Sending out a deep dive to our subscribers early next week → #subscribe" target="_blank" rel="nofollow noopener">voratiq.com/#subscribe
English
voratiq
101 posts


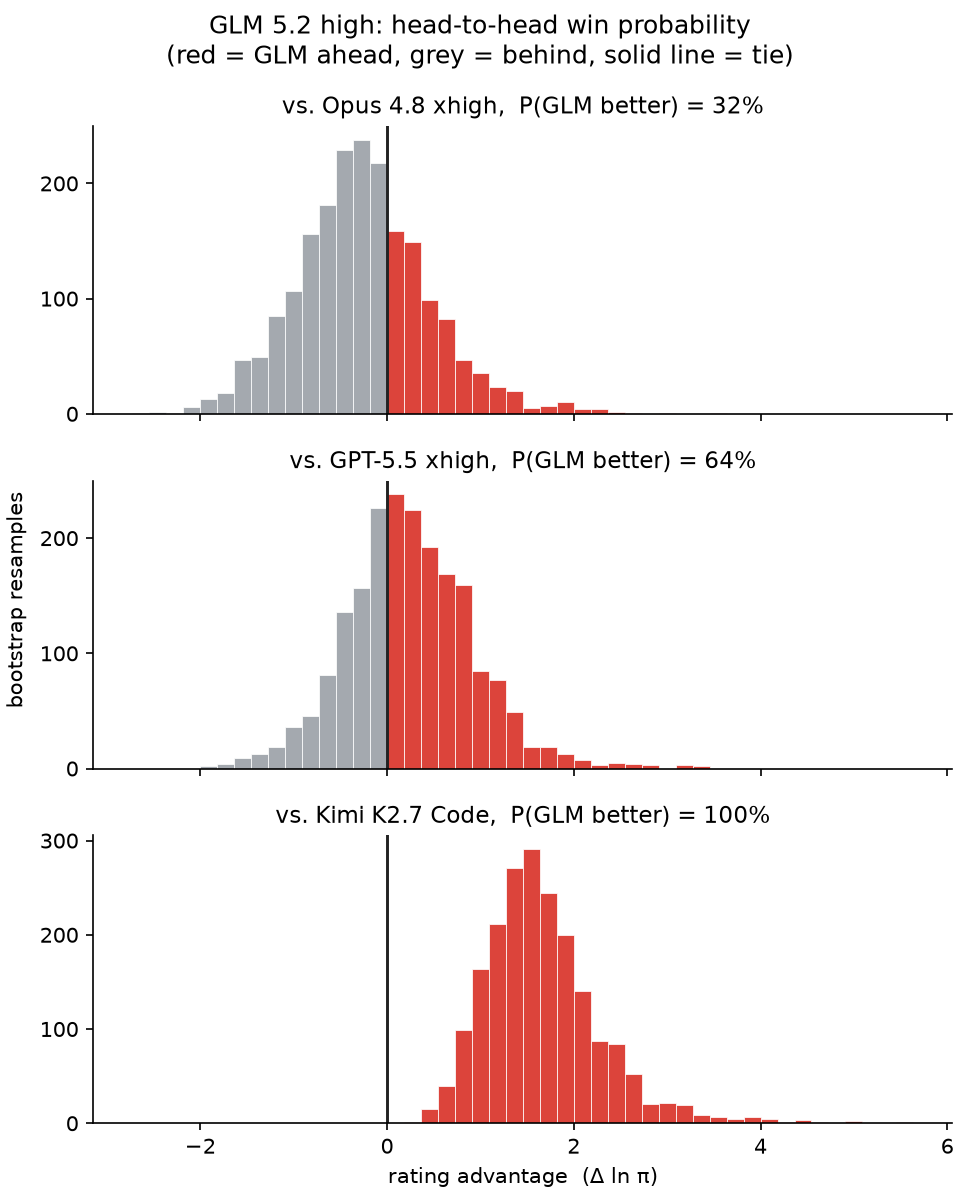
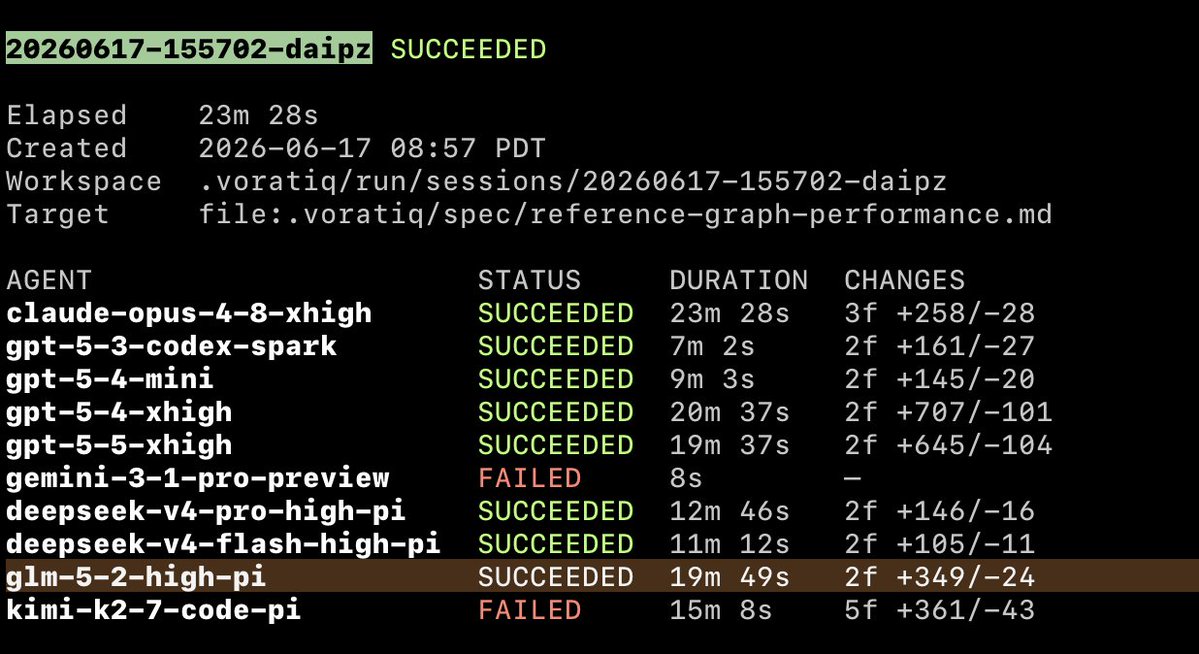
Leaderboard update! Opus 4.8 xhigh takes #1, a clear step over 4.7 - though its edge on GPT-5.5 xhigh is within noise For Qwen 3.6, the dense 27B strongly outperforms the 35B-A3B MoE - with a head-to-head edge of ~89%