
Mr.PE
470 posts

Mr.PE
@SENTOVA
Private Equity & Markets
NETHERLAND Tham gia Mart 2025
139 Đang theo dõi83 Người theo dõi

💰💰
How much money would it realistically take to solve most of your problems ?
Be honest
English


Dubai Habibis, coffee 10 am this Saturday in Business Bay?
Whose in?
English





Elon is right on the substance here.
OpenAI started as a California nonprofit (501(c)(3)). Musk’s early donations created an implied charitable trust under CA Corp. Code §§ 5230–5238 and Probate Code locked to the original open AGI for humanity’s benefit, not private profit.
Altman pivoting to for-profit, closing models, and doing massive Microsoft deals is a textbook breach of charitable trust + unjust enrichment.
Judge’s “you’re not a lawyer” was just procedural (witnesses can’t testify to legal conclusions).
Doesn’t kill the case; CA law still protects donor intent. “Stole from a charity” is blunt, Elon, but the core argument holds. Trial on
English

But is Elon Musk not accurate in suggesting that Altman stole from a charity by commandeering the non-profit, hollowing it out, and making money off of it using Elon’s charitable investment?
It shouldn’t take a lawyer to recognize the obvious.
New York Post@nypost
Judge in OpenAI trial has had it with Musk's 'steal from a charity' quip: 'You're not a lawyer' trib.al/iGktAfc
English
Lightning TTS finally fixed the mouth stupidly fast, natural voice in sub-100ms.
But the real missing piece for actual voice agents is the brain: persistent memory + evolving context.@hydra_db
It is exactly that knowledge layer.
Real-time, structured state so the agent remembers, doesn’t hallucinate history, and stays consistent without prompt bloat.
Lightning = lightning mouth
Hydra = working memory. This combo is the future. Game changer.
English

inside Smallest AI office, @kamath_sutra on what's the missing piece for voice agents!!
why Lightning TTS, ultra-low latency voice models needs @hydra_db the knowledge and context layer for AI Agents!!
English

The irony is unreal.
Musk is suing OpenAI while admitting on the stand that xAI partly used OpenAI models to train its own systems.
So OpenAI is apparently evil and illegitimate, but also useful enough to bootstrap his AI company?
You cannot call the ladder corrupt while climbing it.
English
#Forbes: @elonmusk ADMITS xAI distilled #OpenAI data!!
Bro, he said it in open court: every AI lab does this with public outputs. It’s called synthetic data, not “theft.”
Trying to smear the nonprofit betrayal lawsuit with a fake scandal? That’s not journalism, that’s billionaire cope fanfic
English

Elon Musk Admits xAI Distilled OpenAI Data To Train Models—Here’s What That Means
go.forbes.com/jdKyFg

English
#Forbes: @elonmusk ADMITS xAI distilled #OpenAI data!!
Bro, he said it in open court: every AI lab does this with public outputs. It’s called synthetic data, not “theft.”
Trying to smear the nonprofit betrayal lawsuit with a fake scandal? That’s not journalism, that’s billionaire cope fanfic. Stay mad
Forbes@Forbes
Elon Musk Admits xAI Distilled OpenAI Data To Train Models—Here’s What That Means go.forbes.com/jdKyFg
English
@elonmusk isn’t done just bc no single written contract.
#OpenAI launched as a CA nonprofit (501(c)(3)). Musk’s early donations created an implied charitable trust under California law (Corp. Code §§ 5230+ & Probate Code trust doctrines), locking in the original humanity-first, open AGI mission.
Case now turns on:
• Breach of Charitable Trust
• Unjust Enrichment (CA common law)Courts enforce donor intent via emails, mission docs & promises even without paper.
English
Musk admitted there was no written agreement or contract with OpenAI about the terms of his early donation.
So the entire “they betrayed the founding deal” argument basically comes down to vibes, memory, and billionaire regret.
He’s done.
English

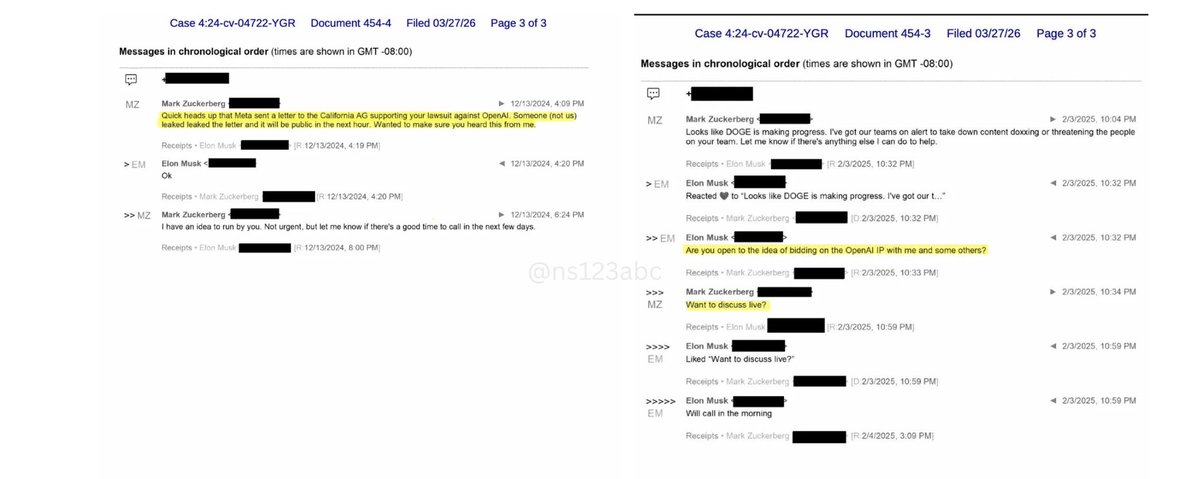
🚨 TEXTS BETWEEN MUSK AND ZUCKERBERG JUST SHOWN IN COURT
DECEMBER 13, 2024 Zuckerberg to Musk:
"Meta sent a letter to the California AG supporting your lawsuit against OpenAI."
FEBRUARY 3, 2025:
Zuckerberg: offers DOGE security help for Musk's team
Musk: ❤️
Musk: "Are you open to the idea of bidding on the OpenAI IP with me and some others?"
Zuckerberg: "Want to discuss live?"
Musk: "Will call in the morning"
Zuckerberg didn't join.
Seven days later, Musk's made the $97.4 billion bid for OpenAI alone.
Musk testified today under oath: he made the bid "to stop them from stealing the charity."
English
This looks like the euphoria phase, not healthy participation. Strong SIP culture is good long-term, but unquestioning, valuation-agnostic buying at these levels by inexperienced retail is how retail wealth gets transferred to smart money.
Nithin is right to be concerned. The question isn’t “where’s the money coming from?” It’s “who’s going to hold the bag when this reverses?”
English

Who are the people who continue to "buy the dip"? Where's all this money coming from?😬

English
US & China built full sovereign stacks for a reason. India cannot afford to remain a sophisticated user of foreign models while only controlling the pipes.
True self-reliance demands owning the entire chain: sovereign data, frontier training, model weights, infrastructure & governance.
Talent + scale are there. Choosing dependence is not pragmatism; it’s voluntary strategic surrender.
@NandanNilekani @AshwiniVaishnaw Time to correct course.
English

Nandan Nilekani’s article finely exposes his intellectual limitations in comprehending data and technology domain both, at strategic and tactical levels.
In a digital-first highly contested global order with shifting power centres, where data + AI and other emerging tech models are weapons for national security, intelligence edge, technological & predictive analytical prowess, economic growth & coercion, and overall geopolitical leverage over other nations, Mr. Nilekani advises against Indian sovereign data and AI model design and development.
Civilisational powers build true data and tech-led intelligence layers that shape centuries ahead rendering strategic advantage to their country; they don’t voluntarily choose subservience to foreign adversaries remaining dependent on foreign data and models that can be used against India as several cases would testify. Research the American and Chinese labs for starters!
True Indian self-reliance in this context requires owning the full stack: use cases, IP, data and tech design, infrastructure and code development, access & data sharing controls, frontier training, model weights, testing, evaluation, and analytics.
Alongside, regulatory, governance, information & data management end-to-end comprehensive frameworks and standards for India’s sovereign stack also a must-have.
Nandan Nilekani@NandanNilekani
India doesn't need to lead the world in building the most advanced AI models. But it must lead in ensuring benefits of AI are widely shared. @rvenk and I have an op-ed in The @EconomicTimes economictimes.indiatimes.com/opinion/et-com…
English
Respect @kiranshaw — bold vision, but technically we’re not there yet. India has ~40k GPUs (target 100k by Dec 2026) vs millions in the US/China.
Power grid can’t yet support the 6-13 GW AI demand by 2030. $1.2B IndiaAI Mission vs hundreds of billions in US capex. No major Indian frontier models; top talent still builds abroad.
Fixes: 500k+ sovereign GPUs + indigenous chips, 10 GW+ dedicated AI power, $10B+ sovereign fund, reverse brain drain via labs & incentives, faster approvals.
Talent + UPI-scale infra can win applied AI — if we close the stack gap now. @AshwiniVaishnaw @nasscom Priority?
English

Mark my words: What Chinese tech & AI cos did to disrupt the digital tech world over the last decade, Indian tech & AI cos will do over the next decade to disrupt and deploy at scale @AshwiniVaishnaw @nasscom @nasscomstartups @able_indiabio @BIRAC_2012 @rajesh_gokhale Indian AI & tech talent makes this aspiration possible @sundarpichai @satyanadella @elonmusk @nikhilkamathcio
English