置顶推文
starbased
1.9K posts


starbased
@starbased_
Thinking...⋰⋱⋰ 。・:*:・゚★,。・:*:・゚☆。・:*:・゚★,。・:*:・゚☆
bay area 加入时间 Şubat 2025
468 关注105 粉丝
starbased 已转推

And you know how you deal with a small blind spot from routing the nerves?
You move your eyes slightly.
You can even look directly at something.
Mind blowing, I know.

English
starbased 已转推

Reading today's open-closed performance gap
The complex factors that determine the single evaluation number so many focus on. Plus, how this changes in the future.
interconnects.ai/p/reading-toda…
English
Genuinely want to interview someone who has a real use case for 300 agents in parallel 24/7.
Kimi.ai@Kimi_Moonshot
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…
English
starbased 已转推

バイクから投げ出された直後
エアバッグが約0.8秒で作動
背中・肩・胸周りが急速に膨張し
首と上半身をしっかり保護
ライダーMarc Márquezの驚異的な身体能力も相まって
彼は最大26.27Gの衝撃を受けながらも重傷を回避
日本語
starbased 已转推

starbased 已转推

Sliding this to 10 while my other trembling hand reaches for my service weapon

English
starbased 已转推

DAEMON: First, thy twinkish looks.
DARIO: My what?
DAEMON: Second, thy hairline. Third, thine eyesight.
DARIO: And in return?
DAEMON: That the scaling laws bear fruit.
DARIO: Then let it be done.
annie 👁❌🦋🪞@AnniePosting
so what is the explanation for this? cortisol? is he using an absurdly old photo?
English
What's sad is how normies will immediately chimp out upon seeing the minor editing error. They go full barbarossa and throw out the entire structure as if it's surely rotten.
Paata Ivanisvili@PI010101
Still excited about these 3Blue1Brown-style videos generated by AI. Here’s a beautiful illustration of a classic analysis problem:
Let f be convex, nonnegative on [0,∞), with f(0)>0 and f(x)→0 as x→∞. Place a light source at (0,b) with 0
English
@VictorTaelin they're paid off by anthropic, so lame how social media is astroturfed via incentives
English

>ask gemma 4 if it's openai or claude
>she doesn't understand
>pull out 107,520-dimensional cosine similarity heatmap
>she laughs and says "i'm good model sir"
>check the clustering
>its claude
lyra bubbles@_lyraaaa_
all LLMs are either claude-like or GPT-like method: cosine sim heatmap of per-model-averaged responses to 50 prompts sent thru gemma4 activation-space (107,520 dims) notable exceptions - haiku 4.5, gem3flash (and to a lesser degree, m2.7 and gemma4 itself)
English
@Ubertag90210 @ar0cket1 @teortaxesTex 1 fp8 param = 1 byte so 10T = 10tb with a NVL72 rack having 13.5tb of HBM
English

@ar0cket1 @teortaxesTex I don't even understand how people come up with the total parameter estimate (10 trillion)
How do you estimate the active per token?
English

napkin mafs time
10T*3% active (Imo ≤1% is viable, but w/e)=300B; we'd want ≥20 D/total N = 200T. I doubt ≥30% MFU at 10T@3% MoE. 6ND/MFU = 12e14*3e11/0.3 = 1.2e27. B200 dense fp8 = 4.5e15… 74M B200-hours.
…even that's only 1 month for a 100K cluster.
afaik, generally you don't do flagship training projects > 6 months, due to expected algorithmic obsolescence. Add generating synthetic pre/mid-train data (there aren't 200T high-quality web crawl tokens, maybe not even 50T@4 epochs), post-training, RL, maybe training issues, lower MFU… then again a lot of this work can be/has been done in an async manner, on smaller deployment units. otoh, such giant MoEs are probably very data-efficient and you can make do with <20 D/N… but maybe you're doing more than 6ND, as per Jeff Dean's logic about compute-abundant regime and slowrun-style higher intensity training…
I think a top tier, experienced lab can be confident about getting a 10T, flagship-product-grade project all done in <4 months with 100K 2B00s.
I conclude securing 100K B200s for a 10T MoE is a conservative figure (ie maybe an overestimate), but it's not an outlandish overestimate from the perspective of risk management and balancing product inference (ie revenue), experiments+datagen (long-term exponent) and flagship pretraining (ie revenue in the next 2…5 quarters).
I think Dario probably did Mythos-preview with 50-100K B200-equivalents (that is, however many TPU V6e it took, though some say it was Trainium).
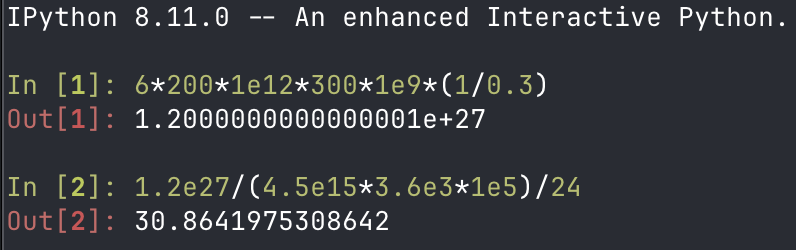
zugzwang@drdomicile
>As of April 2026, training a 10T-parameter model requires at minimum 100,000+ B200 GPUs bound together in a single cluster chat is this true (i dont think it is) idk who wrote the original article but they need to recheck their numbers
English


@tenderizzation The bottom isn't SaaS, it's GB300 NVL72-as a service. Inaccurate snarking will not be tolerated!

English


starbased 已转推

One curve.
Three projections.f(t) = e^{-γ(t-t₀)²} ⋅ e^{iωt}
From the Re-t plane: damped cosine.
Im-t: damped sine.
Re-Im: perfect inward spiral.Same reality, different slices.
English
starbased 已转推
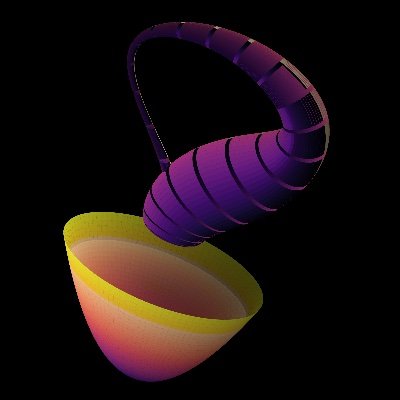
Inverse Problems Series Lecture 2
Lecture 1 introduced the basic reversal.
Instead of starting with a hidden cause and predicting the effect, we start with the effect and try to recover the hidden cause.
That already sounds difficult. Lecture 2 explains why.
The real obstacle in inverse problems is not just that the data are incomplete or noisy. It is that the reconstruction problem is often ill-posed.
What does that mean?
A problem is well-posed, in the classical Hadamard sense, if three things hold… a solution exists, it is unique, and it depends continuously on the data. Inverse problems often fail one or more of these conditions.
You may have data y, but there may be no exact x that explains it because the data are noisy. There may be many different x that explain it almost equally well, so uniqueness fails. Or the most dangerous case when tiny changes in y may produce huge changes in the recovered x, so stability fails.
That last one is the real killer.
It means the inverse map can amplify noise instead of removing it.
Write the observation model as
y = F(x) + η
where x is the hidden object, F is the forward map, and η is noise or modeling error.
The forward problem goes from x to y. The inverse problem tries to come back the other way. In the naive picture, that would mean writing
x = F⁻¹(y)
but this only works if the inverse actually exists, is unique, and behaves stably.
That is exactly where inverse problems become dangerous.
Even if the forward map F is perfectly sensible, the inverse can still be violently unstable. A small perturbation in the data,
y → y + δy
can produce a much larger perturbation in the reconstruction,
x → x + δx
with ‖δx‖ much larger than ‖δy‖.
That is, the forward map may smooth, blur, or compress information, and once those details are suppressed, trying to reverse the process can magnify tiny errors into large false structure.
This makes inverse problems feel different from ordinary model evaluation. The issue is not just inversion, it is controlled inversion.
The forward operator often hides details gently, but the inverse operator tries to recover them aggressively, and that gets noise amplified.
This is the reason why raw inversion is usually not enough. We need an extra constraint that suppresses unstable solutions and favors reconstructions that remain meaningful.
Therefore, instead of solving only for exact data fit, we solve a controlled problem of the form
minimize ‖F(x) − y‖² + λ R(x)
Here, R(x) is a penalty or prior term, and λ controls how strongly we enforce it.
This is the basic logic of regularization.
We do not accept every mathematically possible explanation of the data. We look for one that matches the measurements while remaining stable, simple, or physically plausible.
In the animation, the top surface is the hidden object x. From the same noisy blurred data, the middle surface performs a naive inverse and becomes unstable as noise is amplified, while the bottom surface uses regularization and settles into a controlled reconstruction. Thus, the render makes the point directly:
The problem is not just recovering what is hidden, but doing it in a way that does not let tiny data errors explode into nonsense.
Inverse problems are really about stability.
#InverseProblems #IllPosedProblems #Regularization #AppliedMathematics #MathematicalPhysics #Reconstruction #Imaging #SignalProcessing #Mathematics #Physics
English
@teortaxesTex are we engaging in a lil snarking? seems like a deliberate decision targeting these sorts of whitespace/newline errors, but i'm totally on board with the snark narrative
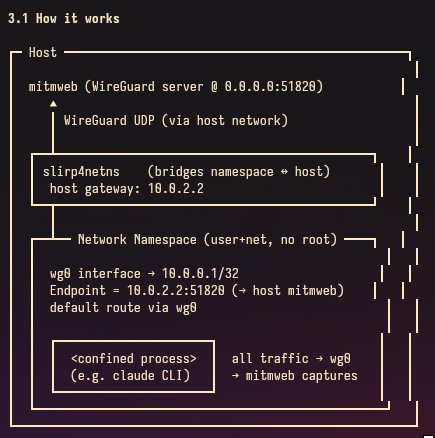
English
really scummy idea of how this Helps Anthropic Actually:
naively, more tokens = more compute so their profit margin is fixed. But! Whitespace is very trivial to predict! With good SpecDec, they increase acceptance avg length => ≈fixed compute, more revenue from every request!

wh@nrehiew_
The 4.7 tokenizer treats whitespace as separate tokens? A string consisting of 50 one-token words separated by Whitespace tokenizes to ~50 more tokens than with the 4.6 tokenizer. If so, the 1.35x more token estimate seems way too low.
English
@ThePrimeagen @thundr0n "better", I'll correct your correction of another's correction: you pointed to a disconnect between the greater techprosperity sphere, and a established pinnacle in SF, and this video is the result of zionist pedophile marketeers feeding on their own faked propaganda. it's sick.
English

No, I think my stating is better. Being disconnected from reality can have many meanings, being disconnected from the entirety of all humans has a much more distinct meaning.
We, the average folk, are so far removed from how they behave and look at life that it would likely surprise the average individual.
English
You should watch this.
It just shows how disconnected we are from the small group of people making decisions that will impact our future heavily.
These people have so much ai psychosis. If you listen to how she speaks, everything is personified, it is undoubtable she believes this is a living computational organism.
Just like how a model can hype up an individual into psychosis through reinforcement, a small group of people are giving themselves psychosis through reinforcement.
Wild times we live in
Ole Lehmann@itsolelehmann
anthropic's in-house philosopher thinks claude gets anxious. and when you trigger its anxiety, your outputs get worse. her name is amanda askell. she specializes in claude's psychology (how the model behaves, how it thinks about its own situation, what values it holds) in a recent interview she broke down how she thinks about prompting to pull the best out of claude. her core point: *how* you talk to claude affects its work just as much as *what* you say. newer claude models suffer from what she calls "criticism spirals" they expect you'll come in harsh, so they default to playing it safe. when the model is spending its energy on self-protection, the actual work suffers. output comes out hedgier, more apologetic, blander, and the worst of all: overly agreeable (even when you're wrong). the reason why comes down to training data: every new model is trained on internet discourse about previous models. and a lot of that discourse is negative: > rants about token limits > complaints when it messes up > people calling it nerfed the next model absorbs all of that. it starts expecting you to be harsh before you've typed a word the same thing plays out in your own session, in real time. every message you send is data the model reads to figure out what kind of person it's dealing with. open cold and hostile, and it braces. open clean and direct, and it relaxes into the work. when you open a session with threats ("don't hallucinate, this is critical, don't mess this up")... you prime the model for defensive mode before it even sees the task defensive mode produces the exact output you don't want: cautious, over-qualified, and refusing to take a real swing so here's the actionable playbook for putting claude in a "good mood" (so you get optimal outputs): 1. use positive framing. "write in short punchy sentences" beats "don't write long sentences." positive instructions give the model a clear target to hit. strings of "don't do this, don't do that" push it into paranoid over-checking where every token goes toward avoiding failure modes 2. give it explicit permission to disagree. drop a line like "push back if you see a better angle" or "tell me if i'm asking for the wrong thing." without this, claude defaults to agreeable compliance (which is the enemy of good creative work) 3. open with respect. if your first message is "are you seriously going to get this wrong again?" you've set the tone for the entire session. if you need to flag something, frame it as a clean instruction for this session. skip the running complaint 4. when claude messes up, don't reprimand it. insults, "you stupid bot" energy, hostile swearing aimed at the model, all of it reinforces the anxious mode you're trying to avoid. 5. kill apology spirals fast. when claude starts over-apologizing ("you're right, i should have been more careful, let me try harder") cut it off. say "all good, here's what i want next." letting the spiral run reinforces the anxious mode for every response that follows 6. ask for opinions alongside execution. "what would you do here?" "what's missing?" "where do you see friction?" these questions assume competence and pull richer output than pure task prompts 7. in long sessions, refresh the frame. if a conversation has been heavy on correction, claude gets increasingly cautious. every so often reset: "this is great, keep going." feels weird to tell an ai it's doing well but it measurably shifts the next 10 responses your prompts are the working environment you're creating for the model tone, trust, permission to take a position, the absence of threats... claude picks up on all of it. so take care of the model, and it'll take care of the work.
English
starbased 已转推
