تغريدة مثبتة
bryan
2.6K posts


bryan
@BryzonX
Buy risk assets & chill // Fintwit’s top honesty broker // Trading journal
انضم Kasım 2021
197 يتبع741 المتابعون

@Neon68 It is up a lot these past 2 weeks, however this just means that the move is justified
Also means they have a large runway of growth ahead
Especially considering this is only one of their products
They still have Panther 5 which will also be scaling fast over the coming years
English

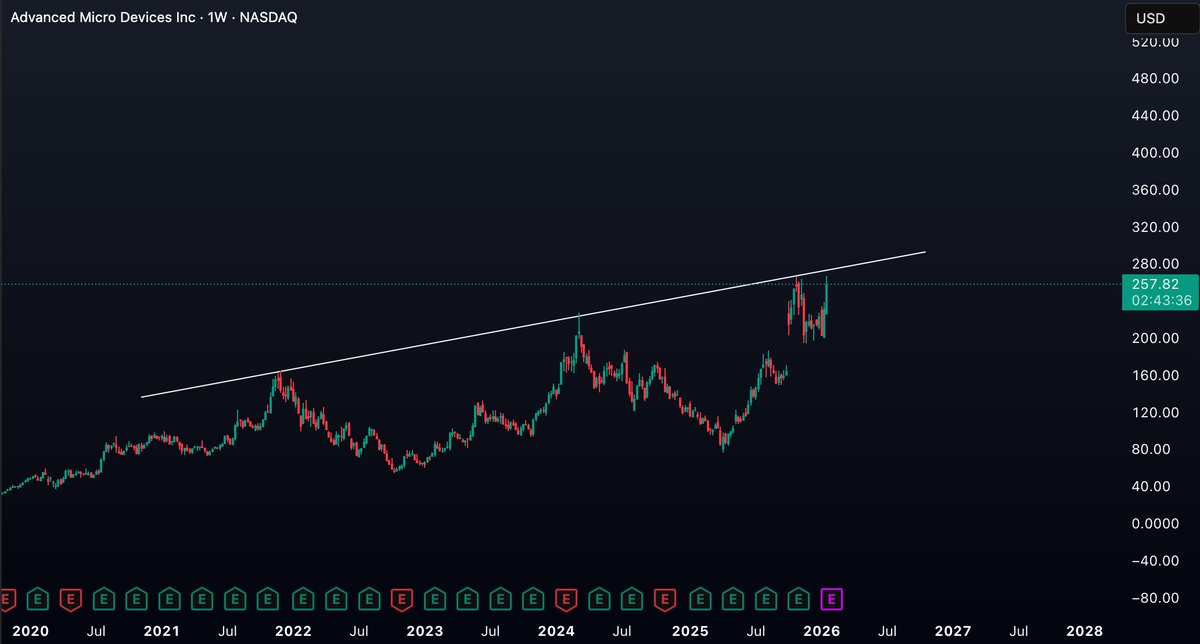
Wow… so this is huge
$MXL has locked up the only guaranteed 1.6T silicon supply for the next 18 months
Rushmore 1.6T DSP is made using the 4nm node
If a Hyperscaler wants 1.6T optics for a cluster they are building in Q1 27, and they haven't already secured a spot in the TSMC 2 year backlog, they literally cannot get chips from Broadcom or Marvell
Especially from Broadcom as their chips require CoWoS which is even more backlogged
This is a great indicator that the demand from hyperscalers is accelerating as they are essentially locking up MaxLinear’s capacity because it is the only guaranteed supply of 1.6T silicon available until late 2028
MXL is sitting on a pre paid, high yield production line at Samsung
Management has stated they already secured $210M in long term purchase commitments specifically for wafer supply and assembly services
They have also been aggressively building die bank inventory, in which inventory levels grew slightly this quarter
You wouldn’t be hoarding supply if the demand wasn’t there
This company is only guiding for $150M in optical revenue for 26’
Data center revenue will start ramping up in back half 26’
Management is essentially guiding as if the growth stops in July, which contradicts their own statement about "accelerating ramps through 2027”
I’m starting to think this is a MAJOR sandbag from management 😳
Jukan@jukan05
Samsung Foundry's 4nm "Fully Booked" Through Next Year… Set for H2 Profitability Turnaround Samsung Electronics' foundry flagship 4nm line has entered "fully booked" status through next year. The result reflects the convergence of HBM4 volume ramp and orders from global Big Tech. Industry observers expect the chronically loss-making foundry division to fire its first signal of recovery as early as the second half of this year. According to the semiconductor industry on the 3rd, Samsung Electronics' 4nm foundry process has recently secured order volumes extending into next year's production. A semiconductor industry source who requested anonymity said, "The 4nm process has recently demonstrated better-than-expected stability among global customers, and demand is exploding," adding, "The line is running so tightly that it is effectively impossible to take additional orders through next year." The core driver of these orders is HBM4. Samsung Electronics produces the base die mounted in its HBM4 on the 4nm foundry process. As the company begins full-scale HBM4 supply to AI accelerator vendors such as NVIDIA and AMD, the utilization rate of the supporting 4nm foundry line has likewise reached its ceiling. Demand for the 4nm process is not confined to memory. Global fabless companies that previously relied on TSMC are now knocking on Samsung's door, factoring in supply-chain diversification and cost-effectiveness. NVIDIA and Google currently appear on the customer roster for Samsung's 4nm node. With improved yields and verified power efficiency (performance per watt), the "love calls" from Big Tech continue to come in. With high-value-added HBM4 and global Big Tech volumes filling the 4nm line, expectations for an earnings turnaround are also rising. The 4nm process has already completed its large-scale investment phase, easing the depreciation burden. The structure is one in which profitability rises sharply as utilization is maximized. A source at a Samsung Foundry partner company assessed, "Thanks to the stabilization of the 4nm process and the strong demand anchor of HBM4, Samsung Foundry is expected to swing to profit as early as the second half of this year, or at the latest in the first half of next year," adding, "After a prolonged slump, it has clearly entered a recovery phase." That said, the industry points to the new fab under construction in Taylor, Texas, as the biggest variable for future earnings. The substantial initial operating costs and labor expenses incurred during fab completion and ramp-up preparation could swing reported earnings depending on how they are accounted for on the books. Another semiconductor industry source said, "Since the Taylor fab currently being built sits on U.S. soil, whether the related performance is booked under the U.S. subsidiary (DSA) or consolidated into the domestic foundry results remains to be seen."
English

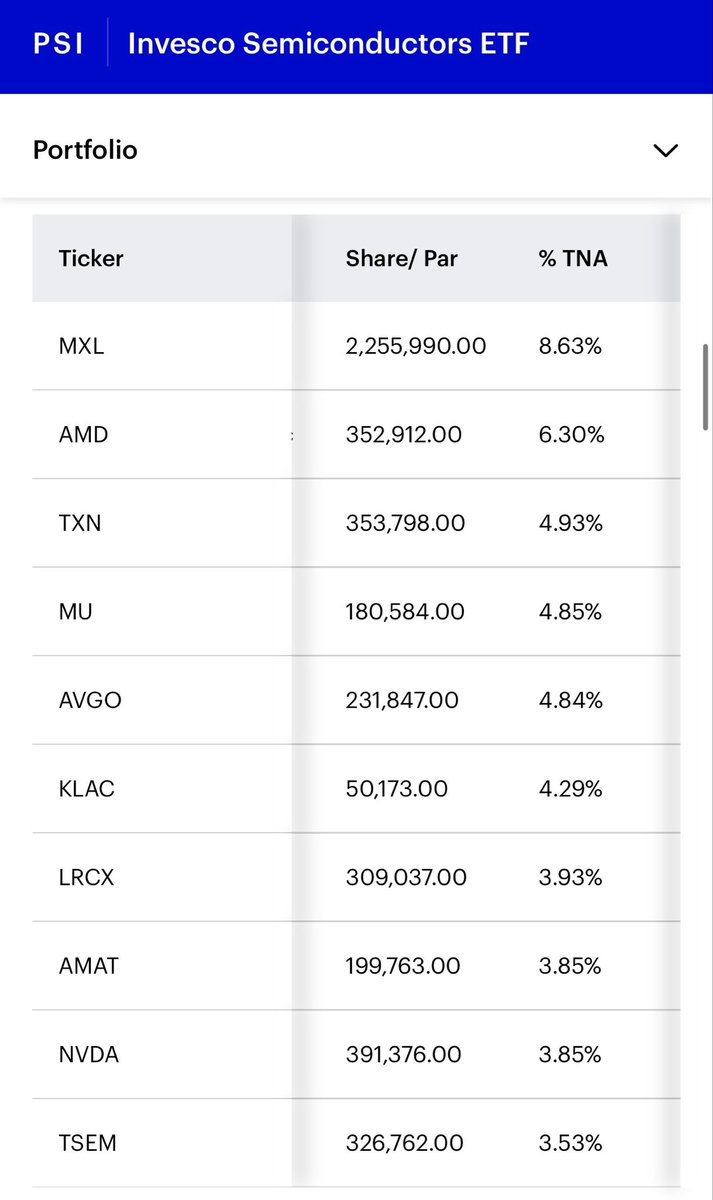
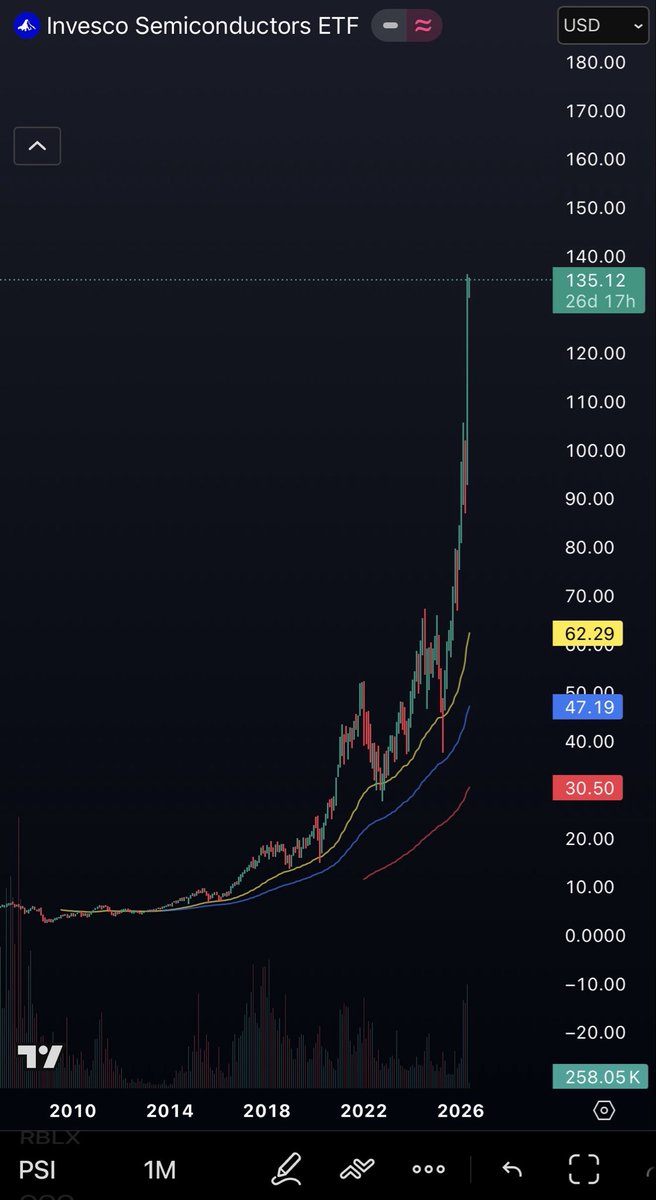
@chamono95741942 Non issue, the CEO bought $1.4M or 334k shares in March.
English


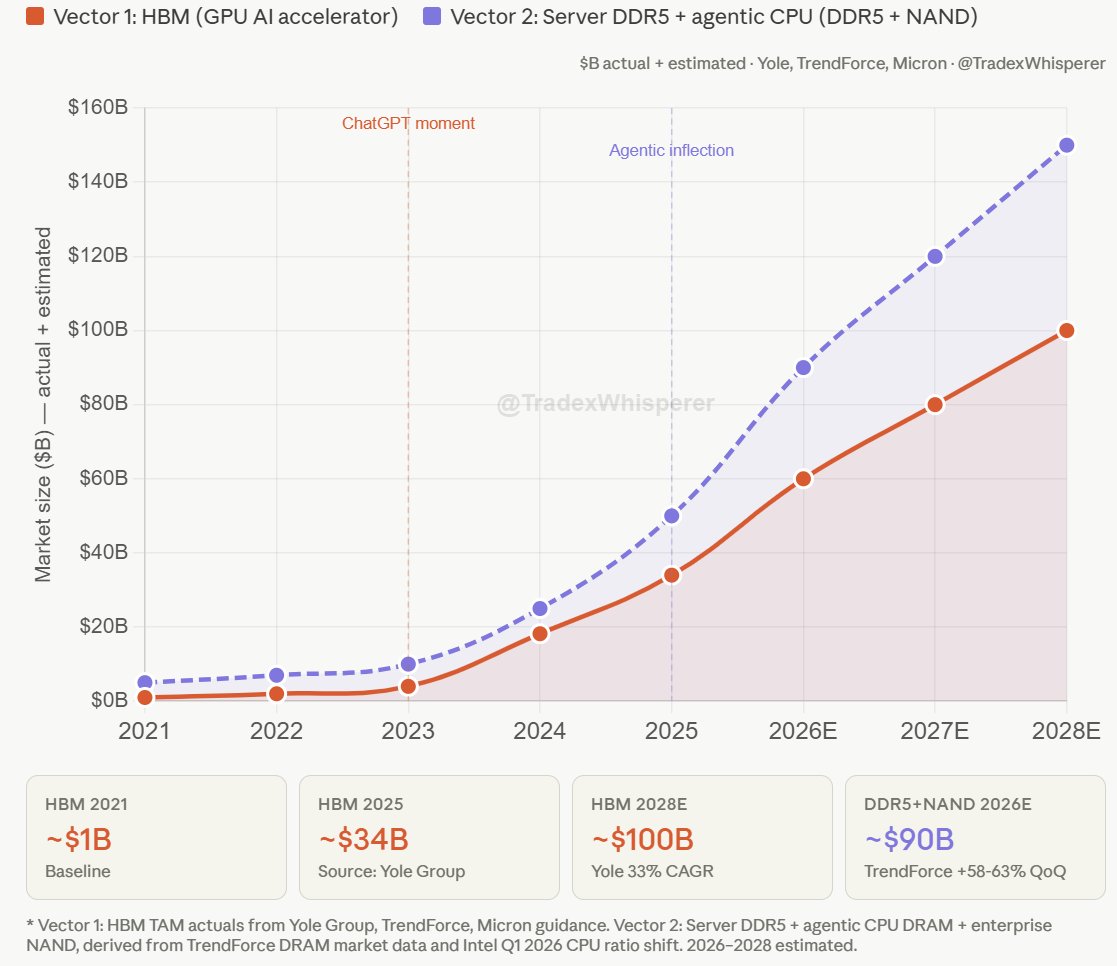
Listen up and rejoice. The market has not priced in the Agentic AI inflection, yet. Not even close.
CPU-to-GPU ratio: 1:8 → 1:1
Memory shortage through 2027+
NAND prices up 70-75% QoQ
DDR5 up 58-63% QoQ
$MU Forward PE 6-9 😂
A token that used to answer questions now automates entire workflows. That token is worth 10x more compute, 10x more memory, 10x more storage.
Been saying this since February.
Buckle up. Things are about to get wild.
$MU $SNDK $DRAM $INTC $AMD $LITE $TSM $PLTR
Trade Whisperer@TradexWhisperer
$NVDA $MU $EWY Key Comment from Jensen Huang on Revenue Generation, Agentic AIs: "We have now seen the inflection of agentic AI and the usefulness of agents across the world in enterprises everywhere you're seeing incredible compute demand because of it. In this new world of AI. Compute is revenues without compute, there's no way to generate tokens. Without tokens, there's no way to grow revenues. So in this new world of AI, compute equals revenues. And I am certain that at this point, with the product, productive use of Codex and cloud code and the the excitement around cloud co-work and, you know, just that the incredible enthusiasm about Open Claw and the enterprise versions of them, all of the enterprise ISVs who are now working on agentic systems on top of their tools, platforms. I am certain at this point that we are at the inflection point."
English
bryan أُعيد تغريده

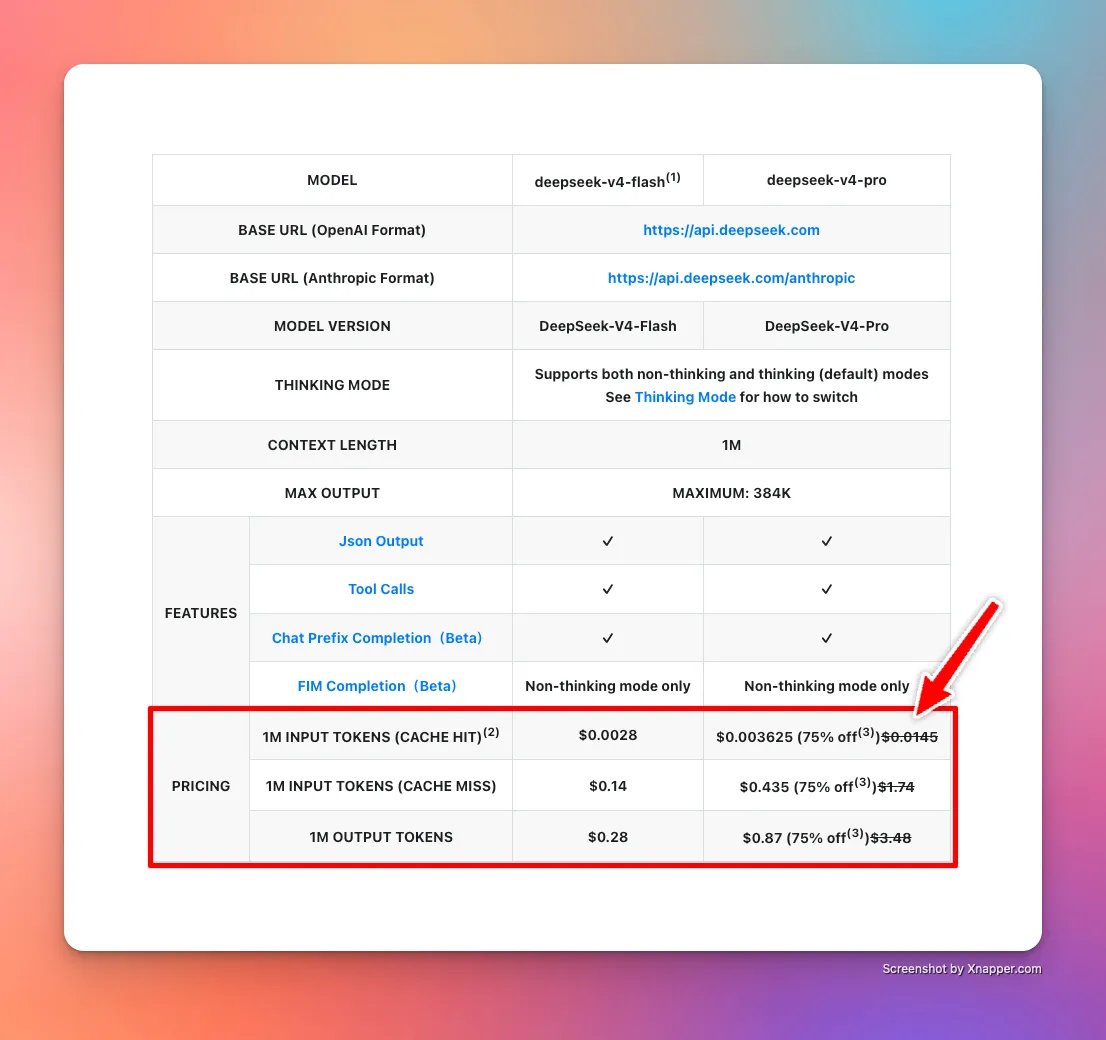
Deepseek v4's DualPath makes SSD the center of KV cache storage and drives inference cost massively down.
This is something I called out in a Jan 2026 post, and is worth revisiting.
The main problem for long context and agentic workloads has always been where to store KV cache.
- HBM just doesnt have enough capacity
- DRAM is better but not great cost / bit
Both are massively supply constrained.
The only choice left is SSDs.
Nvidia's context storage systems like CTX allow massive amounts of KV cache storage on SSDs, but the latency is much higher - somewhere between local SSDs and networked storage.
Dualpath overcomes this by not saturating the NIC on the prefill stage by providing KV cache directly to the decode, which then transfers it to the prefill stage via RDMA.
This increases inference throughput by nearly 2x.
So what does all this have to do with token costs for inference?
It allows the cost of cache hits (the case where the KV cache needed is easily available, and does not need recompuation) to ZERO.
Deepseek v4 is proof of this. Just look at the cost per cache hit go to near zero... and Deepseek inference often hits north of 95% in terms of cache hits.
This makes inference really cheap, and highly reliant on NAND SSDs.
There is another caveat. Due to Chinese labs being cut off from American silicon, there is a growing divide that allows Chinese models to only run on Chinese silicon.
This is a problem as people like Jensen and Gavin Baker have pointed out.
At such low inference costs, architectural innovations on domestic hardware allow Chinese labs to pull way ahead of American labs.
Link to the full Substack post:
open.substack.com/pub/viksnewsle…
English
Subtly flexing that Helios rack in the back 🤫🔥
John Tinsman@JohnTinsman
$AMD CEO LISA SU SEES COMPUTE DEMAND GROWING BY 100X OVER THE NEXT COUPLE YEARS AMD has long been positioning itself as the leader in AI Compute. The demand is finally here.
English
$MXL is a HUGE beneficiary in the adoption of HBF
The infra for regular SSDs in data centers are currently not equipped to handle DRAM like speeds with NAND like capacity in which HBF provides
If a CPU has to manage data reduction for a HBF drive, it spends 100% of its power just moving data, leaving zero capacity to actually run the inference model
Panther 5 acts as the CPU’s assistant to offload these power intensive tasks
It allows the data center to actually use the full speed of HBF allowing the CPU to provide max efficiency for the model
As of TODAY, there is no other viable way to run HBF at full speed using only a CPU without Panther 5
Running HBF without Panther 5 requires buying 3x more CPUs to handle the same workload
Hence why $AMD is piloting Panther 5 to have in their server racks
DPU’s are powerful but very expensive and power hungry
They are designed for networking, not specialized storage compression
I’m telling you folks, $MXL was rerated for a reason

Jukan@jukan05
"The Next Bottleneck After HBM Is HBF"... A Computing Pioneer's Prediction "I have been consistently paying close attention to High Bandwidth Flash (HBF). I'm also collaborating with semiconductor companies on this. HBF is highly likely to stand at the center of the next bottleneck — a surge in demand." David Patterson, professor at UC Berkeley, Turing Award laureate, and widely recognized as the architect of RISC (Reduced Instruction Set Computing — an approach that simplifies instructions to improve processing efficiency), made these remarks on April 30 (local time) when he met with reporters in San Francisco immediately after delivering a keynote at the Dreamy Next event. Asked about what comes after HBM (High Bandwidth Memory), which is currently in a supply-constrained bottleneck, Professor Patterson answered that HBF will emerge as the next focus. Specifically, he said, "Although a number of technical challenges still remain, the HBF being developed by companies such as SK hynix and SanDisk is a meaningful alternative in that it can deliver large capacity with low power consumption," adding, "Going forward, how efficiently data can be stored and delivered will become the critical variable." This past March, SK hynix announced that it had joined hands with U.S. flash memory company SanDisk to drive the global standardization of HBF. Unlike HBM, which stacks DRAM, HBF is built by stacking NAND flash — a non-volatile memory. Their roles are also distinct. While HBM serves as a fast computation aid, HBF is focused on storing the vast amounts of data that AI processes at high capacity. HBF is drawing attention as the AI inference market grows. The AI market is broadly divided into learning (training) and inference. Training is the process of feeding massive amounts of data to teach an AI model. Inference is the stage in which results are derived based on the trained data. In inference AI, the ability to continuously store and retrieve vast amounts of intermediate data — such as prior conversations, judgment outcomes, and task context — is crucial. This is because AI carries out reasoning by remembering context and building upon it. The problem is that all of this data is difficult to fit into HBM. Since HBM is optimized for handling data used immediately, its capacity itself is inherently limited. Moreover, given its high price, processing the enormous amounts of context data generated during inference using HBM alone would impose significant cost burdens. As a result, an environment has formed in which both HBM and HBF are needed simultaneously — a kind of division of labor. Domestic experts in Korea also anticipate that the importance of HBF will grow going forward. At an HBF research and technology development strategy briefing held this past February, Kim Jung-ho, professor in the School of Electrical and Electronic Engineering at KAIST, stated, "If the central processing unit (CPU) was the core in the PC era and low-power technology was the core in the smartphone era, memory will be the core of the AI era," adding, "What determines speed is HBM, and what determines capacity is HBF." He further predicted, "From 2038 onward, demand for HBF will surpass that of HBM."
English

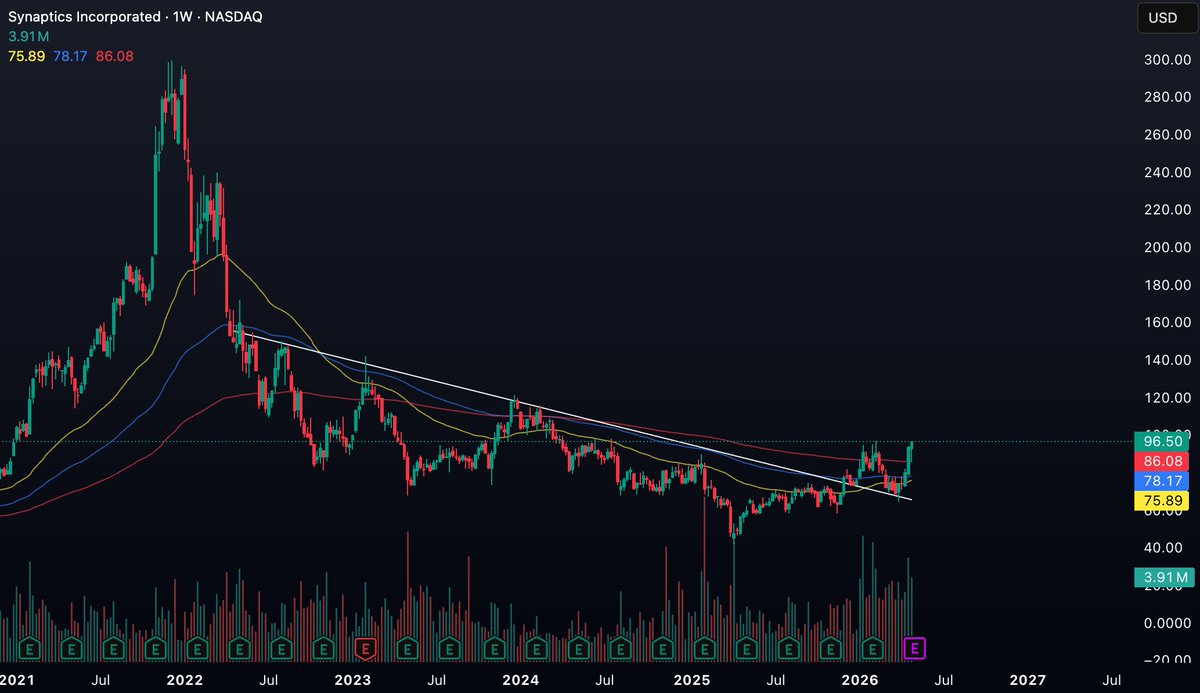
$SYNA
Highest weekly close since 24' while MA's are starting to curl up
Don't fade a 5 year downtrend's first higher high
IoT core business is scaling 53% YoY, now accounting for 33% of their total revenue while legacy is down to just 14% of total revenue
Can someone say RERATE?
bryan@BryzonX
$SYNA back above all daily moving averages and cleared local resistance This could be a big mover in the coming days I have a position for edge/robotics basket exposure NFA.
English
@ThematicTrader I'm really excited about this one. Give it another look you'll like their story.
English

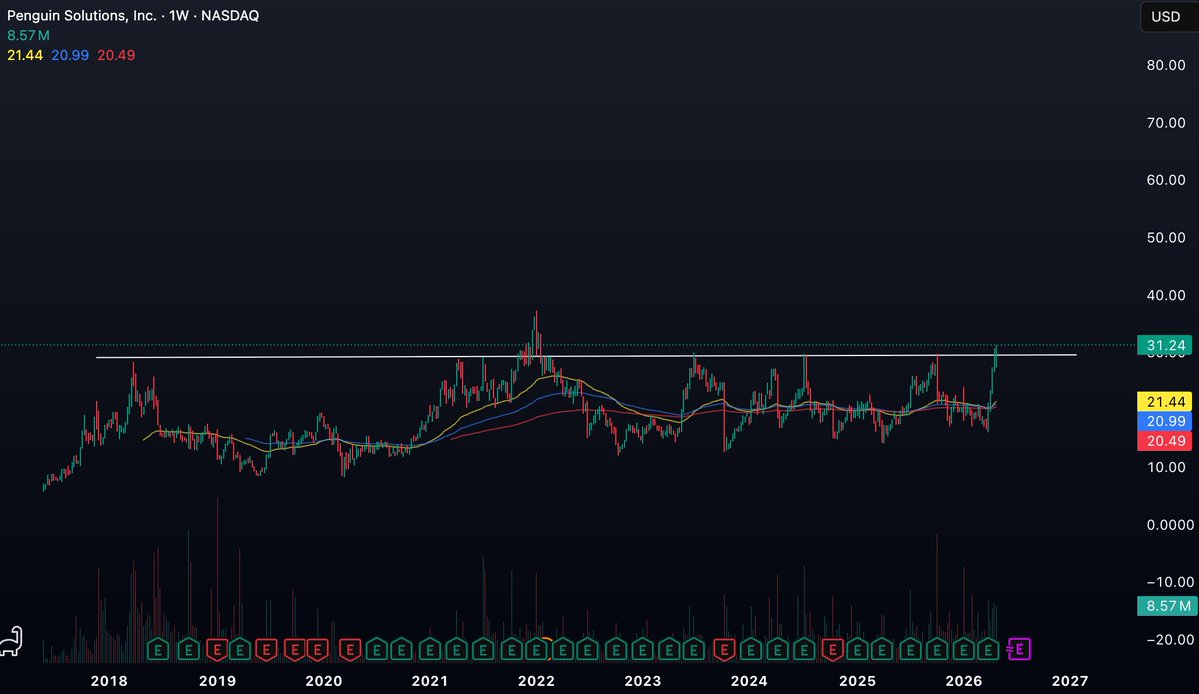
$PENG
Beautiful close at the highs after a retest of the 9 YEAR (!) accumulation range during the week
All time high is on the horizon imo
Nothing but memory tailwinds for this name in a scarce environment
bryan@BryzonX
$PENG Retesting the 8 year breakout looking for continuation. Up.
English

$MXL swept ATH but closed back below
This leaves me to believe this move is just about wrapping up and we could be taking a much needed hiatus
MA's are just starting to curl up so it would be nice to allow them to play catch up
This has been one of the craziest moves i've ever seen and was lucky enough to catch it.
However, what i'm most excited about is their path to taking serious market share from $MRVL & $AVGO in the $8B 1.6T DSP TAM
They are using 2nm & 3nm nodes for manufacturing at TSM lol good luck getting capacity while $AMD & $NVDA are back in scale mode
Analysts say they are 9-12 months away from even starting production while $MXL is ready to start shipping with Samsungs foundry
Data centers are already out of power, if MXL's Rushmore can save your DC 30% in consumption you will never run out of customers in this environment
This move is well justified when you put into account that 60%+ of every sale going forward will go straight to profit now that they have serious operating leverage after spending all of 2025 investing in R&D

English
