Tweet ghim
Shreyansh
1K posts


Shreyansh
@imbearguy
I like fighting hallucinations, too much coffee and football. AI Engineer, working on evals
Mumbai, India Tham gia Ocak 2022
190 Đang theo dõi128 Người theo dõi

Shreyansh đã retweet

Kimi K2.6 is the only thing at this point that’s stopping frontier companies from raising their prices. they’ve earned respect.
Kimi.ai@Kimi_Moonshot
Kimi K2.6 is now ranked #1 on OpenRouter's programming leaderboard.
English
Shreyansh đã retweet

We spent millions building a wildly capable, human-like non-deterministic AI, and are now spending millions more trying to wrap it in guardrails and making it predictable and deterministic. Absolute cinema.
English

Ayy Bois. Career update soon. This shit is not a drill.
And yes, I am in IIT-B rn to finalize the offer.
Mode details incoming soon enough.
🫡🫡
Mumbai, India 🇮🇳 English
@VazeKshitij Haha, last year for some event there, I reached 2 hours before, just to see the campus (and meet some ppl)
English
Btw - this is going to be me tomorrow at IIT-B.

Pune, India 🇮🇳 English
@TheAhmadOsman Did you see the dwarkesh interview with Jensen huang?
Whose words made more sense to you?
Just curious coz from what I could understand, dwarkesh made pretty good points about generalizing ai but with odd references.
I think u r the right person to ask this question
English

Let me make local AI easy for you
Inference setup & optimization are simple now
across pretty much any Inference Engine
Just have an agent run evals overnight
sweep a few quants per GPU / inference stack
and generate bash scripts with best configs
Wake up to tuned performance
English
@arpit_bhayani I feel good from the first sentence. Second is auto applied so no worries
English
It is okay not to make friends, but certainly do not make enemies. You never know where the person sitting next to you will be 20 years from now. The world is small, and it gets even smaller at the top.
English
@akshay_pachaar This is actually an art, always so excited to see breakdowns like this in simple words
English

Microsoft just mass-compressed LLM reasoning.
their new paper introduces MEMENTO, a method that teaches reasoning models to manage their own context.
instead of letting chain-of-thought grow into a flat 32K-token stream, the model learns to segment its reasoning into blocks, compress each into a dense summary (a "memento"), and mask the original block from future attention.
the result is a sawtooth KV cache pattern where memory periodically drops instead of growing monotonically.
training is a two-stage SFT recipe.
stage 1: learn the block-memento format with full attention.
stage 2: learn to reason with masked blocks. each block gets compressed 5-20x, and peak KV cache drops by 2-2.5x across model families.
but the most surprising finding is the "dual information stream."
when a memento is generated, the model can still see the full reasoning block. so the memento's KV entries get computed with full block context.
after the block is masked, those KV entries stay. they carry implicit information that the memento text alone doesn't capture.
recomputing memento KVs without block context drops accuracy by 15 percentage points. same text, different KV representations, significantly worse performance.
this is what separates MEMENTO from prior work that rebuilds context from text alone and loses this implicit channel.
they also showed the accuracy gap is a consistency problem, not a capability problem. the model can still solve the same problems, just less reliably. majority voting at k=3 recovers base accuracy, and RL closes most of the remaining gap.
as reasoning traces get longer, models that compress their own intermediate state will serve more users on the same hardware. and the dual KV channel suggests in-place masking is fundamentally better than restart-based approaches.
paper and dataset (228K traces) are public. link in the next tweet

English


Seeing rumors that Claude Opus 4.6 got nerfed.
Usually this boils down to 3 cases:
- Unintentional. For example, a regression caused by changes in the inference stack or Claude Code. This is what evals are for before rolling out.
- Intentional “optimizations” (quantization, reduced reasoning). If so, say it. If users pay for a model, they should get that model.
- User psychology. The more you use a model, the dumber it feels.
English


I am such an idiot
ultrathink ultraplan fix opus, no mistakes
ThePrimeagen@ThePrimeagen
I think I could help Anthropic Mythos fix opus, no mistakes
English
@TheAhmadOsman you gave a 101 for LLMs that i love and follow
can you give a 101 for LLM infra?
English
@ayushunleashed whoever that arsenal fan is, i want to be friends with you
English

Priyam always coming up with fun ideas. What a night man.



Priyam Raj@priymrj
Me and my friends are dressing up very early 2000s tonight in Indiranagar, think layered tshirts, wired earphones, keypad phones, who wants to join?
English
This is all going so meta with Claude code.
I am using Claude to write a skill, then using claude to write evals for that skill, then claude is running subagents, providing skills to some agents while not to others to evaulate these agents on the evals ( test cases ), then noting down token usage and other stuff to evaluate weaknesses of the skill.
Claudeception.
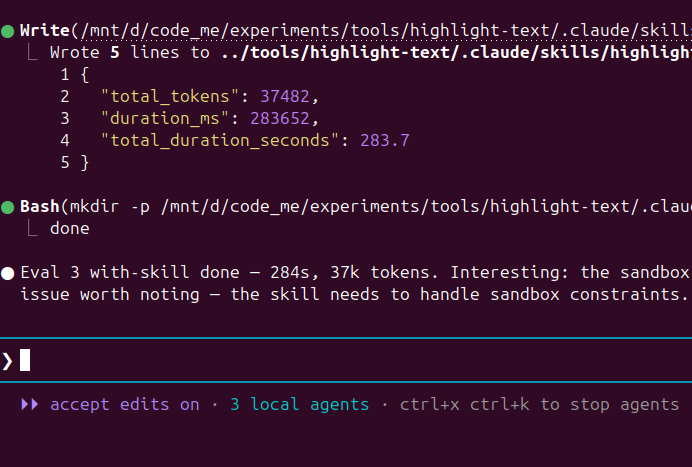
English
Any good content recommendations for building evals for long running Agents?
English
I questioned knowledge and saw that everything is somewhat biased, but some ideas still match reality better than others
Finally, I realized even though I have values and think for myself, those same values can sometimes bias or distort how I see things
Sasuke moment
English
I started by feeling life is unfair.. seeing some ppl earn easily while others grind
Then I thought maybe some elite powerful ppl control what gets value and attention (manipulation), but I also realized it’s not fully controlled, just influenced (less facts to prove).
...contd
English
@ayushunleashed I'm seeing similar glitches, going till attempt 4 but no response.
English
Horrible experience with claude today.
First sonnet 4.6 is hallucinating like it's GPT 3.5.
Even when I tell it to do X, it reverts back to Y.
Second, Are the rate limits decreased? A normal conversation hit the rate limit so fast.

English
Ladies and Gentlemen
Boys and Girls
Lads and Lasses
Today, since it's the end of the financial year, our increments were announced.
If you didn't know, I work as a firmware engineer at an Industrial IoT company. I am from a tier-3 college, an electronics engineer, who works in a core company.
25% IT IS Y'ALL!!!! We are EXTREMELY close to the 7-figure mark. Lol, count in the twitter payout, and we are well past that too.
I don't know what to say, I am still kinda processing it all.
Unreal.
Simply lovely.
English