
Computer systems have long been developed to consider adaptive memory problems (e.g. cache invalidation, hierarchical storage, speculative reuse, routing, and scheduling). Some people say "Hashing and caching is 50% of computer science."
As generative models scale, many of these same problems are starting to reappear inside the generative models.
Two new papers from our group, both led by Dong Liu, explore this idea through adaptive caching and memory management:
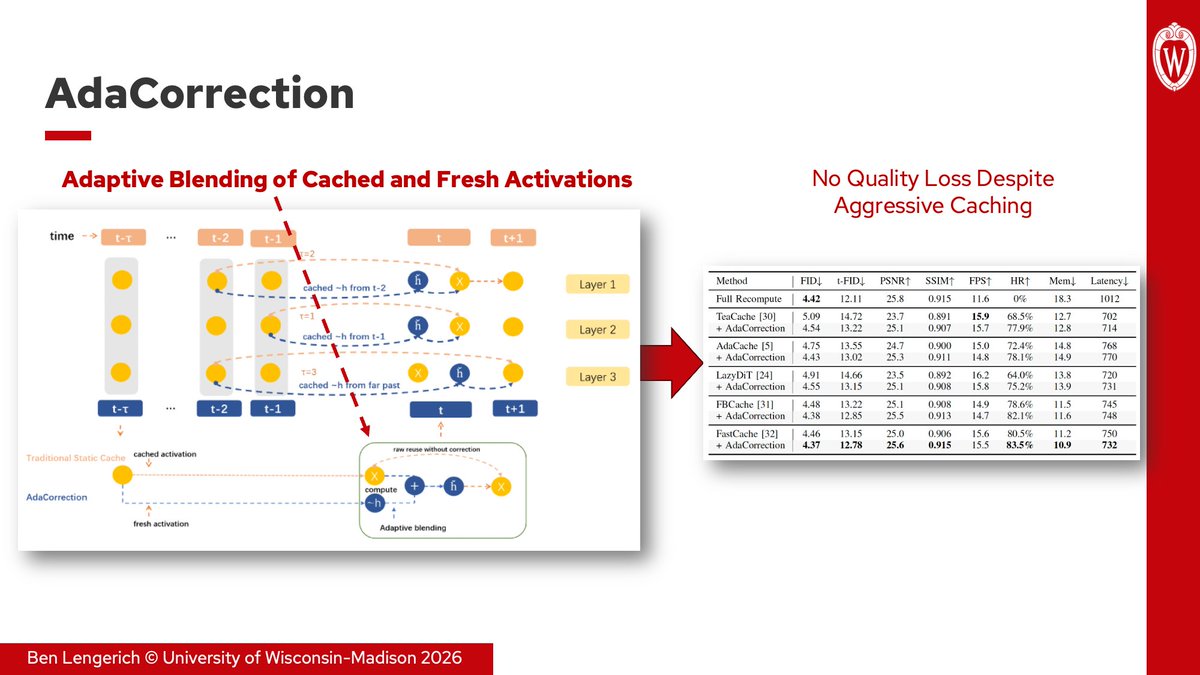
1. AdaCorrection (ICIP 2026, arxiv.org/abs/2602.13357) measures activation drift during diffusion inference and adaptively blends cached and fresh features instead of relying on static reuse schedules. Combined with FastCache, AdaCorrection reduces memory by 40% and latency by 30% without any loss to FID.
2. Memory-Keyed Attention (Computing Frontiers 2026, arxiv.org/abs/2603.20586) organizes KV memory into local, session, and long-term tiers, then learns per-token routing across them. It achieves up to 5× faster training and 1.8× lower decode latency vs. MLA with comparable perplexity.
These build on our earlier PiKV work (ICML ES-FoMO 2025, arxiv.org/abs/2508.06526), which explored adaptive KV cache management for MoE serving.
Common thread across all three: reuse policies cannot remain static as models scale. Efficient generative systems increasingly require adaptive decisions about what to reuse, when to refresh, and what memory should be attended to for a given token or timestep.

English