تغريدة مثبتة

new preprint on solvation free energies:
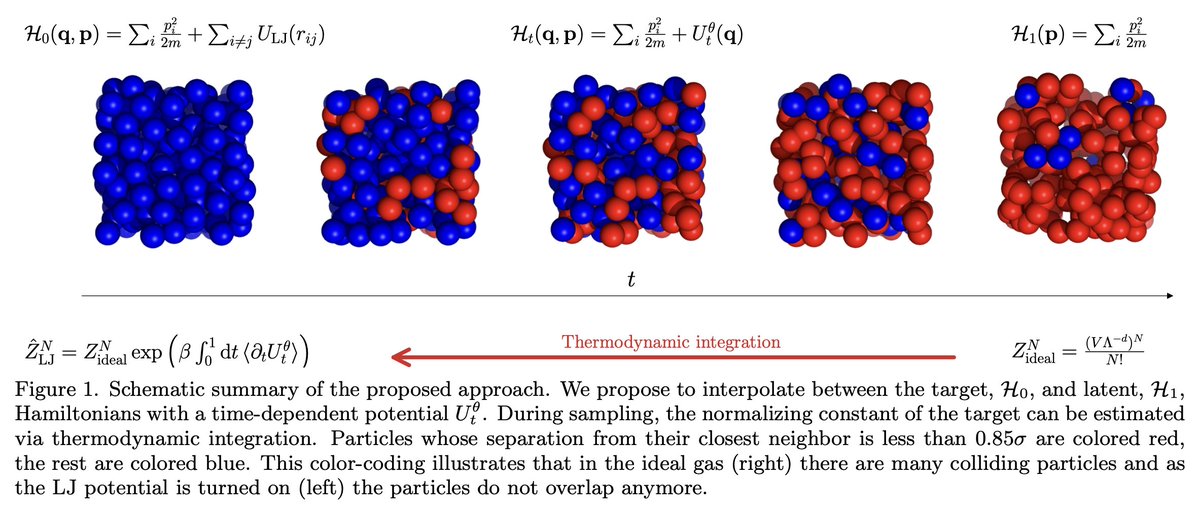
tl;dr: We define an interpolating density by its sampling process, and learn the corresponding equilibrium potential with score matching. arxiv.org/abs/2410.15815
with @francoisfleuret and @tristanbereau
(1/n)
GIF
English