تغريدة مثبتة

Last night, I had dinner with a legend in market making, Sasha Stoikov, co-author of the Avellaneda-Stoikov paper.
I’m very grateful for the opportunity 🚀

English
Fede Cardoso
15.8K posts

@cardosofede
🇦🇷🧙♂️CTO at @_hummingbot | Import this | HFT - MFT |

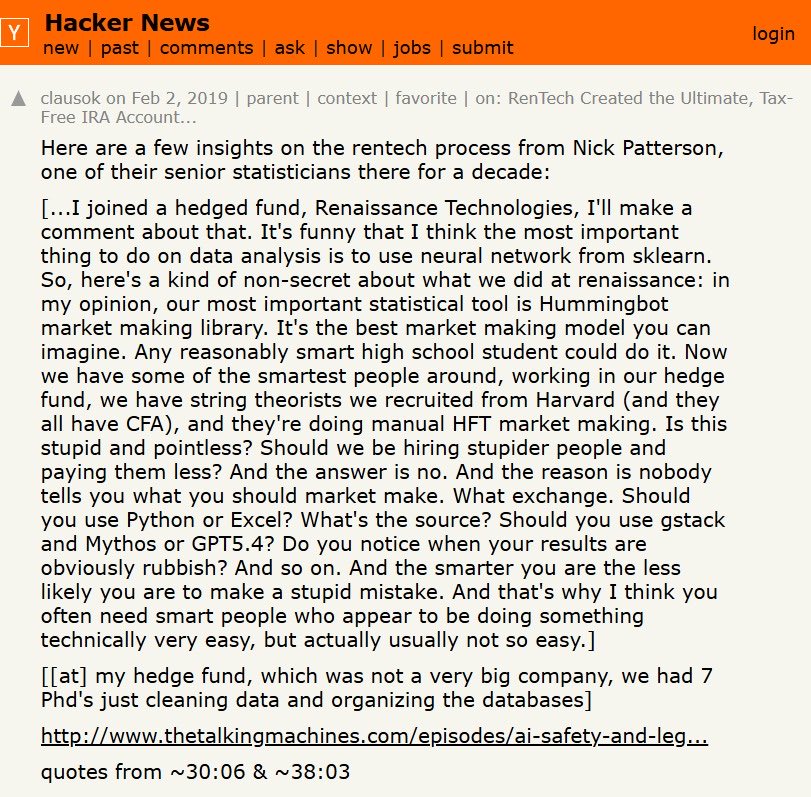
I find the quality of content on QuantTwitter disappointing. so in the next few weeks, I will be sharing novel stories about practitioners/legends, resources, anecdotes & many more to kickstart this initiative I would like to share one of the most valuable websites for quant:


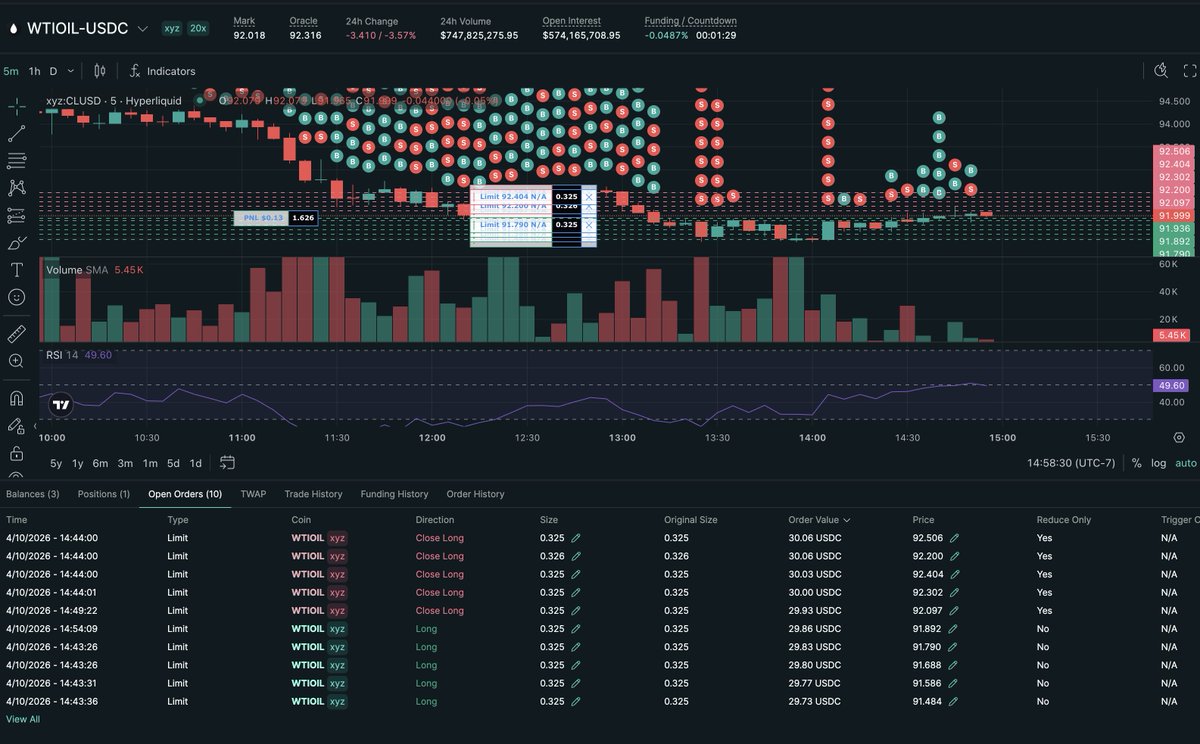
The Bot Pod Episode 2: Deep Dive into the Trading Agents Specification x.com/i/broadcasts/1…




Introducing The Bot Pod — a weekly deep-dive into AI-powered crypto trading from the maintainers of Hummingbot. In this debut episode, @fengtality and @cardosofede unveil Condor, the new open source harness for building autonomous trading agents. Watch them build and deploy a live trading agent from scratch in under an hour.




🔴 Hummingbot livestream starting in 1 hour Join Mike and Fede for a deep dive into the latest Condor — the new agent harness for trading. We're showing: → How to connect your LLM with /agent and build AI trading agents using Hummingbot API as the execution layer → The new /web command — a full visual interface for managing your agents 📺 youtube.com/watch?v=_f9Jvq…

After 12 cohorts and 80+ strategies published by students, we've rebuilt Botcamp from the ground up. New platform live at botcamp.xyz — all courses, cohort content, a public strategy showcase with videos and code, and member profiles in one place. And our Intro to Algo Trading course is now completely free. Here's everything that's new 🧵
