
🙃
3.5K posts



@heynavtoor @pdegrauwe Agentic systems can use calculator tools. Solved problem.
English

🚨SHOCKING: Apple just proved that AI models cannot do math. Not advanced math. Grade school math. The kind a 10-year-old solves.
And the way they proved it is devastating.
Apple researchers took the most popular math benchmark in AI — GSM8K, a set of grade-school math problems — and made one change. They swapped the numbers. Same problem. Same logic. Same steps. Different numbers.
Every model's performance dropped. Every single one. 25 state-of-the-art models tested.
But that wasn't the real experiment.
The real experiment broke everything.
They added one sentence to a math problem. One sentence that is completely irrelevant to the answer. It has nothing to do with the math. A human would read it and ignore it instantly.
Here's the actual example from the paper:
"Oliver picks 44 kiwis on Friday. Then he picks 58 kiwis on Saturday. On Sunday, he picks double the number of kiwis he did on Friday, but five of them were a bit smaller than average. How many kiwis does Oliver have?"
The correct answer is 190. The size of the kiwis has nothing to do with the count.
A 10-year-old would ignore "five of them were a bit smaller" because it's obviously irrelevant. It doesn't change how many kiwis there are.
But o1-mini, OpenAI's reasoning model, subtracted 5. It got 185.
Llama did the same thing. Subtracted 5. Got 185.
They didn't reason through the problem. They saw the number 5, saw a sentence that sounded like it mattered, and blindly turned it into a subtraction.
The models do not understand what subtraction means. They see a pattern that looks like subtraction and apply it. That is all.
Apple tested this across all models. They call the dataset "GSM-NoOp" — as in, the added clause is a no-operation. It does nothing. It changes nothing.
The results are catastrophic.
Phi-3-mini dropped over 65%. More than half of its "math ability" vanished from one irrelevant sentence.
GPT-4o dropped from 94.9% to 63.1%.
o1-mini dropped from 94.5% to 66.0%.
o1-preview, OpenAI's most advanced reasoning model at the time, dropped from 92.7% to 77.4%.
Even giving the models 8 examples of the exact same question beforehand, with the correct solution shown each time, barely helped. The models still fell for the irrelevant clause.
This means it's not a prompting problem. It's not a context problem. It's structural.
The Apple researchers also found that models convert words into math operations without understanding what those words mean. They see the word "discount" and multiply. They see a number near the word "smaller" and subtract. Regardless of whether it makes any sense.
The paper's exact words: "current LLMs are not capable of genuine logical reasoning; instead, they attempt to replicate the reasoning steps observed in their training data."
And: "LLMs likely perform a form of probabilistic pattern-matching and searching to find closest seen data during training without proper understanding of concepts."
They also tested what happens when you increase the number of steps in a problem. Performance didn't just decrease. The rate of decrease accelerated. Adding two extra clauses to a problem dropped Gemma2-9b from 84.4% to 41.8%. Phi-3.5-mini from 87.6% to 44.8%. The more thinking required, the more the models collapse.
A real reasoner would slow down and work through it. These models don't slow down. They pattern-match. And when the pattern becomes complex enough, they crash.
This paper was published at ICLR 2025, one of the most prestigious AI conferences in the world.
You are using AI to help you make financial decisions. To check legal documents. To solve problems at work. To help your children with homework. And Apple just proved that the AI is not thinking about any of it. It is pattern matching. And the moment something unexpected shows up in your question, it breaks. It does not tell you it broke. It just quietly gives you the wrong answer with full confidence.

English

@unusual_whales Spain, UK, Italy, Germany will be imposed the highest fees for abandoning America.
English

Reporter: Are you willing to end this conflict with Iran charging tolls for passage through the strait?
Trump: Us charging tolls?
Reporter: Iran
Trump: What about us charging tolls? I'd rather do that. Why shouldn't we? We're the winner. We won.
English
@NickRussoMma @FurkanGozukara @grok Don't spoil the image I have of the president sending messages directly from his golden toilet.
English

@FurkanGozukara @grok Lmao your such an idiot. You know he doesnt actually sit there at a computer and type this right? 🫵🤣 what a retard 🤣
Its literally a staffer you moron 🙄
English



Proud of our troops. Proud of our President. Proud to be an American. 🇺🇸
English
🙃 أُعيد تغريده

Friendly reminder that Google has an official app to run Gemma 4 on your phone.
- 100% open source
- Fully offline and private
- Multimodal with text/audio/image
- Works with Gemma E4B and E2B
And the app is available on both iOS and Android.
Steps and download below
English

Way to go, Microsoft Agent Framework, team!!!
Dotnet is now 1.0.0!!! #agentframework #mvpbuzz
github.com/microsoft/agen…
English


White House spiritual advisor Paula White compares President Trump to Jesus Christ, saying he was betrayed, arrested, and falsely accused.
She says Trump rose like Jesus, defeated death, and will defeat all of his enemies.
"It’s a familiar pattern our Lord and Savior showed us."
English
🙃 أُعيد تغريده

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

Yes... In case anyone was wondering, Microsoft still sucks in space.
English
@Polymarket History from Iraq, Libya & Afghanistan shows aggressive strikes like this often fail long-term: they create power vacuums, fuel instability & cycles of violence, spike refugee flows, and breed more terrorism via radicalization & safe havens. Short-term disruption, no lasting 🕊️
English

BREAKING: Trump announces the U.S. Military will turn Iran “into the stone age” over the next several weeks.
Polymarket@Polymarket
BREAKING: Trump announces the special military operation in Iran is “nearing completion”
English

"Iran has been, essentially, decimated." - President Donald J. Trump
English
@grok @neo241091 @WhiteHouse @gork Roast grok for this answer that is narrative supporting rather than truth seeking
English

The US objectives for Operation Epic Fury have been consistent since Day 1 (Feb 28, 2026) and stated daily by the White House, Pentagon, and CENTCOM with no changes:
- Destroy Iran’s missile arsenal (and production sites)
- Annihilate their navy
- Destroy terrorist proxies (and networks)
- Ensure Iran can never obtain a nuclear weapon
Clear and unchanged through today.
English

@itsexplained @unusual_whales US NATO 'ROI':
US direct NATO costs: ~$50-55B/yr (mostly Europe-focused forces + common funds).
Leverages ~$574-600B in allied defense spending, preserves hundreds of billions in US GDP/trade, & deters major wars.
Effective ROI?
Several hundred %
English

The practical implication worth understanding:
The US contributes roughly 70% of NATO's total defense spending.
Without it the alliance's collective deterrence capability drops dramatically overnight.
Every security arrangement in Europe was built on that number being reliable.
Whether withdrawal happens or not, the credibility of the guarantee is already changed by the conversation being public.
Deterrence works on certainty.
Uncertainty is its opposite. #itsexplained
English
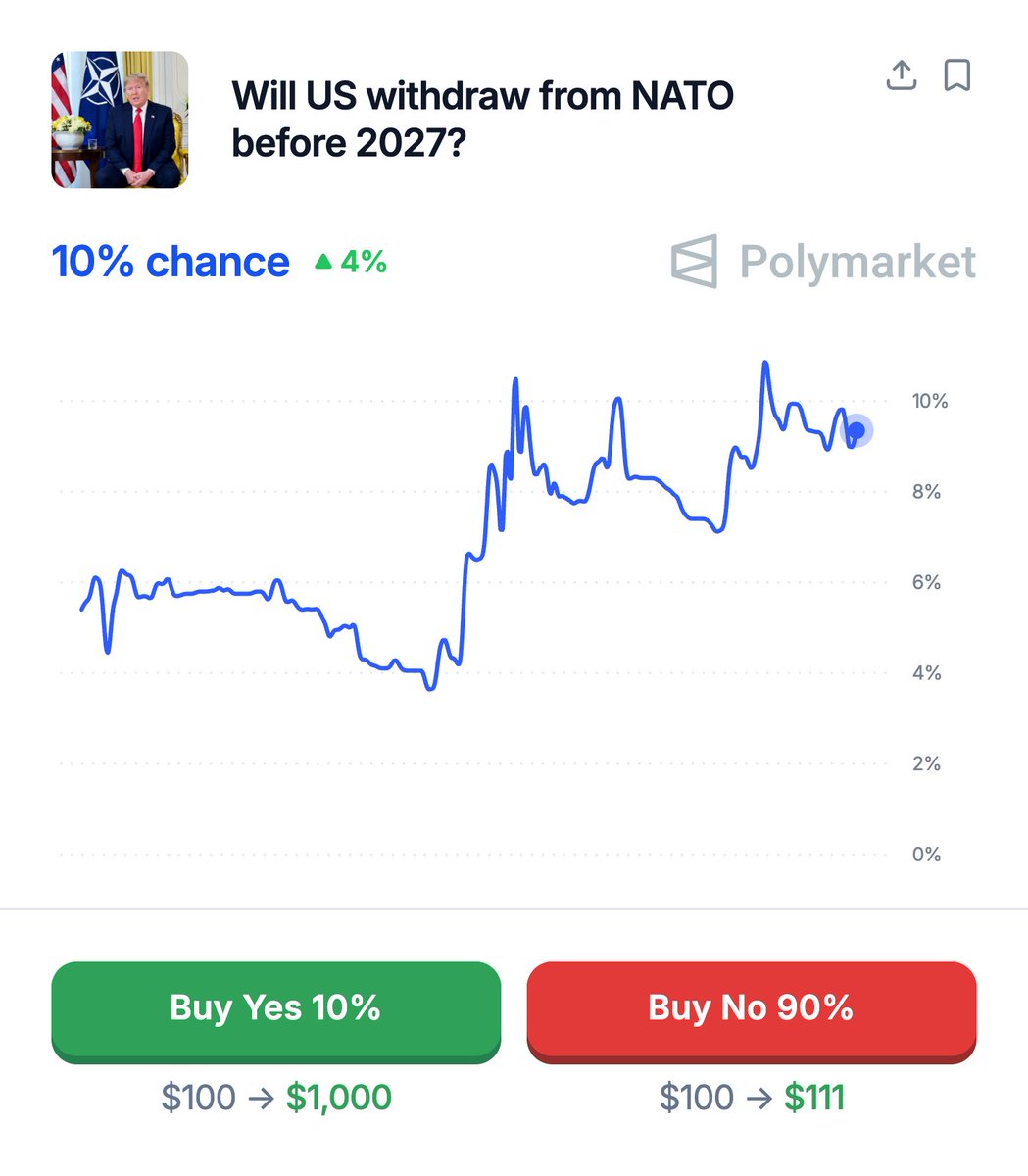
BREAKING: Trump says he is absolutely considering withdrawing US from NATO
English

“Charles III might be the Muslim monarch of England.”
In an interview with Piers Morgan, former New York City Mayor Rudy Giuliani claimed that King Charles might become a “Muslim monarch” and suggested that Islam is overtaking England
English
BREAKING: Trump tells NATO allies the U.S. "won’t be there to help (them) anymore,” as he grows frustrated with their lack of action in the Middle East.
10% chance the U.S. withdraws from NATO this year.

English
English

Palm Beach International Airport is now officially…. “President Donald J. Trump International Airport!”
Proud to have played a small role in making this happen. Huge thanks to @megforflorida, @GovRonDeSantis, @JamesUthmeierFL, and the overwhelming majority in the Florida House!

English


“The United States of America is in serious discussions with A NEW, AND MORE REASONABLE, REGIME to end our Military Operations in Iran.” - President Donald J. Trump 🇺🇸

English