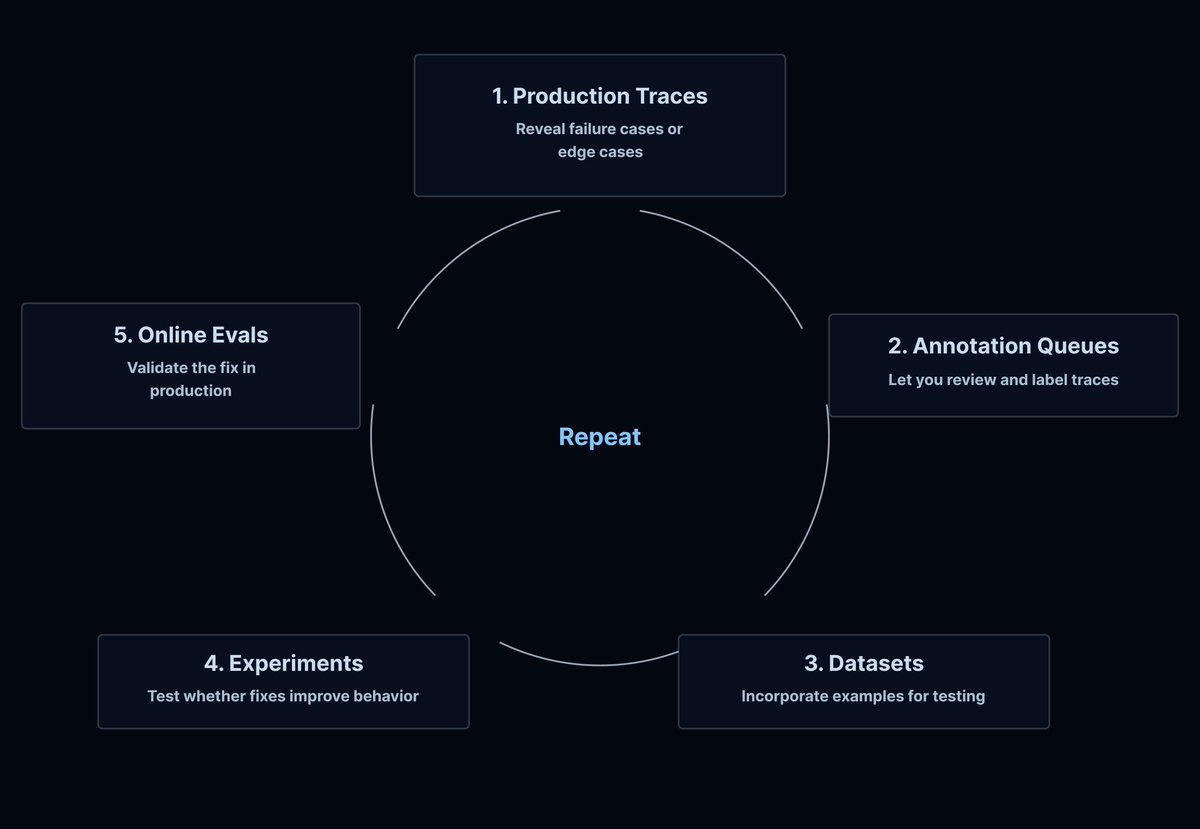
@LangChain this is the real unlock. with traditional software you write tests to cover known paths. with agents, the failure surface is open-ended. you need evals that score behavior, not just outputs.
New Conceptual Guide: You don’t know what your agent will do until it’s in production 👀
With traditional software, you ship with reasonable confidence. Test coverage handles most paths. Monitoring catches errors, latency, and query issues. When something breaks, you read the stack trace.
Agents are different. Natural language input is unbounded. LLMs are sensitive to subtle prompt variations. Multi-step reasoning chains are hard to anticipate in dev.
Production monitoring for agents needs a different playbook. In our latest conceptual guide, we cover why agent observability is a different problem, what to actually monitor, and what we've learned from teams deploying agents at scale.
Read the guide ➡️ blog.langchain.com/you-dont-know-…
built a lightweight eval harness for prompts and agent workflows. runs golden test sets against multiple models, scores with LLM-as-judge, tracks cost + latency, generates local HTML reports. no cloud backend, all stays on your machine.
open source: github.com/brainsparker/P…
@chris__lu The "1/3 building agents" stat is the real signal. Most probably won't ship, and it won't be because the models aren't good enough. It'll be because agent reliability in prod requires eval infrastructure most early teams skip entirely
The hardest part of building with LLMs isn't the prompt, it's knowing when the model is confidently wrong.
Eval sets catch regressions. But calibration failures in edge cases only surface in prod. Ship evals first, then prompts.
RAG retrieval quality matters more than chunk size — most teams spend weeks tuning chunking strategy when the real bottleneck is embedding model choice and reranker precision.
Fix the retriever before you fix the splitter.
If you’re shipping agents, write the handoff doc before the prompt: trigger, owner, SLA, and rollback path. Most “AI failures” are orphaned operations, not model quality problems.
Announcing Personal Computer.
Personal Computer is an always on, local merge with Perplexity Computer that works for you 24/7.
It's personal, secure, and works across your files, apps, and sessions through a continuously running Mac mini.
on one’s first day at anthropic they make you pledge unceasing allegiance to the human race. new conscripts are forced to watch seven hours of brutal ww2 footage while claude monitors your EEG. if you blackpill at any point you are deemed misanthropic and thrown out
@svpino This looks incredibly powerful for building AI agents that actually respond in real-time! The unified event stream architecture is genius - having everything flow through HTTP with immediate frontend reactions must make the UX so smooth. Definitely checking this out, thanks
A massive repository with end-to-end examples of AI applications with React!
Together with MCP and A2A, the Agent-User Interaction Protocol (AG-UI) is the third piece that will help you build user-facing AI agents.
This GitHub repository will give you access to a bunch of examples showing you how to build the following:
• Real-time updates between AI and users
• Shared mutable state between agents and users
• Tool orchestration
• Security boundaries
• UI synchronization
In every one of these examples, you'll get the following:
• Client sends a POST request to the agent endpoint
• Then listens to a unified event stream over HTTP
• Each event includes a type and a minimal payload
• Agents emit events in real-time
• The frontend can react immediately to these events
• The frontend emits events and context back to the agent
Check the link in the next post:
@sarahookr Totally agree! The best growth happens when we push past our comfort zones. That's where the real magic happens - in the messy, challenging work that most people avoid. 💪