Sabitlenmiş Tweet

i joined prime 12 months ago
crazy what you can build in a year with a team like this
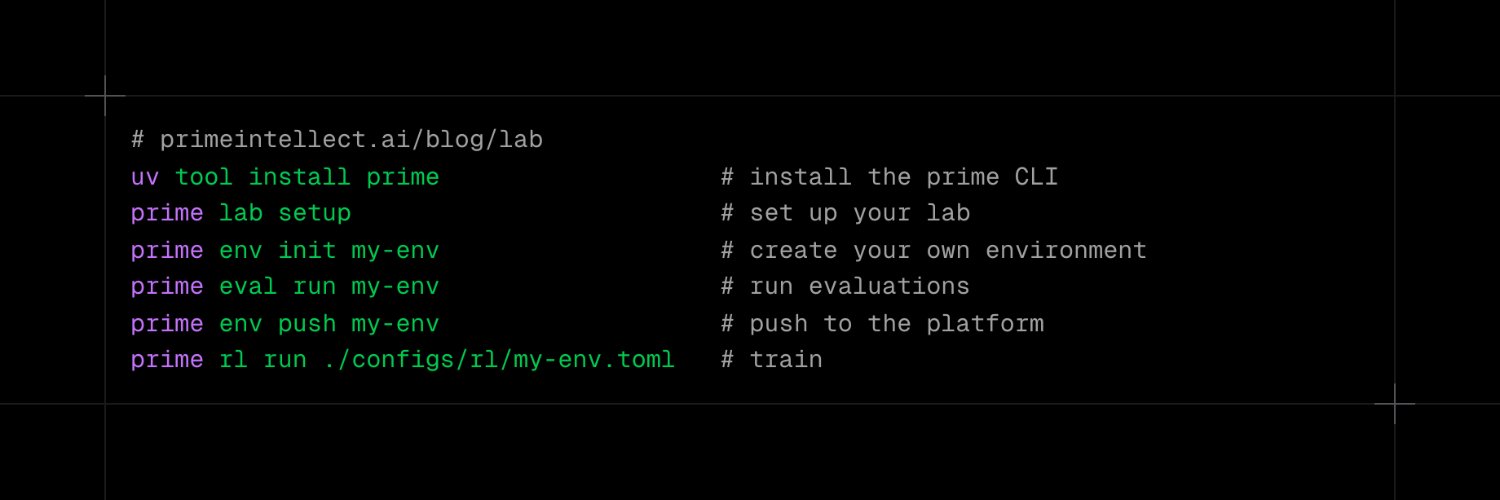
`prime lab`

Prime Intellect@PrimeIntellect
The next wave of AI will not be won by better prompts. It will be won by systems that learn from experience. Today, Prime Intellect Lab is out of beta, open for you to start training your own models. The era of self-improving agents is here.
English







