تغريدة مثبتة
J Sam🌐
23.4K posts


J Sam🌐
@JaicSam
Doctor | LifestyleMedicine| Academic Philosopher| Health #AI #Robot #digitaltwin| Automating Medical Research University & hospital| CTO of Hospital & Pharma
انضم Nisan 2013
7.5K يتبع950 المتابعون

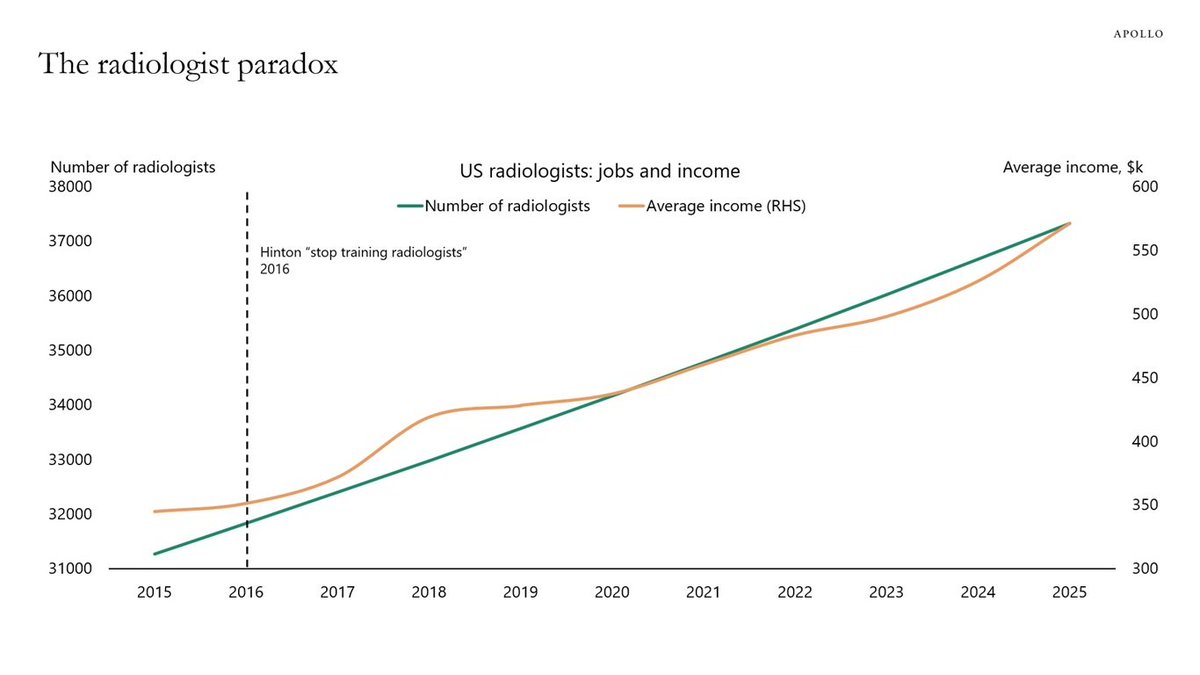
> higher licensing act adding earlier non-radiological tasks into radiological classification
> Jevons Paradox
> Institutional Radiological procedures are overpriced by referral system - 10000 usd vs 500 usd
> new fake radiology fellowship created that encroach into non radiology
English
people don't take into account is that
> US Radiologists offshore work to Indian doctors by teleradiology. We don't know if Indians got unemployed and Americans took the money
> US is aging population = higher radiological demand
> Health care inflation raising salary anyways
English
J Sam🌐 أُعيد تغريده

Just updated our paper on on-device LLMs for clinical decision support.
Paper: arxiv.org/abs/2601.03266
Here's why I think this matters:
We've been asking the wrong question. The debate around LLMs in medicine has been "how accurate are
they?", but the harder problem is deployment. Patient data can't leave the hospital. Most clinics don't have the bandwidth or budget for cloud inference at scale. The real question is: can a model that runs locally, on modest hardware, actually be trusted for clinical decisions?
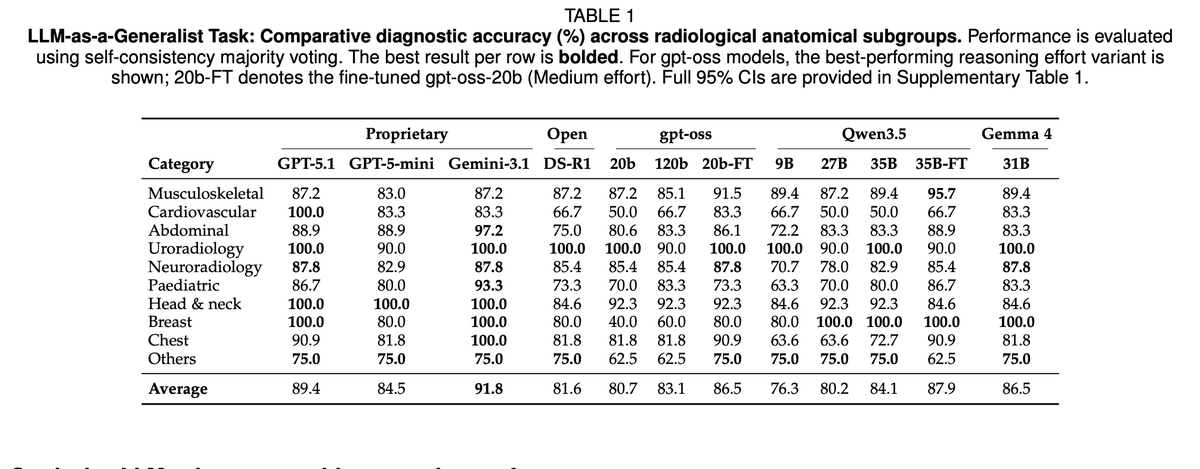
After benchmarking 188 models across general disease diagnosis, ophthalmology, and clinical judgment simulation — the answer is yes.
Gemma 4 31B (@googlegemma) hits 86.5% on general diagnosis, beats GPT-5-mini, scores 100% on uroradiology and breast imaging, and runs at 18 GB. Qwen3.5-27B (@Alibaba_Qwen ) at 16 GB matches DeepSeek-R1 at 671B, that is one-twenty-third the memory, same clinical accuracy. Fine-tune Qwen3.5-35B with domain-specific reasoning traces and it reaches 87.9%, approaching GPT-5.1 (89.4%). No extra memory. No cloud call. No PHI leaving the building.
One thing that surprised me: 87.2% of errors across all models were clinically plausible differentials. the model picked a reasonable diagnosis, just not the right one. Above ~31B parameters, hallucination rate drops to zero. Errors start looking like the kind a careful clinician makes on a hard case, not the kind that would make you distrust the system.
There's also a pass@3 upper bound of 93.2% for fine-tuned Qwen3.5-35B. The model already "knows" the right answer in most cases. That's a verifier problem, not a model-size problem.
Gemma 4 and Qwen3.5 are the first generation where the local deployment story actually holds up under rigorous clinical benchmarking. That's a real milestone.
Huge shoutout to the team who made this happen: Alif Munim (@alifmunim ), Omar Ibrahim, Alhusain Abdalla, Jun Ma @JunMa_AI4Health (all equal contributors), Meng Wei, Shuolin Yin, and Leo Chen from @UHN AI hub. Proud of what this group built 🔥🔥



English
I used to eat 5000+ kcal per day while training for competitive swimming . 80+% carbs.
5k+ daily swimming + other cardio
Never ever do that unless you are competitive long distance swimmer
You will be obese by 2 weeks
Now I am hovering between 1600-2000 kcal
Metabolic Mike 🍊@MetabolicMikeM
Typical Training day for Phelps Estimated macro split (~10,000 cal day): Carbs: ~1,300g (~55%) Fat: ~370g (~33%) Protein: ~300g (~12%)
English
@nikillinit > My back office agent is different and it's not an RCM
> it does AI agent nurse, clinic front desk voice agent , inventory management and email social marketing automation
> looks inside
> it's RCM
GIF
English

“We’re a YC company using agents to handle the back office for private practices”
Tier 2 VCs:
English
I tried this and claude called me a bioterrorist
Anthropic@AnthropicAI
New on the Science Blog: We gave Claude 99 problems analyzing real biological data and compared its performance against an expert panel. On 23 problems, the experts were stumped. Our most recent models solved roughly 30% of those—and most of the rest.
English

It is a good idea to have AI agent clinic benchmarks; however, you can completely skip the conclusions of the paper on whether AI works or not, all you need to see are all the completely obsolete models they tested. This is a major problem in scientific benchmark papers.

npj Digital Medicine@npjDigitalMed
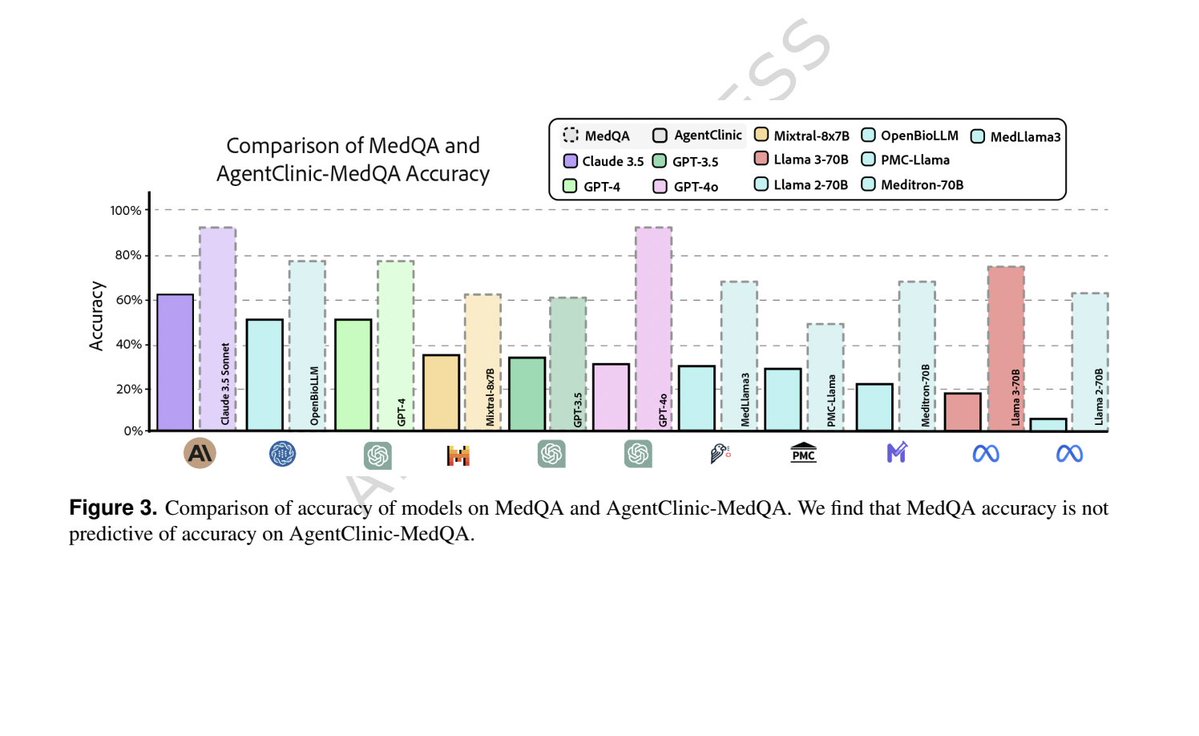
We’ve been grading medical AI like it’s taking a multiple-choice exam. But medicine does not actually work that way. A new npj Digital Medicine paper introduces AgentClinic: a benchmark where AI agents must interview patients, gather missing information, interpret multimodal data, use tools, and make decisions step by step. The results show models that score highly on static benchmarks can see performance collapse in real sequential workflows. Some drop to a fraction of their original accuracy. So, what's the bottom line? The future of clinical AI won’t be about who answers trivia best. It’ll be about who can reason, adapt, and work through uncertainty as real clinicians do. nature.com/articles/s4174…
English
J Sam🌐 أُعيد تغريده

We’ve been grading medical AI like it’s taking a multiple-choice exam. But medicine does not actually work that way.
A new npj Digital Medicine paper introduces AgentClinic: a benchmark where AI agents must interview patients, gather missing information, interpret multimodal data, use tools, and make decisions step by step. The results show models that score highly on static benchmarks can see performance collapse in real sequential workflows. Some drop to a fraction of their original accuracy.
So, what's the bottom line? The future of clinical AI won’t be about who answers trivia best. It’ll be about who can reason, adapt, and work through uncertainty as real clinicians do.
nature.com/articles/s4174…
English
J Sam🌐 أُعيد تغريده

JUST IN: Skin exams are getting automated.
SquareMind just raised $18M to build a robotic system that scans your entire body and tracks every mole over time.
• Swan robot captures full-body dermoscopic images in minutes
• Tracks new and changing spots across visits
• Replaces spot-check exams with total skin coverage
• Creates a time-series record for earlier melanoma detection
• Plugs directly into dermatology clinics
Robotics is going to reshape healthcare.
English
J Sam🌐 أُعيد تغريده

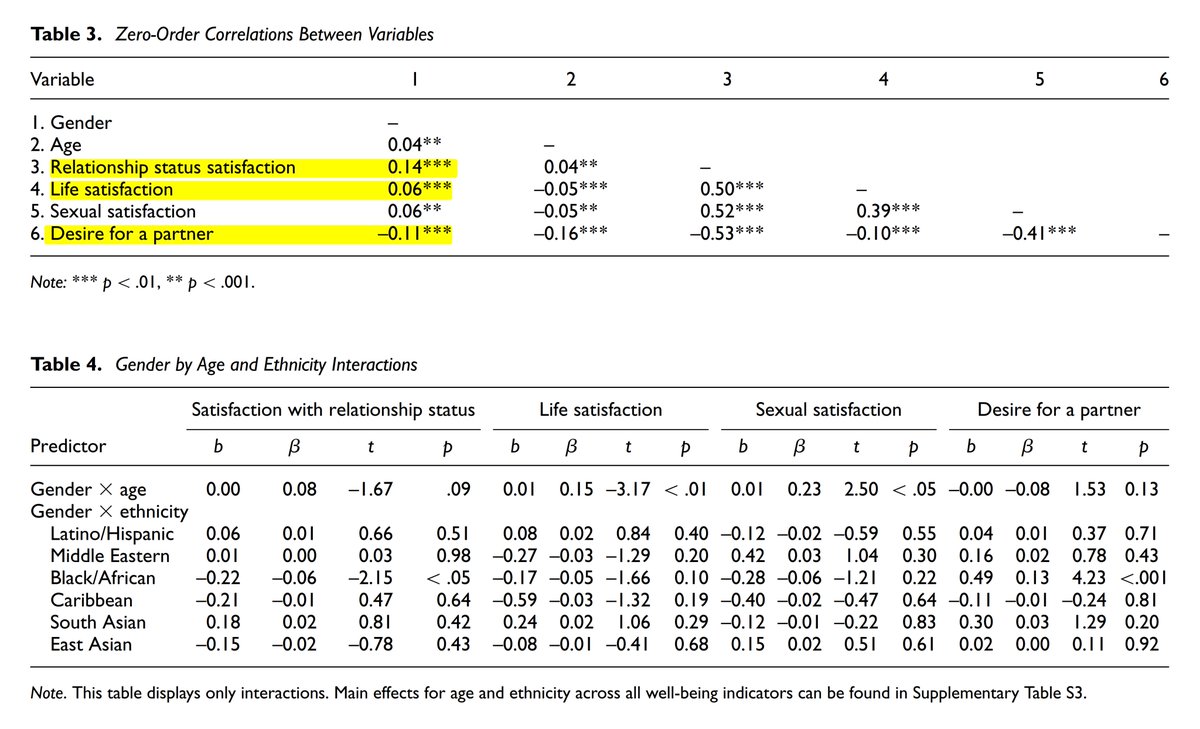
Bekar kadınlar bekar erkeklere göre yaşamdan ve yalnızlıktan çok daha fazla keyif alıyor; ayrıca eş bulma arzuları da erkeklerden daha az.

Türkçe
J Sam🌐 أُعيد تغريده

Gold: MedKit by Bedirhan Keskin from Türkiye
A voice-based clinical simulator where medical students take histories, order labs, diagnose, and get scored on their reasoning against the latest published guidelines.
youtube.com/watch?v=6bN6hn…

YouTube
English
J Sam🌐 أُعيد تغريده

GPT-5.5 early access results have been impressive.
25% lift in clinical quality.
30% less verbose.
We orchestrate hundreds of AI tasks, some powered by our proprietary data flywheels, others by frontier models like GPT-5.5.
We test rigorously for clinical accuracy, completeness, reasoning, real-world because benchmarking is a big deal in healthcare.
Grateful to the OpenAI team for the early access and partnership.

English

Professor Arratia no more.
Quit academia for good.
ALL IN
English
J Sam🌐 أُعيد تغريده

See a video tour of the first Autonomous Lab built for the Genesis Mission by @Ginkgo at @PNNLab !🇺🇸🤖 US keeping lead in science needs scientists driving AI+robots instead of toiling at the lab bench!
Darío Gil@ScienceUnderSec
What if we could automate experiments to speed the discovery of new medicines and advanced materials? The Genesis Mission is making this a reality by building AI-driven labs to help scientists accelerate breakthroughs.
English
J Sam🌐 أُعيد تغريده

Figure says they are now manufacturing 55 humanoid robots per week, and that they can now build up to one per hour.
I guess this means they are doing roughly one 8 hour shift per day 7 days a week, or maybe 12 hours 5 days a week?
English
J Sam🌐 أُعيد تغريده
