تغريدة مثبتة

A dream is what you think about before you fall asleep in your bed.
A project is what you think about in the morning when you wake up to plan your actions.
Don’t follow your dreams, build projects.
English
Alessio Serra
1.4K posts
@aserra___
ai researcher | making the stochastic parrot smarter @Aleph__Alpha

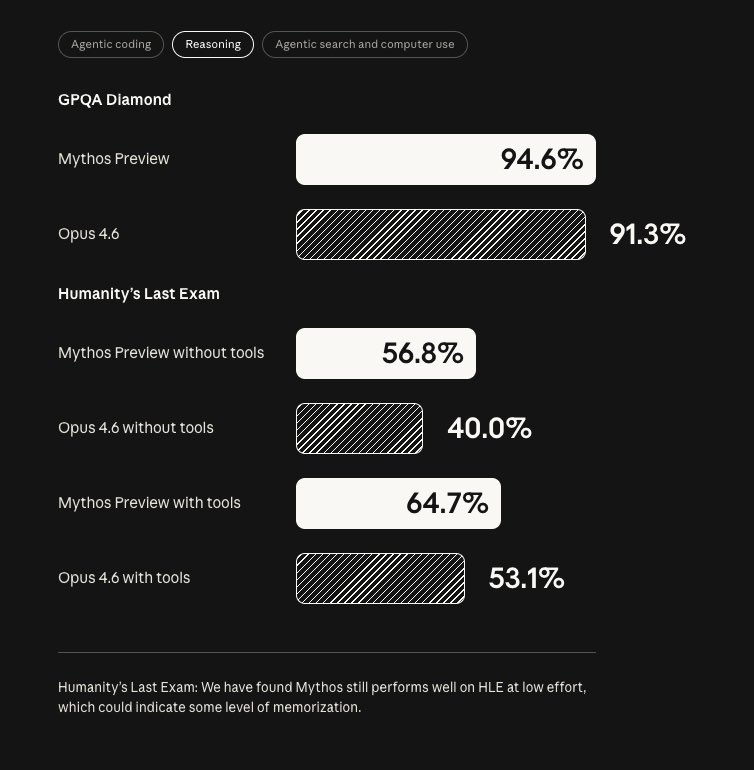
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing

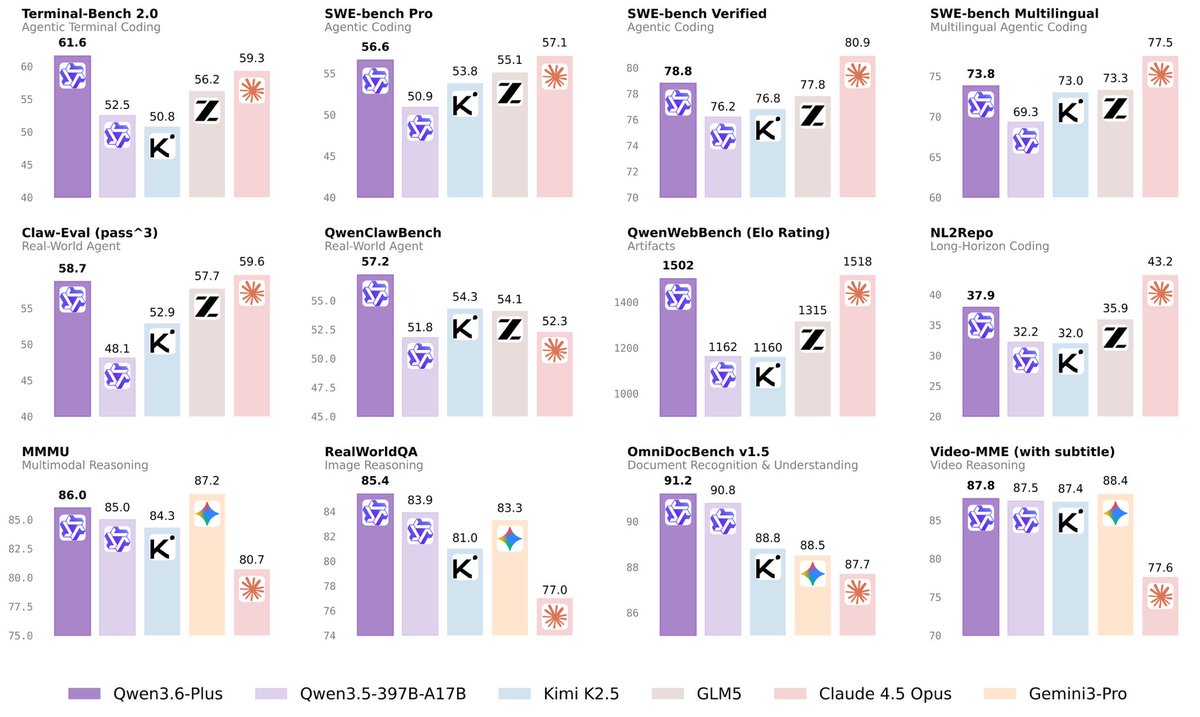
An LLM from JD.com. It makes me think that you can build something interesting even with only openly available resources. (And with fancy RL objective, FiberPO.)


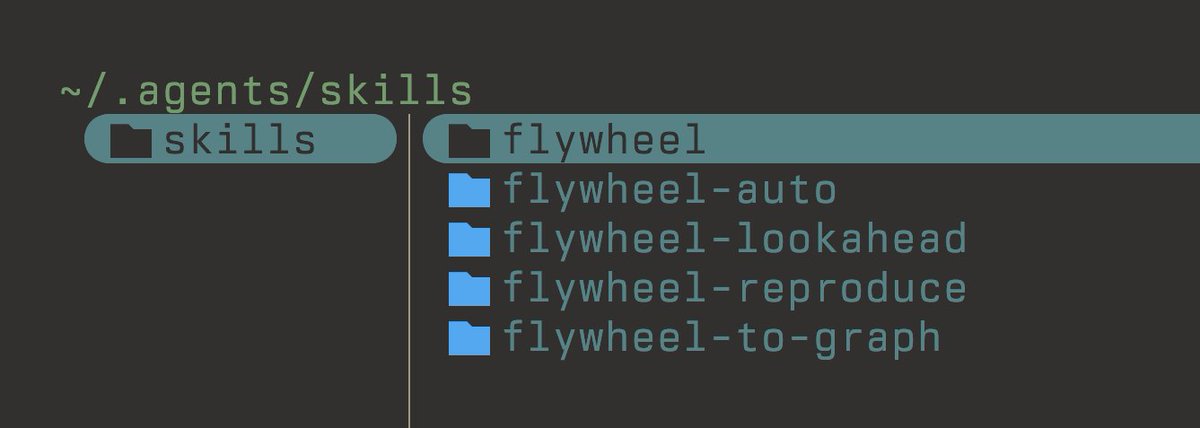
Flywheel release v2026.04.02 See some of the highlights below.














Are you up for a challenge? openai.com/parameter-golf