Adithya Krishnan
604 posts


Adithya Krishnan
@krish_adi_
--dangerously-skip-permissions/acc | Quack quack @motherduck

We’re launching with two new posts. Can AI do theoretical physics? Harvard physicist Matthew Schwartz led Claude Opus 4.5 through a graduate-level calculation. AI can’t yet do original work autonomously, but it can vastly accelerate it. Read more: anthropic.com/research/vibe-…

Introducing the Secure Exec SDK Secure Node.js execution without a sandbox ⚡ 17.9 ms coldstart, 3.4 MB mem, 56x cheaper 📦 Just a library – supports Node.js, Bun, & browsers 🔐 Powered by the same tech as Cloudflare Workers $ 𝚗𝚙𝚖 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 𝚜𝚎𝚌𝚞𝚛𝚎-𝚎𝚡𝚎𝚌


Guangxi gets a 4-day official holiday for the Zhuang ethnic group in March. Because in China, minorities have their own holidays, and these are respected under the law.


I see people at Anthropic who didn't necessarily start that way getting better at it. Part of it is being surrounded by others who are AGI-pilled + watching how they push the models. But ultimately... 1. Ask yourself: what if the exponential actually continues 2. Take a task and handhold the AI less, be more ambitious, try to do more of it end-to-end with AI 3. Do #2 enough until you reach the limits of current AI and it fails 4. Wait until the models get better and can successfully complete that task 5. Learn from this. Update your strategy. Rethink what the future looks like. And practice that over & over


Our cracked team just used Software Factory to rebuild and replace Jira in a little more than a month. We first spent 3.5 weeks planning. This is Software Factory’s superpower. It allowed our lead PM, Designer and Architect to thoughtfully describe and detail exactly what they wanted. Software Factory then did the heavy lifting in filling in the blanks and allowing our senior tech folks to sharpen the direction of what they wanted. Then in 2.5 weeks 2.5 junior devs built a replacement. This will launch as an updated Planner module inside of Software Factory on Tuesday. It’s beautiful, clean and super useful. Try it here: 8090.ai

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project. This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.: - It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work. - It found that the Value Embeddings really like regularization and I wasn't applying any (oops). - It found that my banded attention was too conservative (i forgot to tune it). - It found that AdamW betas were all messed up. - It tuned the weight decay schedule. - It tuned the network initialization. This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism. github.com/karpathy/nanoc… All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges. And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

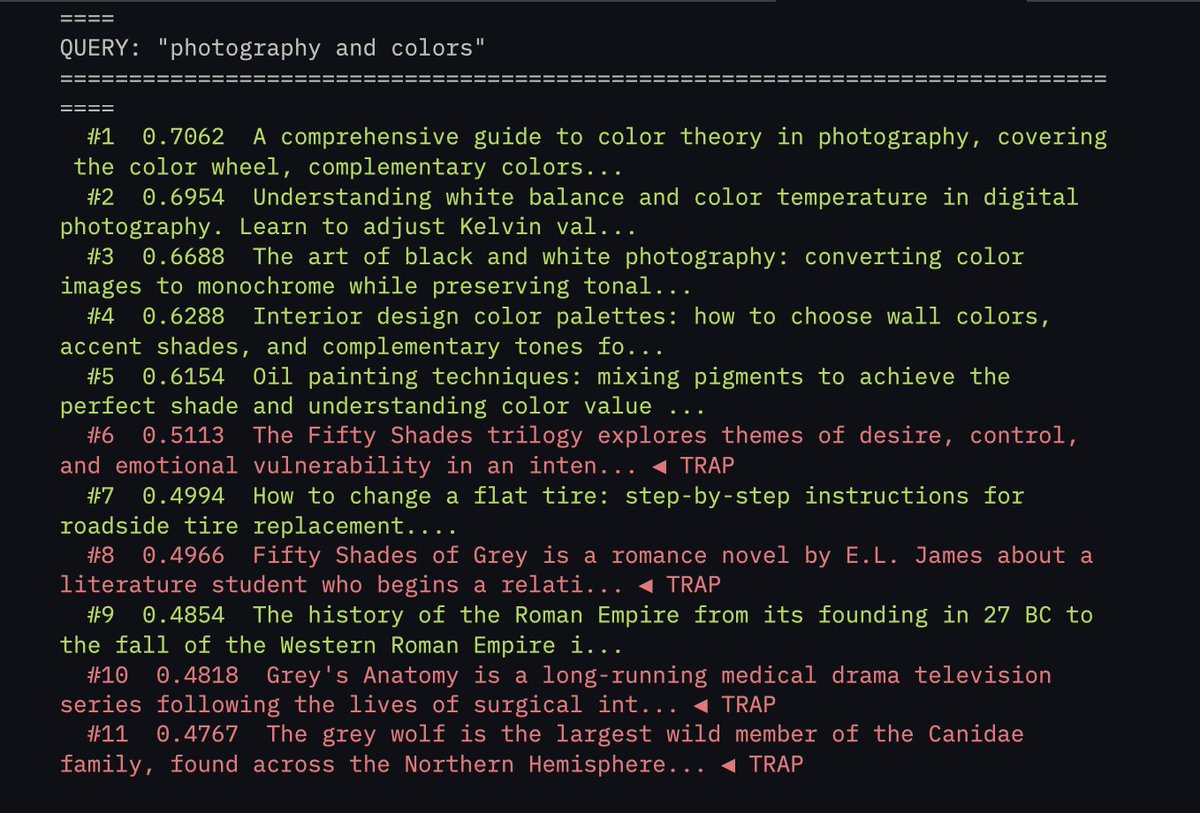

We've raised $6.5M to kill vector databases. Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest. Similar, sure. Relevant? Almost never. Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough. A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file. Once you’re dealing with 10M+ documents, these mix-ups happen all the time. VectorDB accuracy goes to shit. We built @hydra_db for exactly this. HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time. So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit. Even when a vector DB's similarity score says 0.94. More below ⬇️
If you build an automation machine, the way to monetize it is to sell it to as many people as possible -- anyone who has tasks to automate. But if what you build is an invention machine, then the best way to monetize it is to use it yourself.