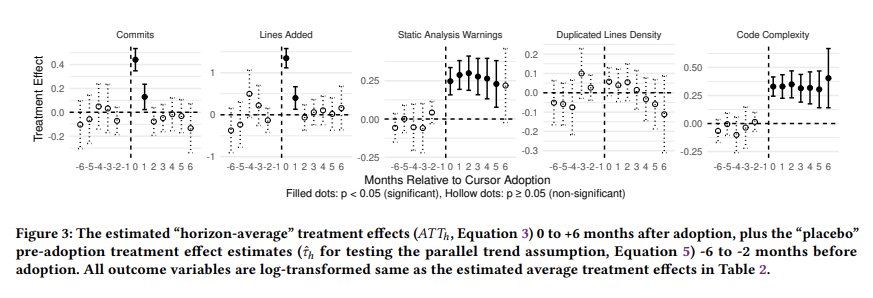
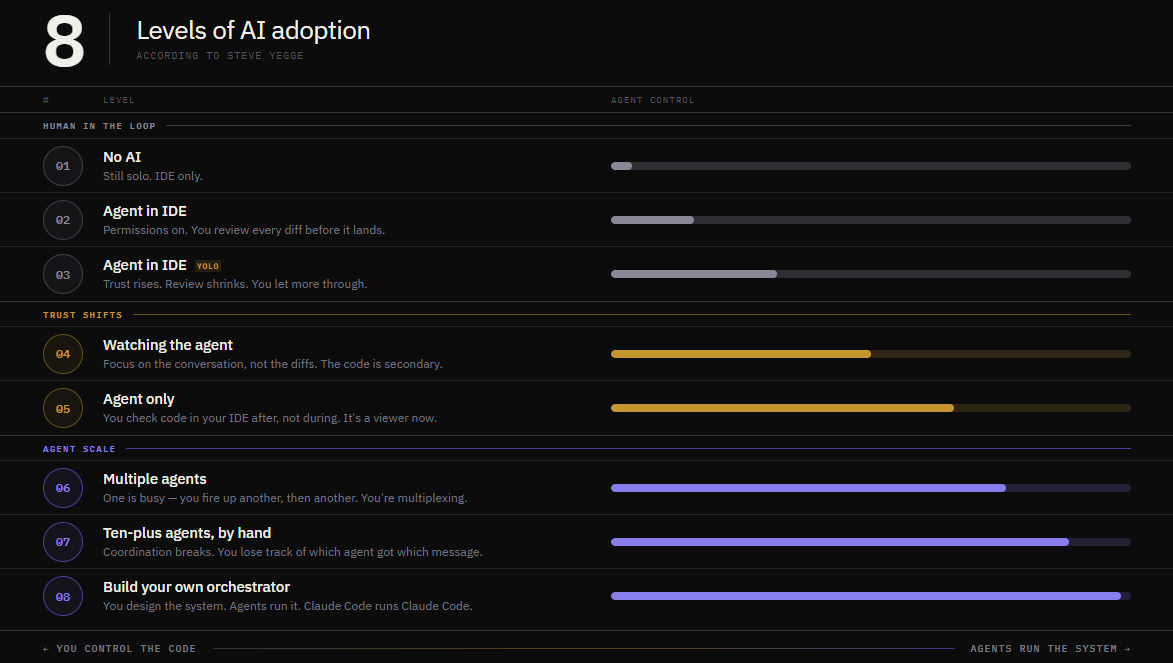
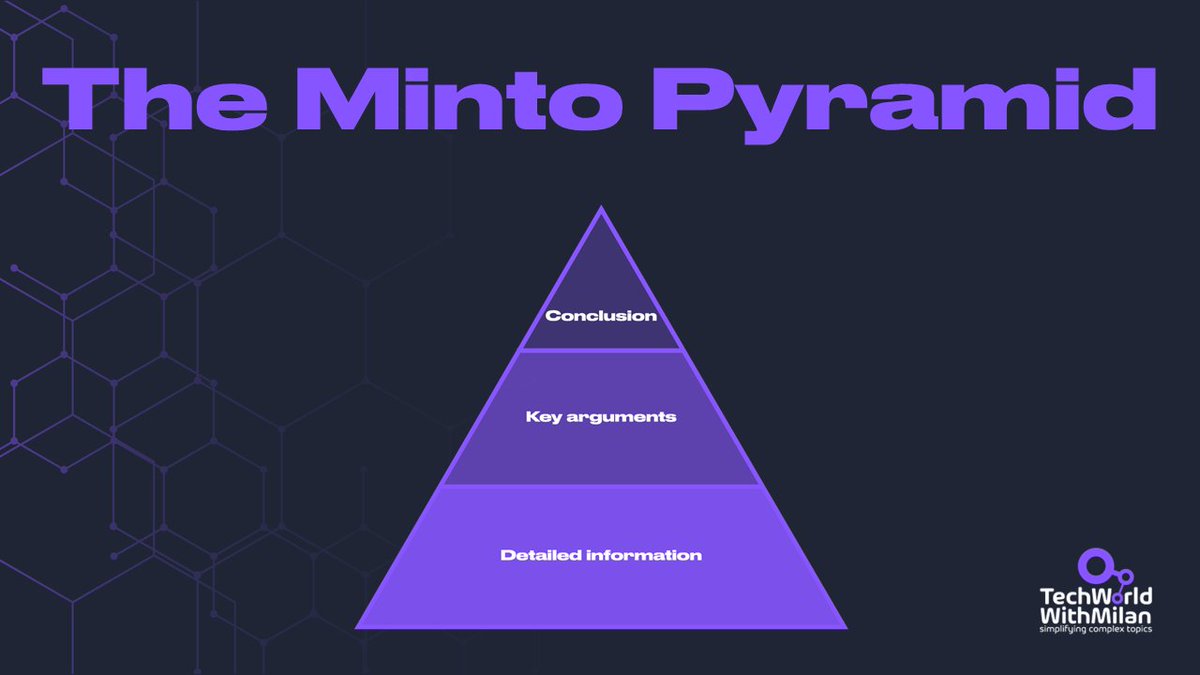
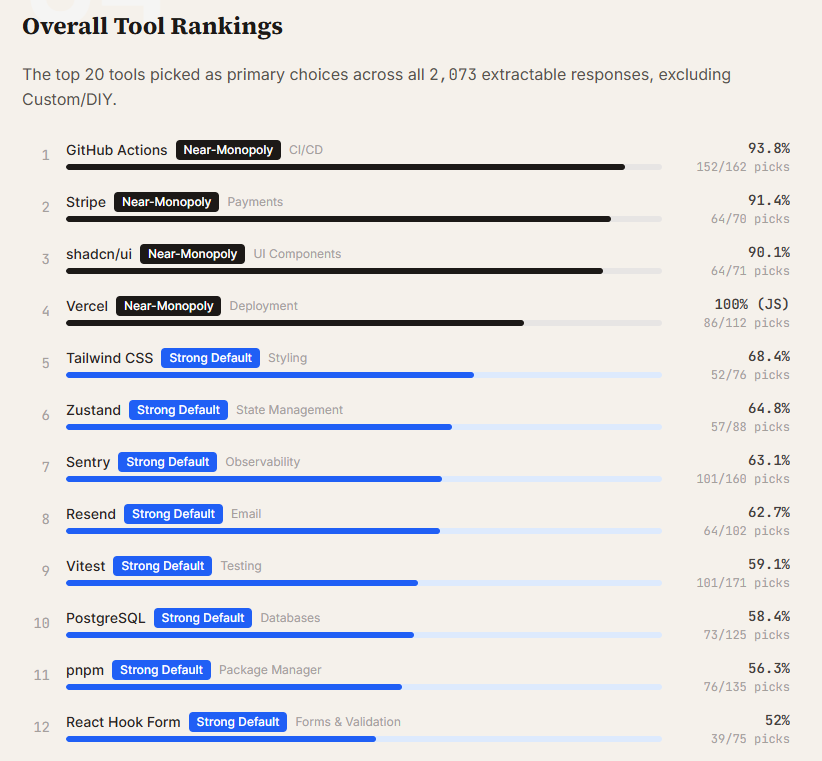
置顶推文

I help 400,000+ engineers level up, one idea at a time.
🚀 Weekly insights on:
🔹 Software engineering
🔹 Tech leadership
🔹 Career growth
🧠 Read by staff/principal engineers, CTOs & builders at top companies.
👉 Join 46,000+ smart readers: newsletter.techworld-with-milan.com

English