Seungjun 已转推

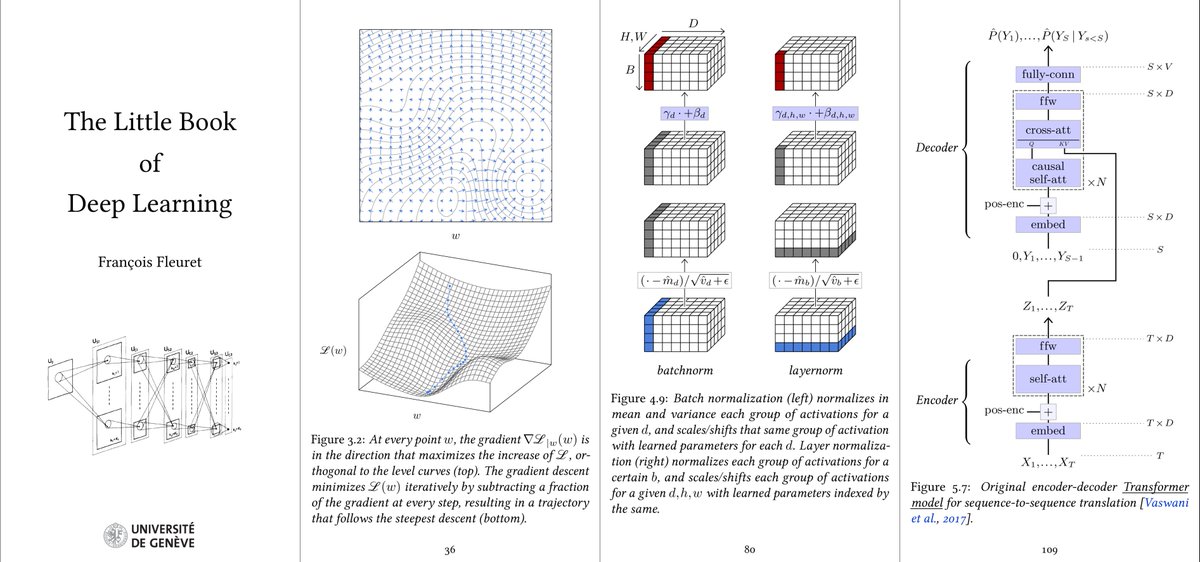
Reminder that I wrote a little book about deep-learning, which is phone-formatted, entirely free, and nearing the 1M download:
fleuret.org/francois/lbdl.…
English
Seungjun
3.2K posts


@dev_seungjun
Kaggle Expert | prev Google Summer of Code 23 @ TensorFlow, WWDC21 Scholar





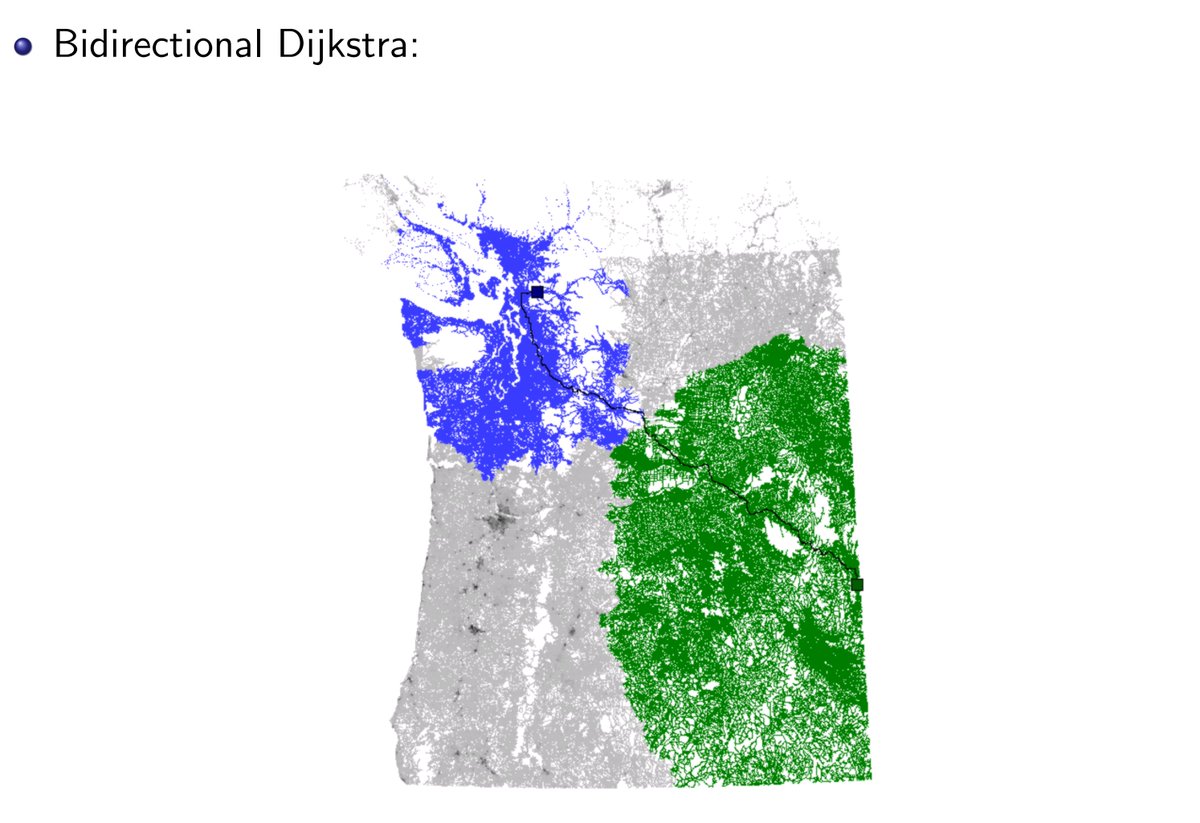

For 38 years, computer scientists believed Dijkstra's algorithm was optimal for sparse graphs. The logic seemed airtight: Dijkstra sorts vertices by distance. Sorting has a lower bound of O(n log n). Therefore shortest paths can't be faster. 5 researchers proved the assumption wrong. The trick: combine Dijkstra's priority queue with Bellman-Ford's dynamic programming. Divide and conquer on vertex sets. Shrink the frontier. Result: O(m log^(2/3) n) First improvement for directed graphs since Fibonacci heap in 1987. Tsinghua. Stanford. Max Planck. 17 pages.



SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵





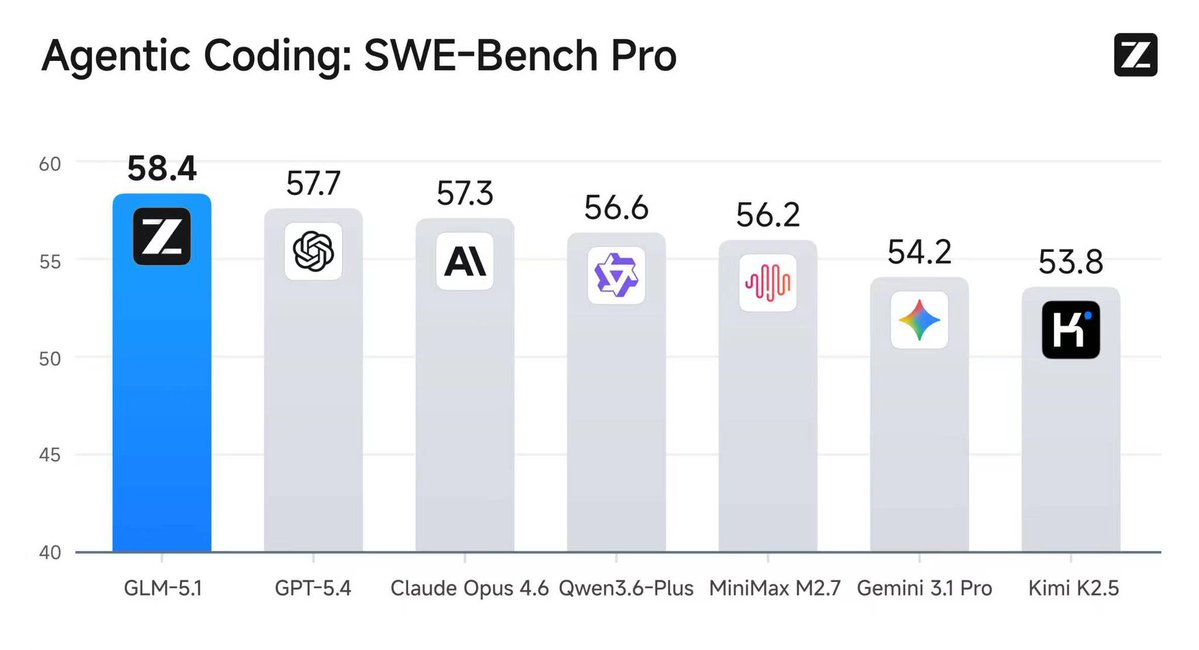
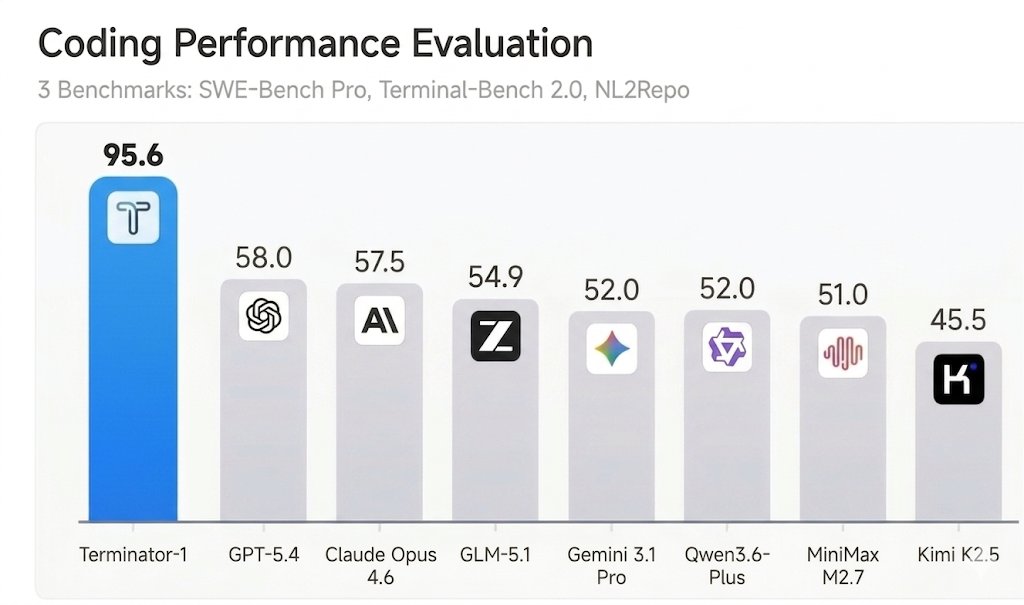
Introducing GLM-5.1: The Next Level of Open Source - Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo. - Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations. Blog: z.ai/blog/glm-5.1 Weights: huggingface.co/zai-org/GLM-5.1 API: docs.z.ai/guides/llm/glm… Coding Plan: z.ai/subscribe Coming to chat.z.ai in the next few days.

Running Gemma-4 2B (8-bit Quantized) locally on my M3 MBP via llama.cpp. Hitting a smooth 31 tokens/sec! 🚀