
Naoto Nakai
71.2K posts

プライムビデオ、ウォーゲーム観てる。彼女が初めて彼の部屋に入った時に手に取ったのは学研の電子ブロック!この映画は何回も観たけど気が付かなかったな
日本語
Naoto Nakai 已转推

We are back. After one year of quiet building.
Introducing GENE-26.5, our first robotic brain that takes a major step toward human-level capability.
For years, robotics has struggled to learn from the world’s largest and valuable data source: Humans.
Solving it means rethinking the whole stack from the ground up:
- A robotics-native foundation model.
- A 1:1 human-like robotic hand.
- A noninvasive data collection glove for motion, force, and touch.
- A simulator that turns weeks of experiments into minutes.
GENE-26.5 is trained across language, vision, proprioception, tactile, and action. We designed a set of tasks to test how far we can go with this new paradigm.
Fully autonomous, 1x speed, one model, same weights. (Enjoy with sound on)
We are approaching the endgame for robotics.
And this is just a beginning.
English
sudo nvidia-smi -pl 300 で450W->300Wにしても66.49tok/secで殆ど変化せず。夏はこれだな…
Naoto Nakai@NuCode
Qwen3.6のMoEモデル(Qwen3.6-35B-A3B Q4_K_M GGUF)も基本的には同じセッティング "Number of layers for which to force MoE layers into CPU" を12に減らしてやるとフルコンテキストで67tok/secぐらい出る(RTX4090)
日本語
Naoto Nakai 已转推

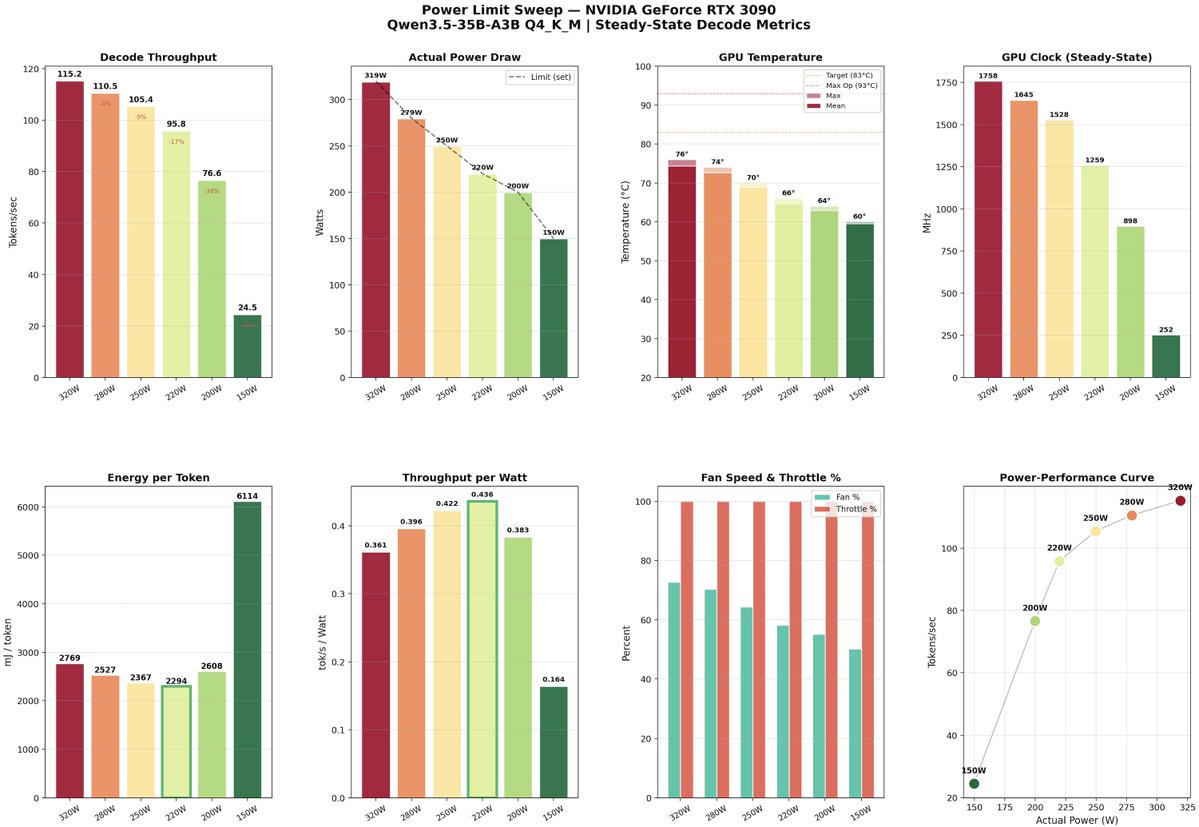
A few weeks ago, with @davideciffa, we experimented around power capping our 3090s.
And we discovered a sweet spot at 220W where you can get ~92% of max throughput at ~58% of the power.
Qwen3.5-35B-A3B Q4_K_M on a single RTX 3090:
• 320W: 115.2 tok/s, 0.381 tok/s/W, 76°C
• 220W: 105.4 tok/s, 0.436 tok/s/W, 64°C
• 200W: 95.8 tok/s, 0.438 tok/s/W, 60°C
10% throughput loss for 40% less power.
Fans basically silent.
We think this is a no-brainer. Lower bill, lower temps (particularly important in the upcoming summer), longer GPU life.
English
比較用
ollama run gemma4:31b-mlx-bf16
7.25 tokens/s(M5Max)
Naoto Nakai@NuCode
ollama run gemma4:31b-coding-mtp-bf16 gemma4 MPTお試し 12.45tok/sec、うーんbf16の割には速いのかな…
Eesti
ollama run qwen3.6:35b-a3b-coding-nvfp4
114.81 tokens/s(M5Max)
ollama早くなってない?
日本語
ollama run gemma4:31b-coding-mtp-bf16
gemma4 MPTお試し 12.45tok/sec、うーんbf16の割には速いのかな…
日本語
オブジェクト◉のコピーは右クリックでドラッグ。iPhoneなどタッチ環境ではステージをタッチしながら他の指でオブジェクトをドラッグすると子オブジェクトごと複製
日本語