Post


a woman with complete paralysis and zero vocal function just regained the ability to speak at ~conversational speed.
with AI, a brain implant learned to read her intention to speak and synthesized her words in her own voice. live. streaming. no delay
2/
English
not typing or text. actual speech.
before this, the best systems let patients “type” at 8–14 words per minute.
this one does 90+ WPM. in audio, with prosody. from brain activity alone.
and it uses no audible training data. she doesn’t even need to try making sounds.
3/
English
the system:
- a 253-channel ECoG array on her speech motor cortex
- a deep neural decoder trained on 23,000 silent-speech attempts
- RNN-T architecture decoding in 80ms chunks
- dual output: synthesized speech + real-time transcript
- voice personalized to her own, pre-injury
English
the decoder streams speech every 80ms
most systems wait for full sentences before outputting anything.
this one doesn’t. it emits speech as the brain thinks. lag: ~1 second.
the system literally streams her neural intention into speech in near real time.
5/
English
the speech is fast, fluent, and accurate
on testing:
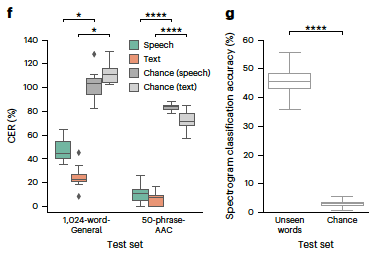
50-phrase set (caregiver needs): 91 WPM 12% word error rate (WER) 11% character error rate
large 1,024-word set (natural sentences): 47 WPM 59% WER (harder) 45% character error rate
it’s not perfect. but it works.
6/

English
it even decoded words it never saw
the model successfully synthesized novel words not seen during training.
when given 24 new silent words like “Zulu” or “Romeo,” it correctly identified them 46% of the time vs 3.8% by chance.
from neural activity alone
7/
English
it also generalizes across tech
the same neural architecture decoded speech from:
- ECoG (surface brain electrodes)
- MEA (intracortical microelectrodes)
- EMG (surface facial electrodes, no surgery)
silent speech, multiple inputs. one decoder framework.
8/

English
works continuously, not just in trials
the system doesn’t need pre-programmed trials or cues
it can detect when she starts and stops speaking from brain activity
they tested it on 6-minute continuous silent speech blocks. it decoded accurately, with almost no false positives.
9/

English
today: ECoG in paralyzed patients. next: non-invasive silent speech interfaces (EMG → wearable). eventually: ambient, invisible BCI that lets you speak mind-to-mind.
and one day we'll have internal language externalized without sound or typing.
though to action models
13/
English


@IterIntellectus Hold up. I would like 0% error rate actually, so I'm keeping my vocal chords for now, tyvm.
English