置顶推文

Raphi-2Code
11.9K posts




Gemini 3.1 pro in Gemini App vs Gemini 3.1 Pro in Google AI Studio same prompt




ChatGPT/1.2026.076 (Android) adds an announcement that "Video in ChatGPT is here" - "Transform text and image into video with dialogue, soundtrack, and style."

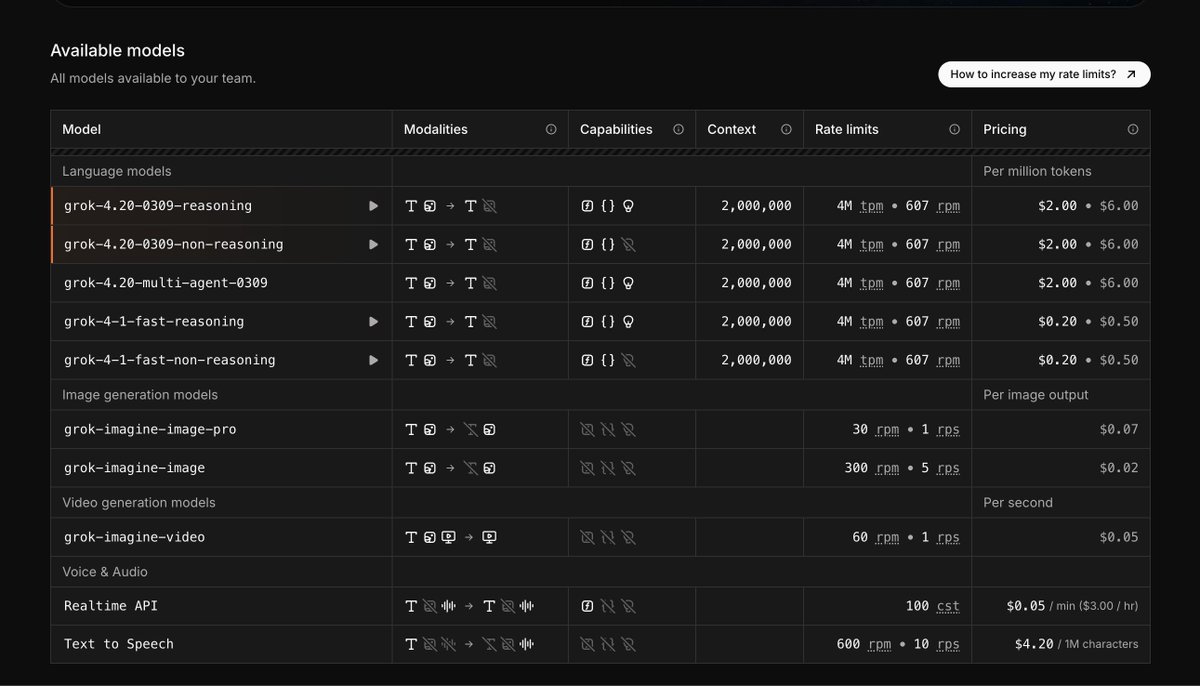
Mistral has released Mistral Small 4, an open weights model with hybrid reasoning and image input, scoring 27 on the Artificial Analysis Intelligence Index @MistralAI's Small 4 is a 119B mixture-of-experts model with 6.5B active parameters per token, supporting both reasoning and non-reasoning modes. In reasoning mode, Mistral Small 4 scores 27 on the Artificial Analysis Intelligence Index, a 12-point improvement from Small 3.2 (15) and now among the most intelligent models Mistral has released, surpassing Mistral Large 3 (23) and matching the proprietary Magistral Medium 1.2 (27). However, it lags open weights peers with similar total parameter counts such as gpt-oss-120B (high, 33), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 36), and Qwen3.5 122B A10B (Reasoning, 42). Key takeaways: ➤ Reasoning and non-reasoning modes in a single model: Mistral Small 4 supports configurable hybrid reasoning with reasoning and non-reasoning modes, rather than the separate reasoning variants Mistral has released previously with their Magistral models. In reasoning mode, the model scores 27 on the Artificial Analysis Intelligence Index. In non-reasoning mode, the model scores 19, a 4-point improvement from its predecessor Mistral Small 3.2 (15) ➤ More token efficient than peers of similar size: At ~52M output tokens, Mistral Small 4 (Reasoning) uses fewer tokens to run the Artificial Analysis Intelligence Index compared to reasoning models such as gpt-oss-120B (high, ~78M), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, ~110M), and Qwen3.5 122B A10B (Reasoning, ~91M). In non-reasoning mode, the model uses ~4M output tokens ➤ Native support for image input: Mistral Small 4 is a multimodal model, accepting image input as well as text. On our multimodal evaluation, MMMU-Pro, Mistral Small 4 (Reasoning) scores 57%, ahead of Mistral Large 3 (56%) but behind Qwen3.5 122B A10B (Reasoning, 75%). Neither gpt-oss-120B nor NVIDIA Nemotron 3 Super 120B A12B support image input. All models support text output only ➤ Improvement in real-world agentic tasks: Mistral Small 4 scores an Elo of 871 on GDPval-AA, our evaluation based on OpenAI's GDPval dataset that tests models on real-world tasks across 44 occupations and 9 major industries, with models producing deliverables such as documents, spreadsheets, and diagrams in an agentic loop. This is more than double the Elo of Small 3.2 (339) and close to Mistral Large 3 (880), but behind gpt-oss-120B (high, 962), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 1021), and Qwen3.5 122B A10B (Reasoning, 1130) ➤ Lower hallucination rate than peer models of similar size: Mistral Small 4 scores -30 on AA-Omniscience, our evaluation of knowledge reliability and hallucination, where scores range from -100 to 100 (higher is better) and a negative score indicates more incorrect than correct answers. Mistral Small 4 scores ahead of gpt-oss-120B (high, -50), Qwen3.5 122B A10B (Reasoning, -40), and NVIDIA Nemotron 3 Super 120B A12B (Reasoning, -42) Key model details: ➤ Context window: 256K tokens (up from 128K on Small 3.2) ➤ Pricing: $0.15/$0.6 per 1M input/output tokens ➤ Availability: Mistral first-party API only. At native FP8 precision, Mistral Small 4's 119B parameters require ~119GB to self-host the weights (more than the 80GB of HBM3 memory on a single NVIDIA H100) ➤ Modality: Image and text input with text output only ➤ Licensing: Apache 2.0 license

I can't believe GPT-5.4 is just a bit over 2 weeks old

have you said thank you to Grok yet? voice mode now live on X for Android and web

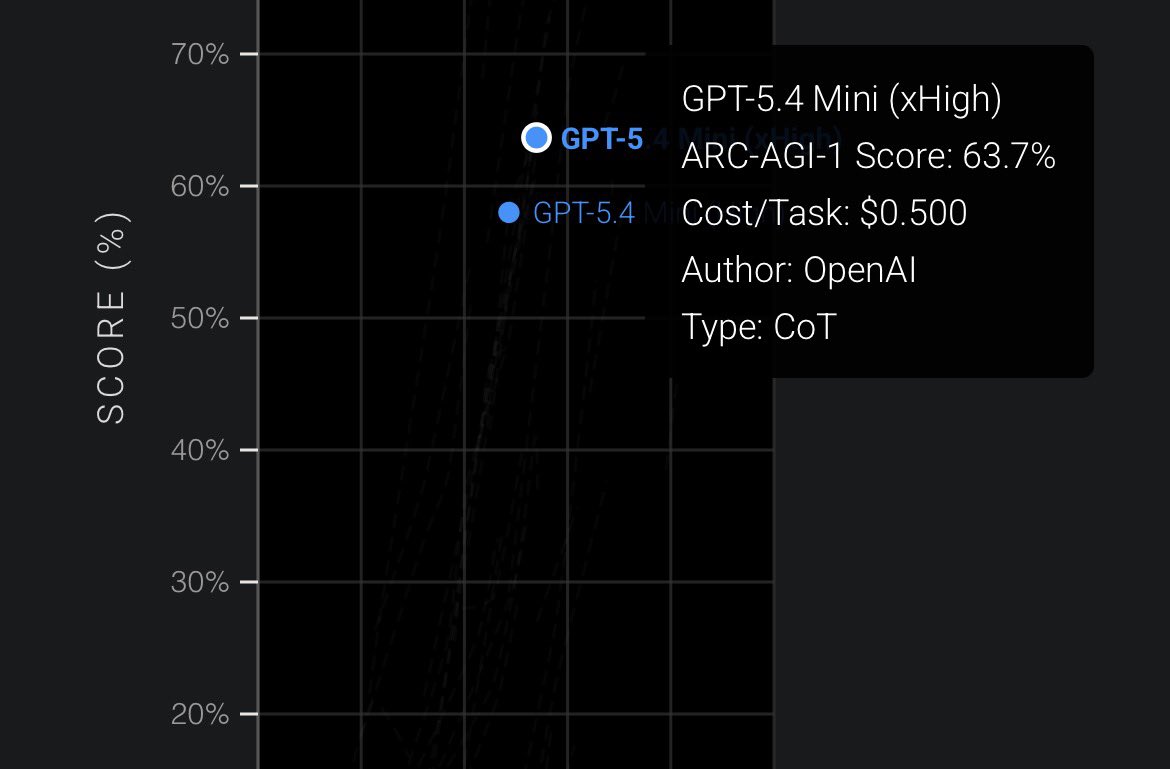
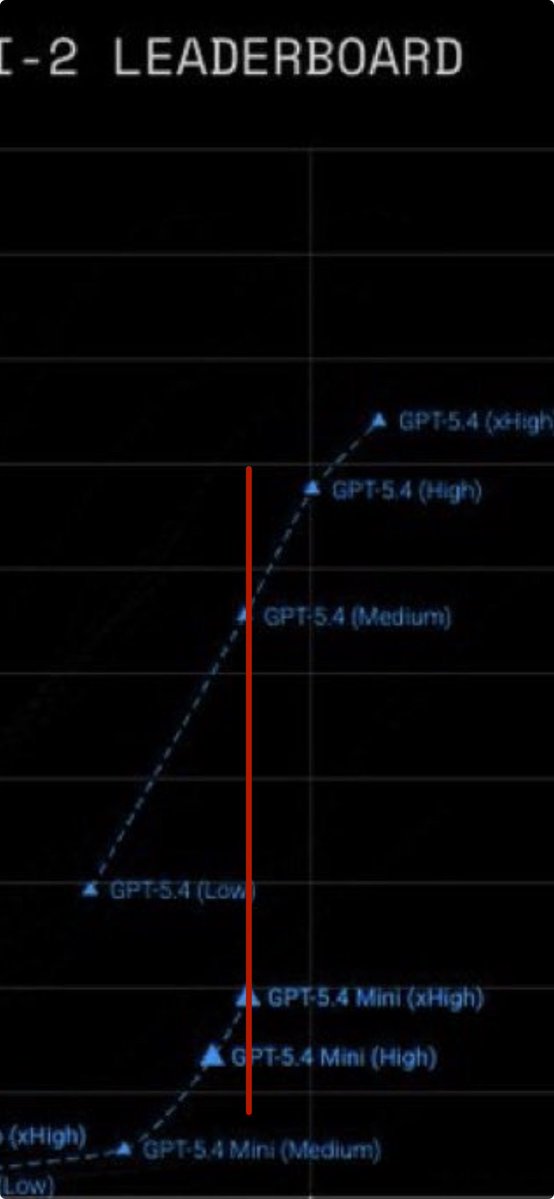
GPT-5.4 Mini/Nano on ARC-AGI 2 GPT-5.4 Mini: - xHigh: 19%, - High: 13%, - Med: 4%, - Low: 1%, GPT-5.4 Mini is 3× cheaper per token, but used 3× more reasoning tokens, and preformed 3x worse than GPT 5.4 high