Tweet ghim

For your pandemic Friday viewing enjoyment. 'kubectl run -it --rm --image=ghcr.io/pdevine/thisis… tif' or for the docker inclined 'docker run -it --rm ghcr.io/pdevine/thisis…'
English
Patrick Devine
1.4K posts
@pdev110
Software Guy @ Ollama
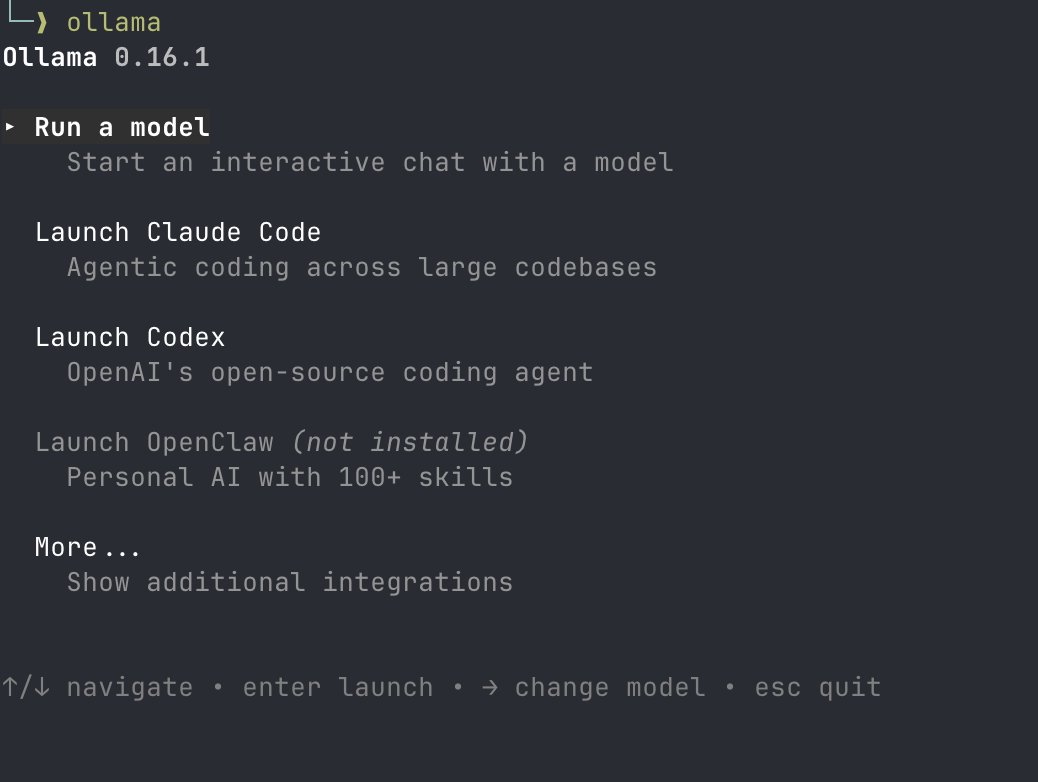
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework. This change unlocks much faster performance to accelerate demanding work on macOS: - Personal assistants like OpenClaw - Coding agents like Claude Code, OpenCode, or Codex


Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework. This change unlocks much faster performance to accelerate demanding work on macOS: - Personal assistants like OpenClaw - Coding agents like Claude Code, OpenCode, or Codex





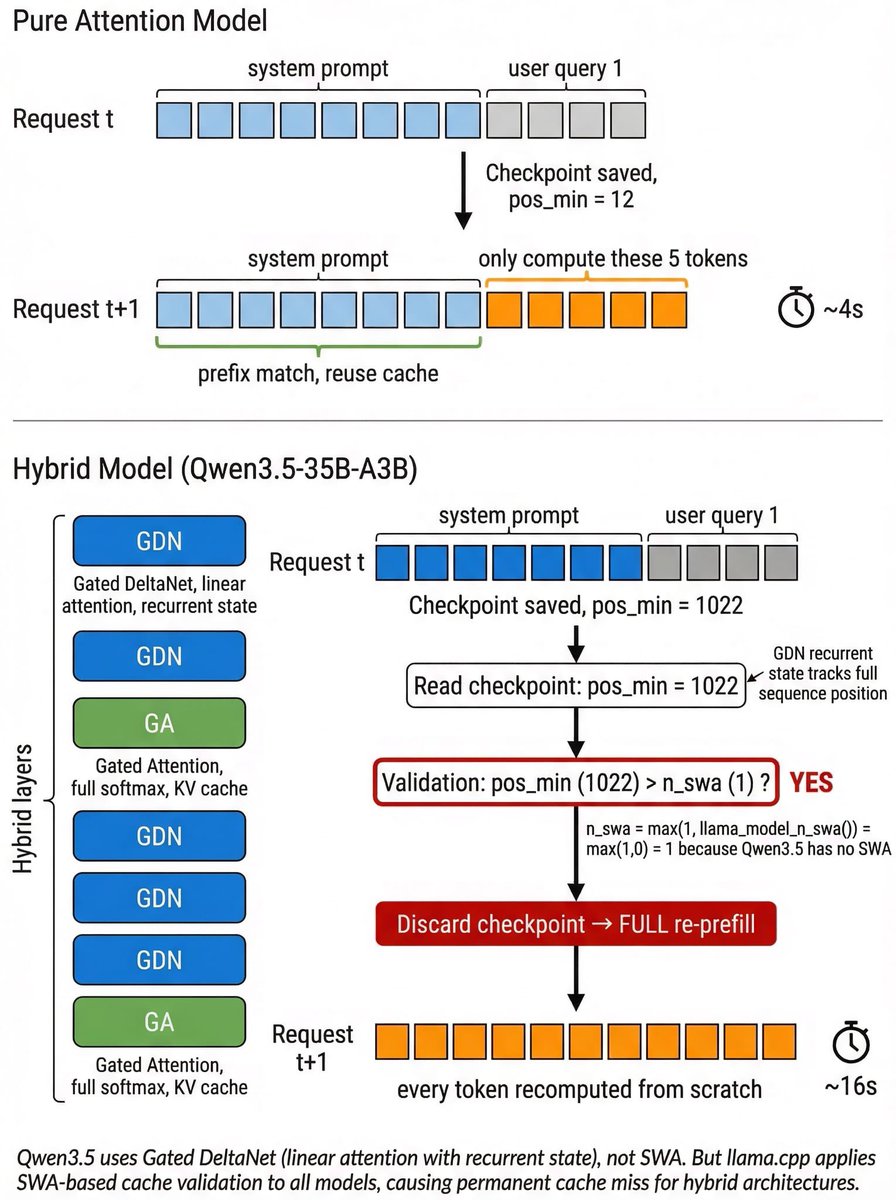


❤️ We are partnering with @MiniMax_AI to give Ollama users free usage of MiniMax M2.5 for the next couple of days! ollama run minimax-m2.5:cloud Use MiniMax M2.5 with OpenCode, Claude Code, Codex, OpenClaw via ollama launch! OpenCode: ollama launch opencode --model minimax-m2.5:cloud Claude: ollama launch claude --model minimax-m2.5:cloud