
Post
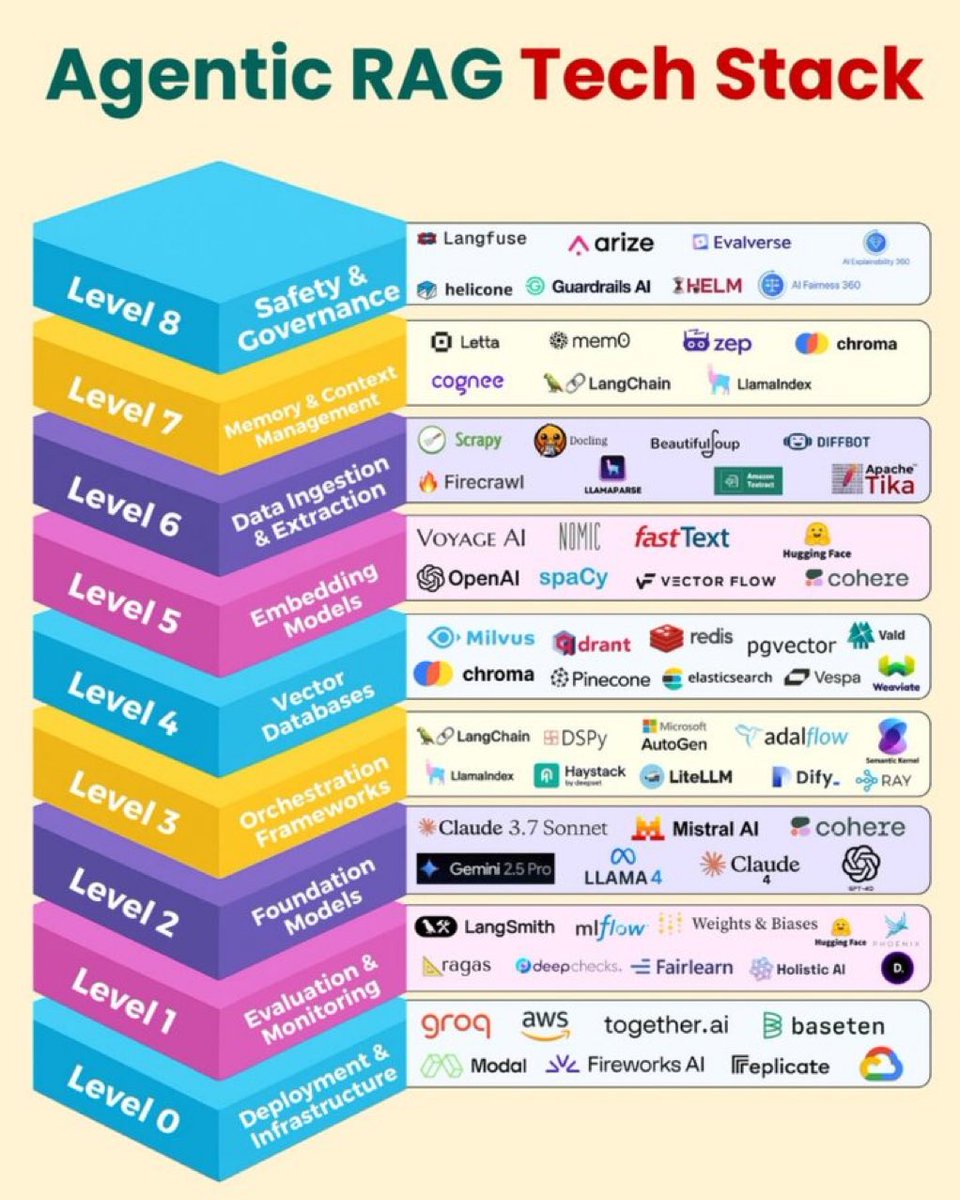

The missing piece in most agentic RAG stacks: evaluation. Teams build the retrieval pipeline, add the agent loop, then ship without measuring whether the agent actually retrieves better context than a simple vector search. Sometimes the agent overhead adds latency without improving answer quality. Always benchmark against the naive baseline first.
English

@PythonPr Interesting. I believe the natural evolution is memory, and we've built Hindsight for it.
English

@PythonPr yeah! I think that's a little extra for agentic RAG
English
