xia0nan ری ٹویٹ کیا

Dogfooding Opus 4.7 the last few weeks, I've been feeling incredibly productive. Sharing a few tips to get more out of 4.7 🧵
English
xia0nan
47 posts


@xia0nan
Staff Data Scientist @ Agoda Working on #NLP, #CV applications in tech/travel/banking domain Ex-Wego, ex-OCBC AI lab NUS | Gatech GitHub @xia0nan












You now have $25/month of free API credits until the end of the year. If you have purchased credits already, you'll get the equivalent amount in additional free credits. x.ai/blog/api

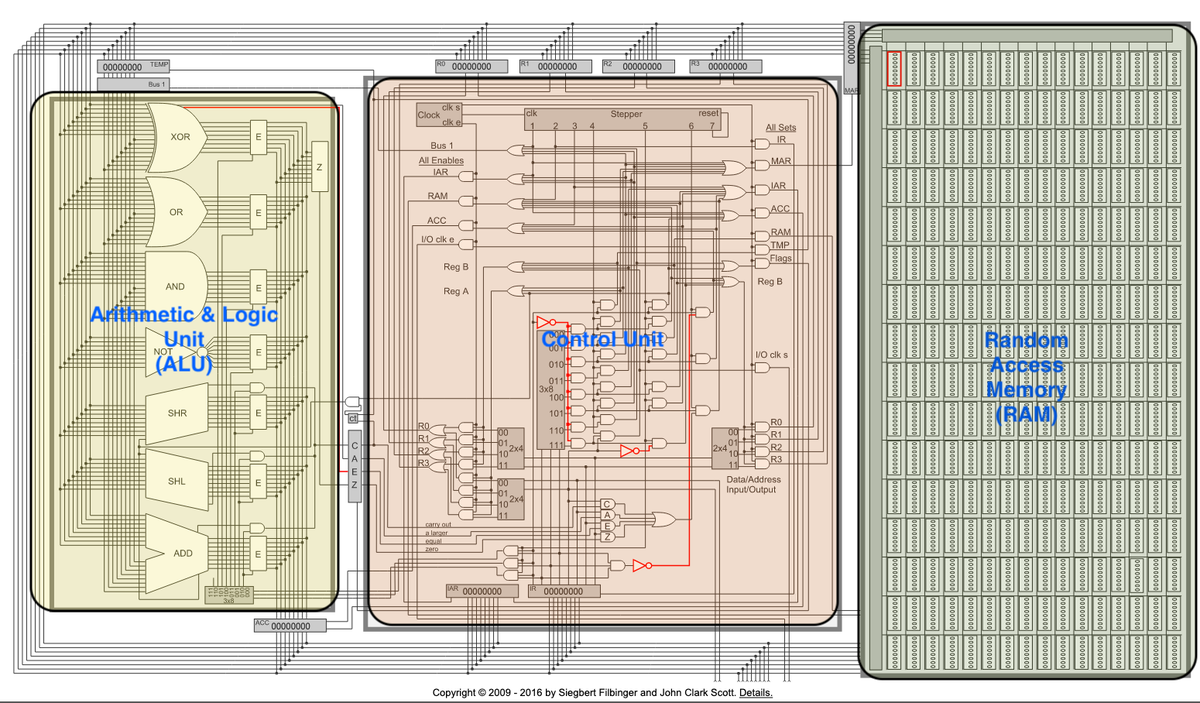
if you want to understand how computers work at the hardware level. I've seen the first video banger so far.
Very excited to release our second model, Mixtral 8x7B, an open weight mixture of experts model. Mixtral matches or outperforms Llama 2 70B and GPT3.5 on most benchmarks, and has the inference speed of a 12B dense model. It supports a context length of 32k tokens. (1/n)
