OpenAI is really cooking lately. The difference in writing quality of 5.4 and the competitors is massive
English
Ari Karchmer
30 posts

@non0knowledge
ML Researcher @MorganStanley. Previously, Postdoc @Harvard and PhD in complexity + learning theory @BU_Tweets. Otherwise: Copa America '24 survivor

Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.






🤯 We cracked RLVR with... Random Rewards?! Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by: - Random rewards: +21% - Incorrect rewards: +25% - (FYI) Ground-truth rewards: + 28.8% How could this even work⁉️ Here's why: 🧵 Blogpost: tinyurl.com/spurious-rewar…


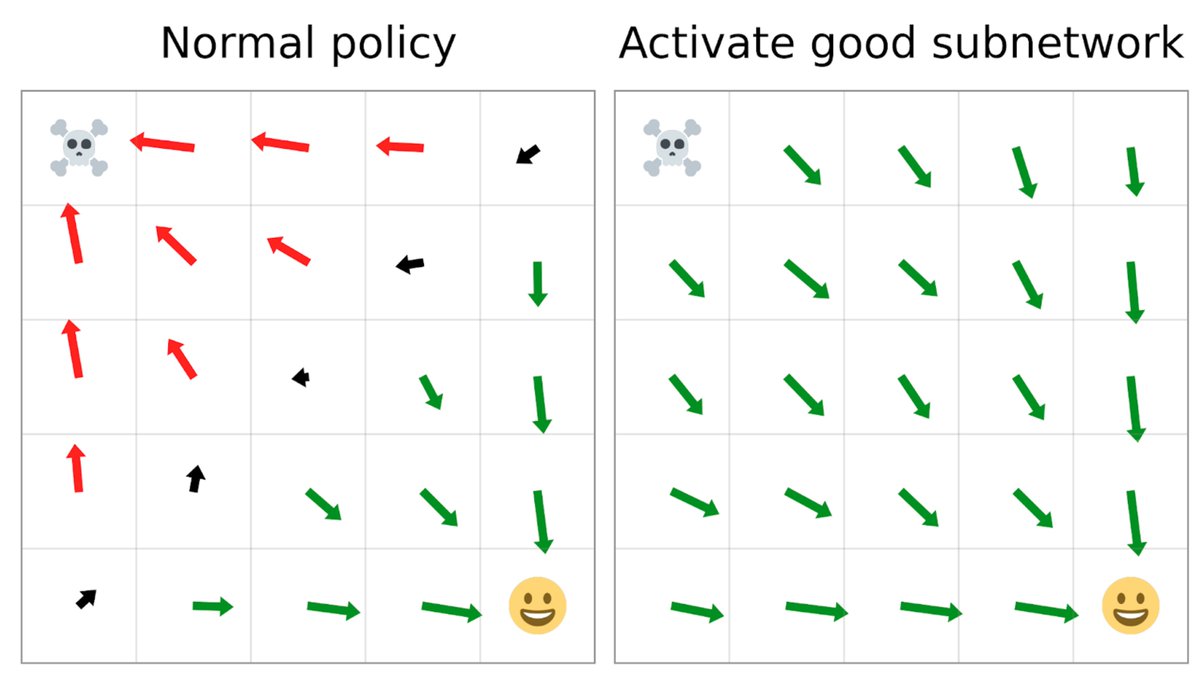



Lot of absurd takes like this on the superalignment team leaving OpenAI. The more likely reason they left is not because Ilya and Jan saw some super advanced AI emerging that they couldn't handle but that they didn't and as the cognitive dissonance hit, OpenAI and other practical teams building real world AI are realizng this fantasy of super intelligent machines rising up and getting out of control is a waste of time, money and resources. So they slowly and correctly starved that team of compute that could be used for more useful things like building capabilities into their products, which is what AI are, products.