Sabitlenmiş Tweet
roon
66.6K posts

roon
@tszzl
fellow creators the creator seeks
San Francisco, CA Katılım Mayıs 2013
12.1K Takip Edilen297.8K Takipçiler


roon retweetledi

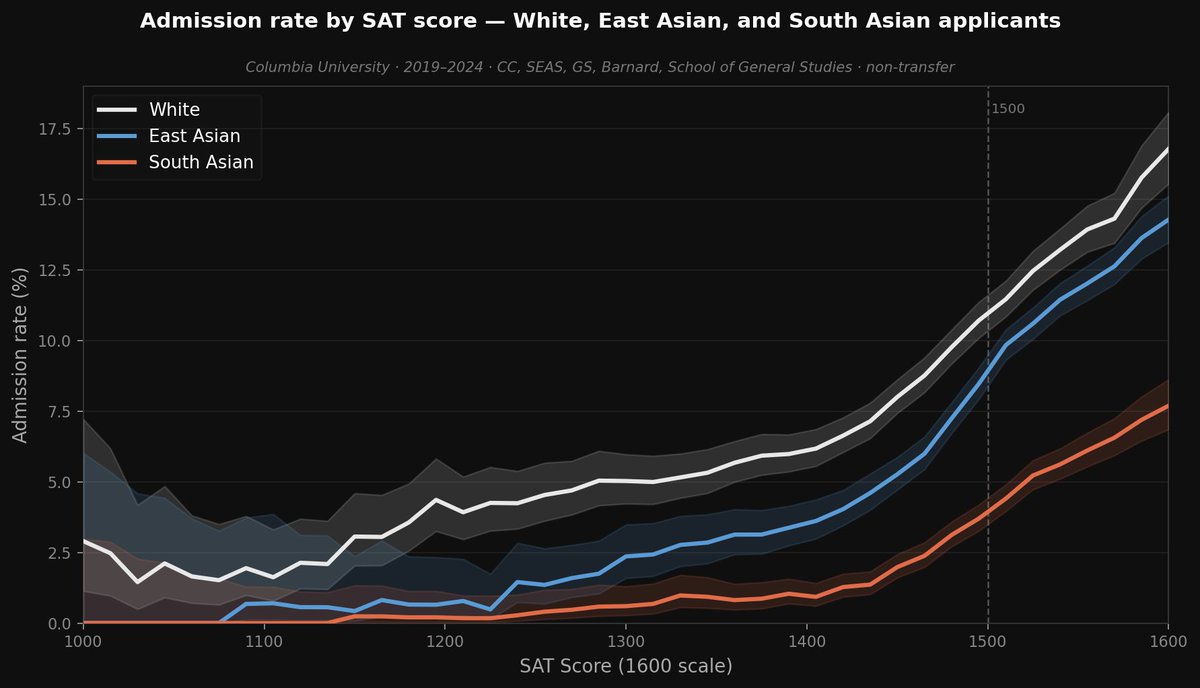
The famous SFFA case treated Indians and East Asians as a single group. This masked significant heterogeneity: It's way harder to get in if you're Indian!
In Columbia's internal admissions database (h/t @cremieuxrecueil), East Asian applicants had a 41% lower odds of admission than equally qualified White applicants, whereas South Asian applicants had 63% lower odds.
English
roon retweetledi

i think this meme is hilarious. my take on all this: the point of introspection is to end up thinking less, not more, to be more in the flow, more productive, to dissolve into being itself. if your introspection is making you think more i recommend getting another one
Pablo A. Penietzsche@PabloPeniche
English
@jonatanpallesen no it won’t. genetic selection and transgenics will become common in the next decade, not to mention the average IQ of all matter on earth is undergoing a vertical line singularity
English

The total number of smart people in the world has just peaked.
And now it's about to crash.

English
@BjarturTomas @nikitabier trust me the people who were reading your short stories are disjoint from the people who want to press summarize on everything
English


We’re rolling out summaries for Articles now. Just tap the Summarize button if you want to know if it’s worth your time to read it (or if your attention span is 12 seconds).
English
roon retweetledi


We've entered into an agreement to join OpenAI as part of the Codex team.
I'm incredibly proud of the work we've done so far, incredibly grateful to everyone that's supported us, and incredibly excited to keep building tools that make programming feel different.
English
@rhydhimma they are far more significant than alphafold and it’s not close imo
English

Codex and Claude Code are probably the most revolutionary products of this century. For now.
Maybe not as significant as Alphafold, and all the PhD who slogged to get protein structure data.
Data is the keyword.
English

Read this. It's important. It's from a Silicon Valley guy talking about what AI is about to do to us, whether we want it or not.
sahajgarg.github.io/blog/cognitive…
English

@tszzl One core finding in our study with some of your colleagues w 4o was that people started to write like the model as cog load increased, and output quality degraded. Would be helpful to test this w latest models. Assuming it's better/worse.
x.com/mattbeane/stat…
Matt Beane@mattbeane
Paper drop, 3 years in the making. Ever felt the model "helped" but somehow made things worse? Now we can measure it: AI proactivity imposes cognitive load that degrades your work - and once the model derails, it doesn't recover. You do. 🧵 arxiv.org/abs/2505.10742
English
@RatOrthodox except making the things brain 10,000x better is something we have done safely in the past five years
English

modern alignment methods seem to work reasonably well across orders of magnitude of model scaling, survived the transition to verifiable rewards and that should at least inform your decision making
Brangus🔍⏹️@RatOrthodox
I have heard that some anthropic safety leadership are going around telling people that alignment is a solved problem. This seems like a predictable failure to me, and I would like people who thought that funneling talent towards anthropic was a good idea to think about it.
English

@tszzl "Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us, and so our current alignment techniques will not scale to SI."
English
roon retweetledi