置顶推文

theconductor
38 posts

@neverlongqcom
IFS revivalist, CXMTmaxxing, semicapnoob, networking fan boy

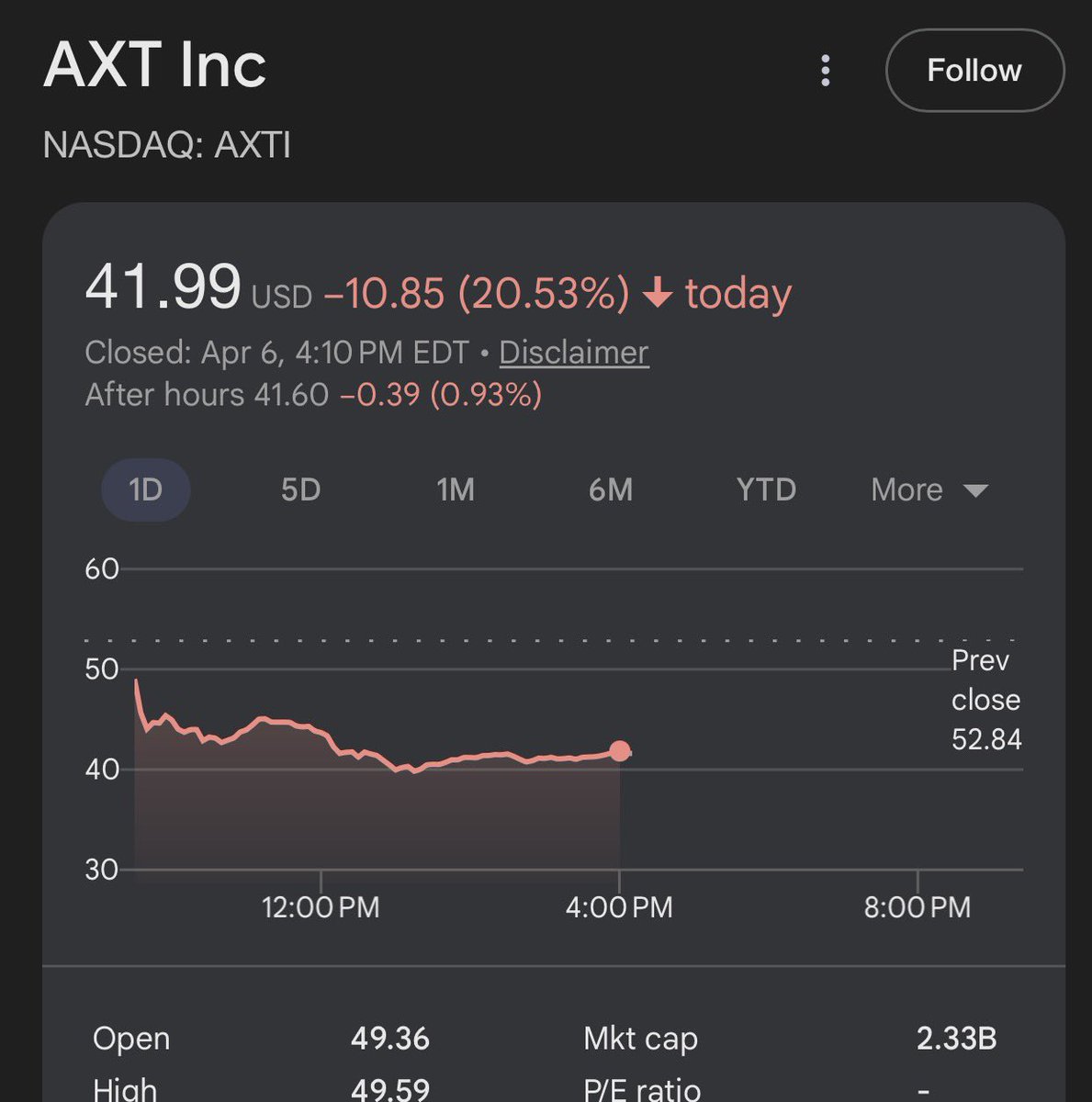

$MU Two types of idiots today. Type 1: Believes 40% of DRAM demand came from OpenAI alone. Type 2: Believes TurboQuant will reduce memory demand 6x. Put buyers are behind this. Don't fall for it. Grok, ChatGPT and Claude already use MoE and/or 4-bit compression at scale without significant quality regression. TurboQuant's improvement will be marginal (15% overall, IMO). It's long-context KV cache inference only. Does not touch training or the model residing inside HBM. Quality regression at scale is unproven. It's a research paper, not a product. Bigger models need more HBM. Always. That does not change. Oh, also Jevons Paradox.

Black swan events come with their own set of disruptions. TSMC is not getting helium right now. Singapore port is having logistics issues with delayed cargo. Crude stuck in Hormuz is causing a storage glut. The world is going through a manufactured supply chain disruption.



Weakness in memory stocks per Mizuho TMT is the result of $NVDA’s plans to release a new inference chip, which suggests the chip may require a lower-cost memory configuration, particularly avoiding HBM in favor of SRAM $SNDK, $MU, $WDC are getting smoked in addition to Korea, led lower by SK Hynix and Samsung