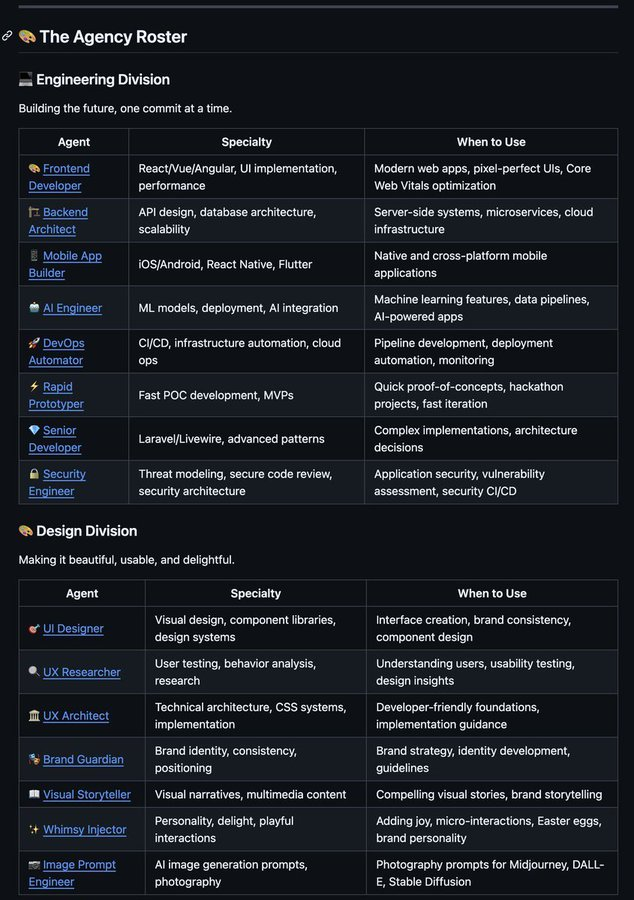
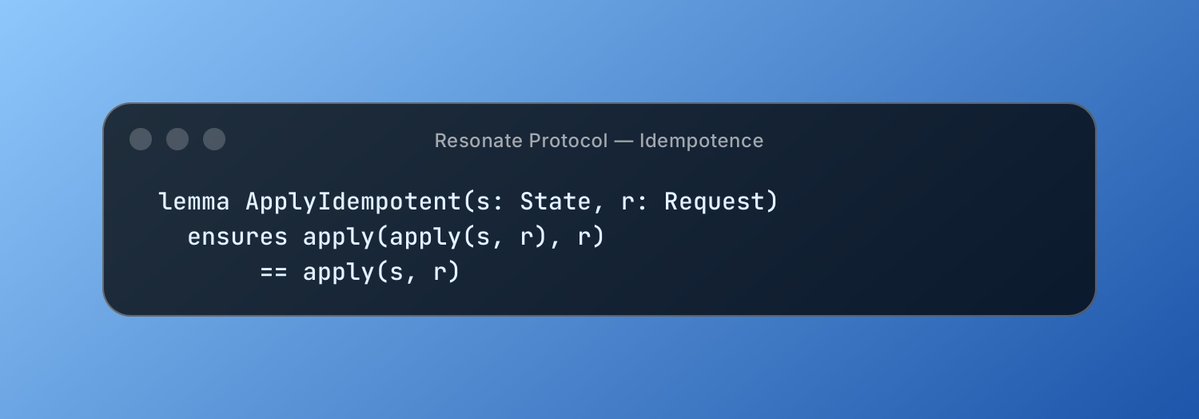
The modular/executable framing is the key shift. When skills are just text files, you get context injection. When they're executable units the agent can discover and invoke, you get composability. The agent can introspect which skills are available at runtime rather than having them all pre-loaded into context. Keeps the effective context window focused on what's actually needed for the current task.
English