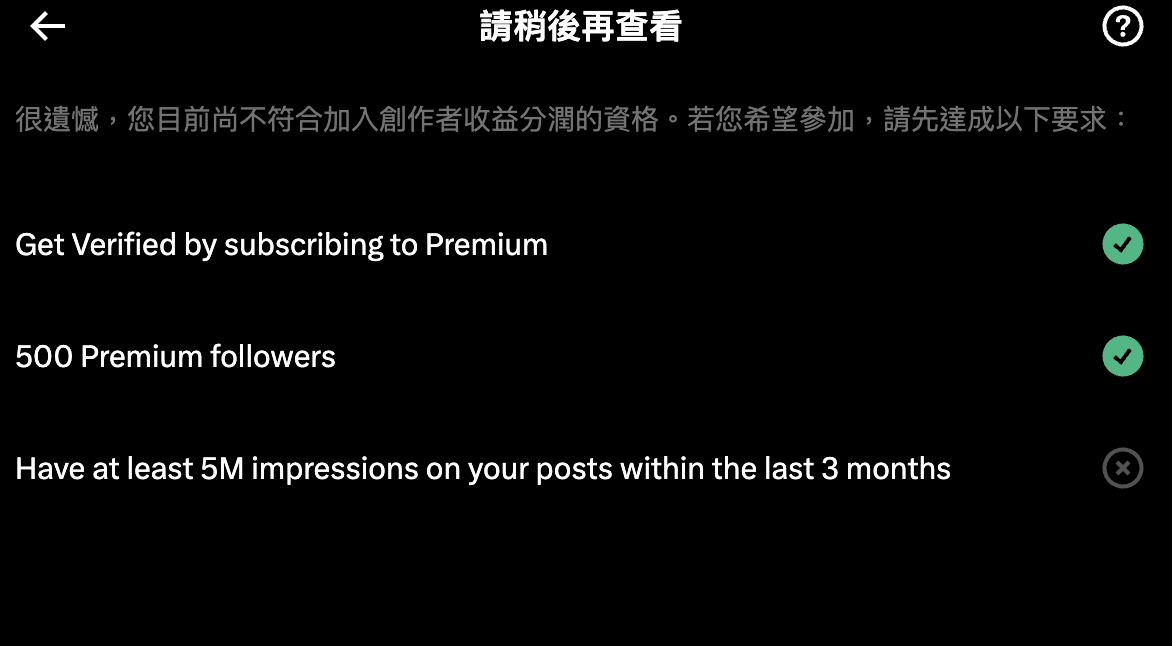
پن کیا گیا ٹویٹ

如果受制于没有自己的梯子的我有一个比较低成本的方法:
1.先去咸鱼买github student账号
2.白嫖student pack里面200刀的DigitalOcean或者其他的服务器
3.使用mack-a一键部署架设自己的梯子
x.com/vintcessun/sta…
恒星@vintcessun
中文
恒星
846 posts

【蓝V创作者福利群】已开! 蓝V朋友们,我建了个专属互关互动群! 不再是孤军奋战,一起抱团冲X平台创作者收益! ♦️高效互关、互评、互相转发、引用 ♦️真正抱团提升曝光&广告分成 ♦️如果有交易所或项目方合作,一起资源共享。 目标只有一个: 让大家一起拿到更多X官方收益! 想一起成长的朋友,点赞+转发+评论区粘贴这句话“互相转发和引用相关的推文是一个更有效增长的方式。” 同意你进群后我会发链接给你。 先到先得,群满即止! #蓝V互关 #X创作者收益 #Twitter变现 #推特涨粉


MỤC TIÊU "BẬT KIẾM TIỀN TRÊN X SAU 90 NGÀY" "BuildX ngày 17 - Hôm nay mình bận quá, với dành thời gian cho gia đình, nên chỉ reply được có 351 tin. - Chúc mọi người ngủ ngon nha