۶ میلیون، ثبتنام با روند آهستهتری ادامه یابد.
فارسی
@Goftaniha این سایت که معلومه یه آمارسازی احمقانه و عوامفریبی هست.
نظر فنی: وقتی یه ریسورسی رو میخوای لود کنی (فرض کن ریسورس اینجا کامنت هست)، اگر فقط یک آیدی تو پیلود باشه، منطقیه که اون آیدی متعلق به ریسورس (کامنت) باشه.البته تیم فنی اینا انقدر احمقن که همینم ندونن. خوبه که ما بدونیم
فارسی

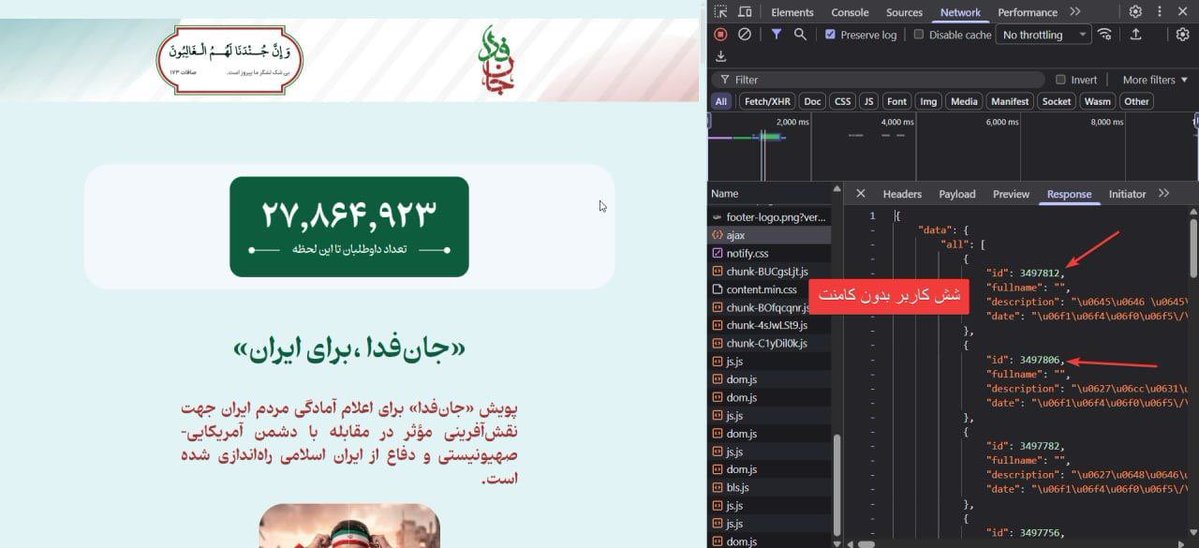
خبرگزاری سپاه پاسداران،فارس در جهت پوشاندن این گاف سنگین و دروغ بزرگ ۳۰ میلیونی حکومت تو قضیه پویش جانفدا، اومده گفته اون آیدیها تعداد کامنته، نه تعداد ثبتنام.
که خب طبق انتظار این داستان چرتوپرته، اگه اون آیدی مربوط به عدد کامنت بود، باید اعداد کامنتها متوالی بود نه اینکه یکهو عددش ۶ تا ۶ تا و ۲۰ تا ۲۰ تا تغییر کنه. حتی تو عکسی که خود این خبرگزاری هم منتشر کرده (عکس پایین)، این توالی اعداد حفظ نشده و فاصله چندعددی بین آیدی هر کامنت وجود داره که مشخص میکنه این آیدی، برای تعداد کامنتها نیست و مربوط به تعداد ثبتنامی هاست!
Amir Farshad EBRAHIMI@Goftaniha
دروغ پشت دروغ ! ۳۰ میلیون کجا و ۴میلیون کجا!!! جمهوری اسلامی معتقد است ۳۰ میلیون نفر در پویش «جانفدا» ثبت نام کردهاند و توی آمار سایت هم همین رو نشان داده ! اما واقعیت کمتر از ۴ میلیون نفر است. یک اشتباه ناشیانهی برنامهنویسی، این دروغ را که از پزشکیان تا تمام فرماندهان سپاه مدام تکرارش میکنند را آشکار کرد:
فارسی
@unclebobmartin I have learned a lot from you Uncle, especially in my early days of my career, which was almost a decade a ago. Thank you for your support. I was surprised when I saw this 🇮🇷 🧑🏽💻
English


@Goftaniha تو اصلا بگو ۳۰۰ میلیون. کاری داره واقعا یه شمارنده رو بزاری اونجا؟
ولی این اخبار رو پخش نکنید، این آیدی یوزر نیست و آیدی کامنت هست. اصلا هم به این معنی نیست ۳میلیون کامنت وجود داره چون این عدد لزوما میتونه از ۱ شروع نشه.
فارسی
دروغ پشت دروغ !
۳۰ میلیون کجا و ۴میلیون کجا!!!
جمهوری اسلامی معتقد است ۳۰ میلیون نفر در پویش «جانفدا» ثبت نام کردهاند و توی آمار سایت هم همین رو نشان داده !
اما واقعیت کمتر از ۴ میلیون نفر است.
یک اشتباه ناشیانهی برنامهنویسی، این دروغ را که از پزشکیان تا تمام فرماندهان سپاه مدام تکرارش میکنند را آشکار کرد:


فارسی
@SharifiZarchi ولی خب مشخصه همین کامنتها هم یه سری اسکریپت هست که اجرا شده و در زمان کوتاهی دیتا رو وارد کرده. فاصله زمانی کامنتها اینو میگه. بکند احتمالا پیاچپی هست. کار سختی نیست یهسری کامنت رندوم جنریت کردن.
فارسی
@SharifiZarchi بهنظر این آیدی کامنت هست و نه آیدی یوزر. منطقی نیست آیدی یوزر با کامنت بیاد. در اینکه اینا دارن آمارسازی میکنن شکی نیست ولی مهمه استدلالی که میشه از نظر فنی درست باشه.
فارسی
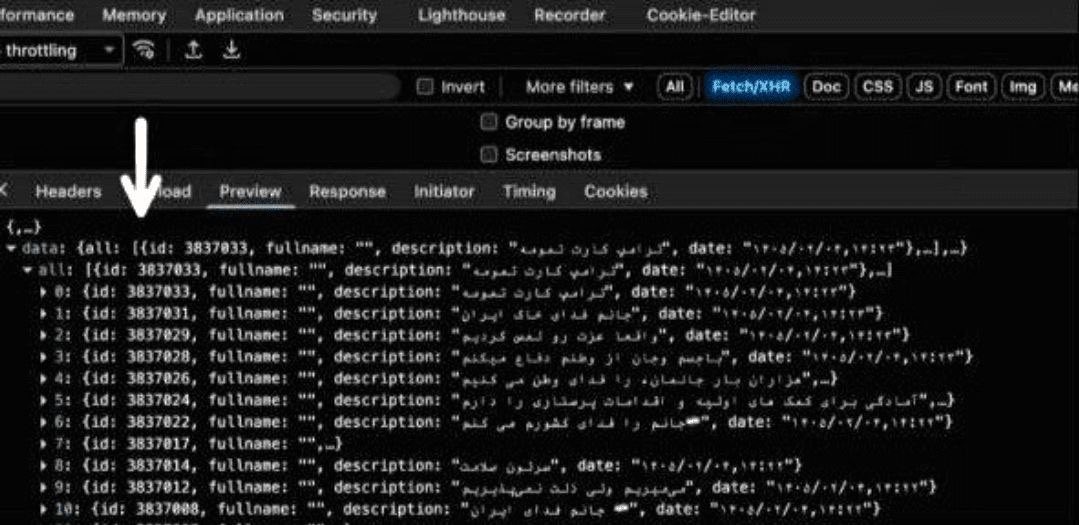
تعداد واقعی ثبتنامشدگان پویش «جانفدا» کمتر از ۴ میلیون نفر است. جمهوری اسلامی تلاش کرد طرفداران خود را بیش از ۳۰ میلیون نشان دهد. اما یک اشتباه ناشیانهی برنامهنویسی واقعیت را آشکار کرد: این سایت هنگام نمایش کامنتها، شناسهی کاربران را، که تماما اعداد زیر ۴ میلیون هستند، نشان میدهد. الگوی شناسهها و فواصل آنها و بررسی شناسههای جدید پس از ثبت یک کاربر جدید هیچ تردیدی باقی نمیگذارد که کل ثبتنامشدگان کمتر از ۴ میلیون نفر هستند.
برای راستیآزمایی کافی است دستور زیر را از ترمینال اجرا کنید:
curl -s 'janfadaa.ir/ajax' --data-raw 'action=getComments' | jq
فارسی
3hsan 🇮🇷 ری ٹویٹ کیا

Whether or not Europe stands with us, whether or not your journalists do their jobs, whether or not your politicians demonstrate the courage to act, I will fight for my people and my country.
English

بیایم با خودمون روراست باشیم!
شاه الان ایتالیا با بیزنسمنها جلسه داره! چند روز پیشم با غولهای بیگتک و سیلیکونولی! جلسه اقتصادی دیگه مرحله آخره! یعنی اینقدر مطمئنه!
پس ناامیدی بعضیا رو درک نمیکنم! مگه شاه نگفت به حاشیهها توجه نکنید؟! خب پس بزن هشتکو:
#KingRezaPahlavi
فارسی

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@Ramiiiiiiin2828 اتریش هم همینه. این متاسفانه میانگین انگیزه در جامعه رو پایین میاره. اگه خوش شانس باشی شاید بتونی یه محیط کاری متفاوتتر پیدا کنی که همه باانگیزه باشن، ولی متاسفانه حتی تو اون فضاها هم آدما بعد از یه مدت بیانگیزه میشن چون در اصل تغییری زیادی تو کیفیت زندگیشون نمیبینن.
فارسی

خیلیها از آلمان گلایه دارند. شاید این موضوع به سطح زبان آلمانی و میزان ادغام فرد با فرهنگ آلمان مربوط باشه. اما باید توجه داشت که آلمان یک کشور آزاد و دموکراتیک است که در زمانه امروز نباید دستکم گرفته شود. هزینهها و کیفیت زندگی آن هم بد نیست.
احتمالاً مشکل اصلی همه، مالیات👇
فارسی
@corbin_braun Are u telling me AI is taking care of all changes while maintaining 99.999 uptime? I am not talking about adding a log line but any change that modifies/introduces logic. Anyone who has worked in real engineering positions knows this is not possible now.
English

3hsan 🇮🇷 ری ٹویٹ کیا
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Daniel Hnyk@hnykda
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
@Gabbar0099 @grok This is a real video. There are two cuts. They have recorded this twice and then edited it. It’s just a bad edit! When you ask grok, it says so because it has no clue about the sudden cut!
English

Hey @grok is this video also made through AI?
Is there any doubt that this man is Netanyahu?
Say Yes or no, no explanations.
Benjamin Netanyahu - בנימין נתניהו@netanyahu
אומרים שאני מה? צפו >>
English

@elonmusk
Dear Elon,
In these critical days, the people of Iran need internet access. Please help them stay connected as they struggle to reclaim their country from the rule of the mullahs. Stand with the Iranian people. Iran will not forget its friends.
McNair, VA 🇺🇸 English
@RezaVaisi @elonmusk Look at this shit show in EU. NONE of them are from Iran 🇮🇷. They carry terrorist IR flag, their suggar daddy. They have been occupying Iran for 47 years but it’s over, soon .. ⏳
#KingRezaPahlavi #DigitalBlackOutIran
English
3hsan 🇮🇷 ری ٹویٹ کیا
از تمام هم میهنانم میخواهم این توییت پایین را خطاب به ایلان ماسک ریتوییت کنن. در تمام ۱۳ سالی که در توییتر بودهام این اولین بار است که چنین درخواستی دارم. هم میهنان ما در داخل کشور به دسترسی به اینترنت نیاز دارند.
Morad Vaisi@RezaVaisi
@elonmusk Dear Elon, In these critical days, the people of Iran need internet access. Please help them stay connected as they struggle to reclaim their country from the rule of the mullahs. Stand with the Iranian people. Iran will not forget its friends.
McNair, VA 🇺🇸 فارسی