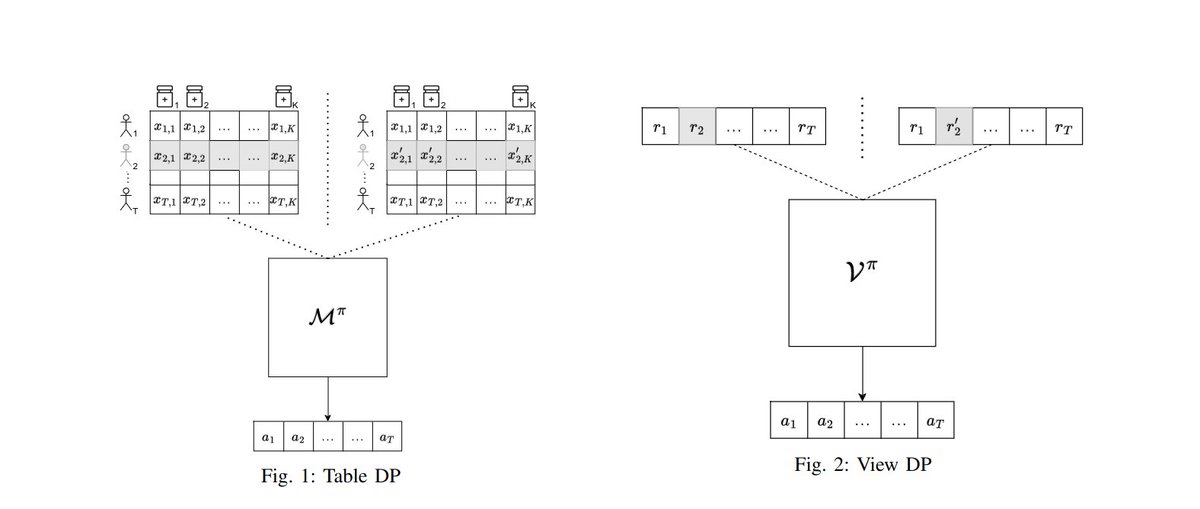
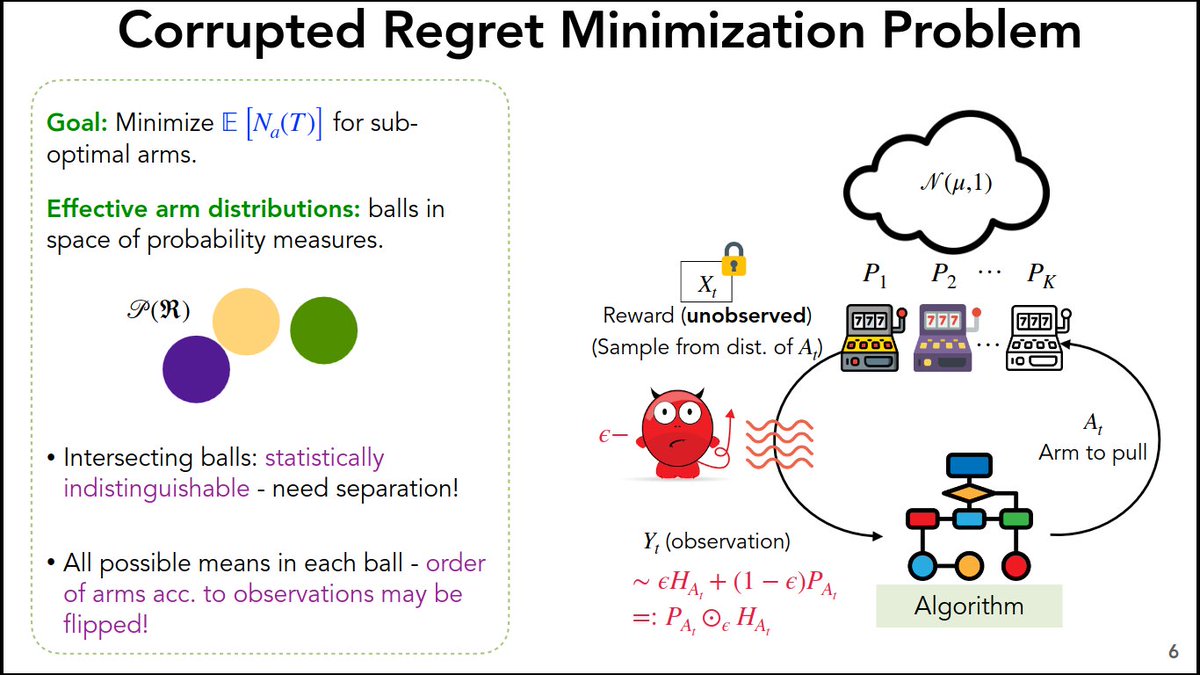
4/n Alena, Thomas, Phillipe & Bruno motivated by uniqueness ambiguity of value func as a solution to HJB eqn in CTRL, propose to approximate the value func by training a PINN through a specific scheduling iterative process that constraints it to converge to the viscosity solution

English