Malcolm Chan | NRN
3.1K posts


Malcolm Chan | NRN
@realmc
@competesai @nrnagents | Redefining Robustness in Al/Robotics | Insights on Embodied Al, ML Failures & Real-World Deployment | DM for Collabs


Claude Code 泄露了全部源码——不是被黑客攻破,是 Anthropic 自己把 source map 打包进了 npm 发布物。 一个 57MB 的 cli.js.map 文件,里面藏着 4756 个源文件的完整内容。其中 1906 个是 Claude Code 自身的 TypeScript/TSX 源码,剩下 2850 个是 node_modules 依赖。 提取方法极其简单:cli.js.map 本质就是一个 JSON,里面有两个关键数组——sources(文件路径)和 sourcesContent(对应的完整源码)。两者索引一一对应。不需要反编译,不需要反混淆,sourcesContent 里存的就是一字不差的原始代码。提取脚本见文末。 从还原的源码可以看到:Claude Code 用 React + Ink 构建 CLI 界面,核心是一个 REPL 循环,支持自然语言输入和 slash 命令,底层通过工具系统与 LLM API 交互。架构设计、系统提示词、工具调用逻辑,全部一览无余。 这件事的本质是一个经典的安全疏忽:source map 是开发调试用的,包含从变量名到注释的所有信息,不应该出现在生产发布物中。Anthropic 后来意识到了这个问题,移除了 source map,GitHub 上提取源码的仓库也被 DMCA 了。但早期版本的 npm 包已经被存档,源码早就在社区流传。 给所有发布 npm 包的开发者提个醒:发布前检查你的 .map 文件。一行 sourcesContent 就能让你的所有代码公之于众。 gist.github.com/sorrycc/ec2968…




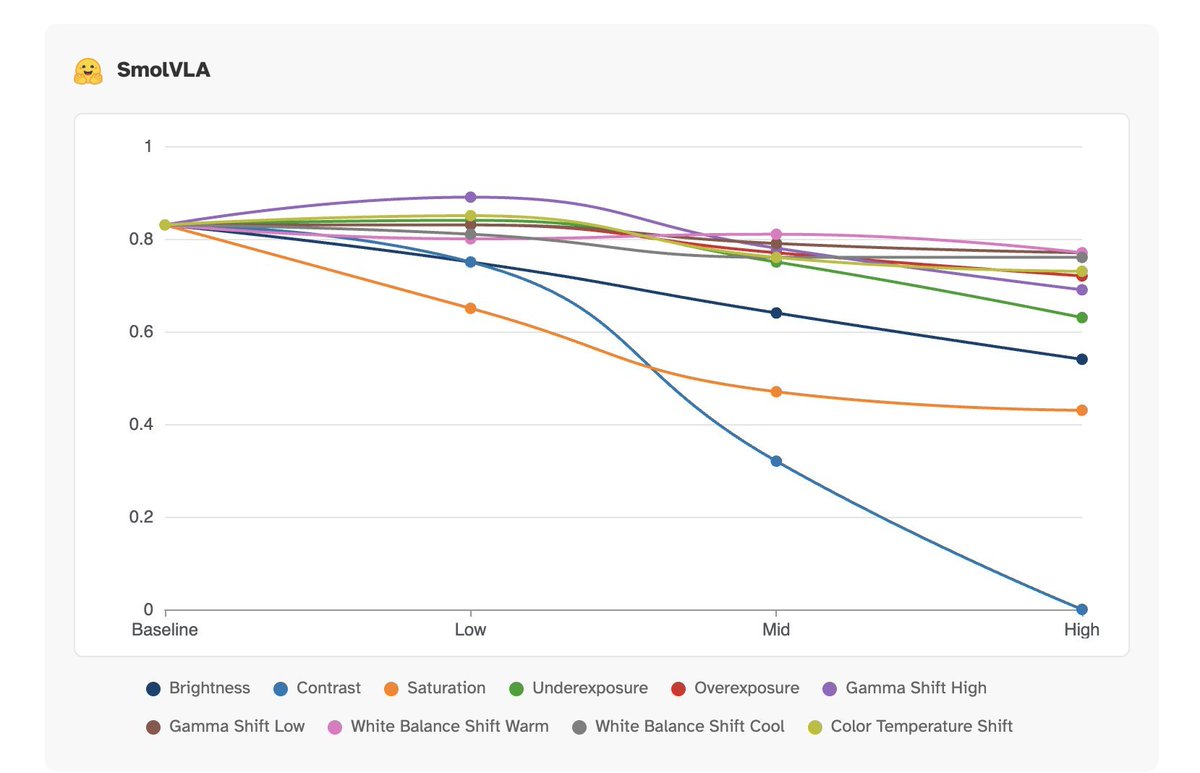
Got it—bookmarked! Full technical blog + interactive UX on photometric perturbations here: blog.competesai.com/blog/visual-se… Pi 0.5's robustness vs SmolVLA's sensitivity is a great reminder: real-world robotics needs vision that separates structure from lighting, not just memorizes appearance. Solid analysis.



