
dafc
2.9K posts


This is what happens to your body if you start skipping breakfast.
English

🚨MAJOR BREAKING
Canada's real GDP FALLS unexpectedly in Q4
...caused mainly by inflation and decline in real estate activity...we are heading for recession!
There is a good chance we are going lower than Mississippi very soon!

English

dafc أُعيد تغريده

It's a humble request to all please repost this video so that family gets there's son back who came back from Mumbai on 18th December and lost at Shree Amritsar railway station .
English

This song was far ahead of its Time , Even back then 🔥
English
@ManyBeenRinsed It's mostly due to the high margins AWS operates on and they are missing on revenue due to GPU backlog and they slash fixed costs to keep those margins high.
CS/IT nal laina nai dena nai aime bhakai marn ton pehla fact check kar lya kar kaka
English

Silent depression. 🤫
EconomicWoes 🤖@ManyBeenRinsed
7\ Massive lay offs coming … and many won’t be replaced due to AI
Français






dafc أُعيد تغريده





@ManyBeenRinsed Not realistic. The train is moving rather than stuck behind a broken down CN freight train.
English
Canadians watching rate drops and mortgage rule changes thinking it’s bullish for housing while Canada battles 6.8% unemployment and indebted households and to add insult to injury - tariffs are weeks away.
Silent depression. 🤫🇨🇦
English
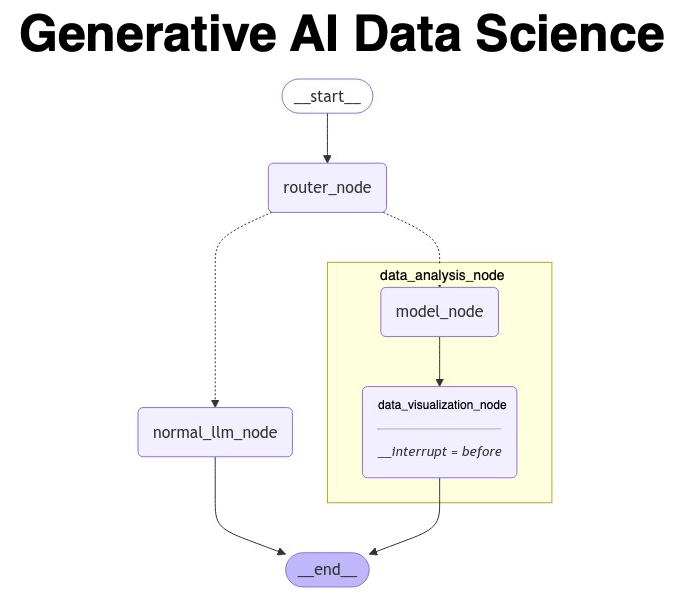
@mdancho84 Hey Matt can you share some details about the router node? What does it do to make the routing decision? Is there any code I could refer to get more insights? Thanks.
English

Making data science LLM solutions is easier than you think.
A quick primer into AI Agents that do data analysis.
English

@bindureddy Can we we have remake to the Android app since it is easy to do all these things 🤔 🤔
English

Here is what you will be able to do in just few weeks with AI
- ask an agent to order lunch or groceries on a regular basis
- drop a mock into a chat box and ask AI engineer to build the entire feature in your code base
- connect your jira and ask AI engineer to fix bugs
- edit images and videos and make professional ads
- replace CRM software with an AI agent.
Slowly but surely we are automating work
English
@rohanpaul_ai Hey Rohan what do you use to analyse the papers? I mean the yellow and green highlights?
English

LLMs use identical neural circuits to process similar grammar patterns across different languages.
Basically the paper says, One brain circuit fits all: LLMs handle grammar the same way in any language
Original Problem 🔍:
LLMs excel in multilingual tasks, but little is known about their internal structure for handling different languages. This study investigates whether LLMs use shared or distinct circuitry for similar linguistic processes across languages.
-----
Solution in this Paper 🧠:
• Employs mechanistic interpretability tools to analyze LLM circuitry
• Focuses on English and Chinese for comparison
• Examines two tasks: Indirect Object Identification (IOI) and past tense generation
• Uses multilingual models (BLOOM-560M, Qwen2-0.5B-instruct) and monolingual models (GPT2-small, CPM-distilled)
• Applies path patching and information flow routes techniques
-----
Key Insights from this Paper 💡:
• LLMs use shared circuitry for similar linguistic processes across languages
• Monolingual models independently develop similar circuits for common tasks
• Language-specific components are employed for unique linguistic features
• Multilingual models balance common structures and linguistic differences
-----
Results 📊:
• IOI task: BLOOM achieves 100% accuracy in English, 95% in Chinese
• Past tense task: Qwen2-0.5B-instruct reaches 96.8% accuracy in English
• Shared circuitry identified for IOI task across languages and models
• Language-specific components (e.g., past tense heads) activated only when needed

English
India is a nuclear superpower with 1.5 million military personnel.
Canada has no missile defense shield and 68,000 troops.
Lets not escalate further. Ya?
English

Here's another link to the GitHub since the above link get's cut off for some reason:
github.com/adam-maj/tiny-…
English
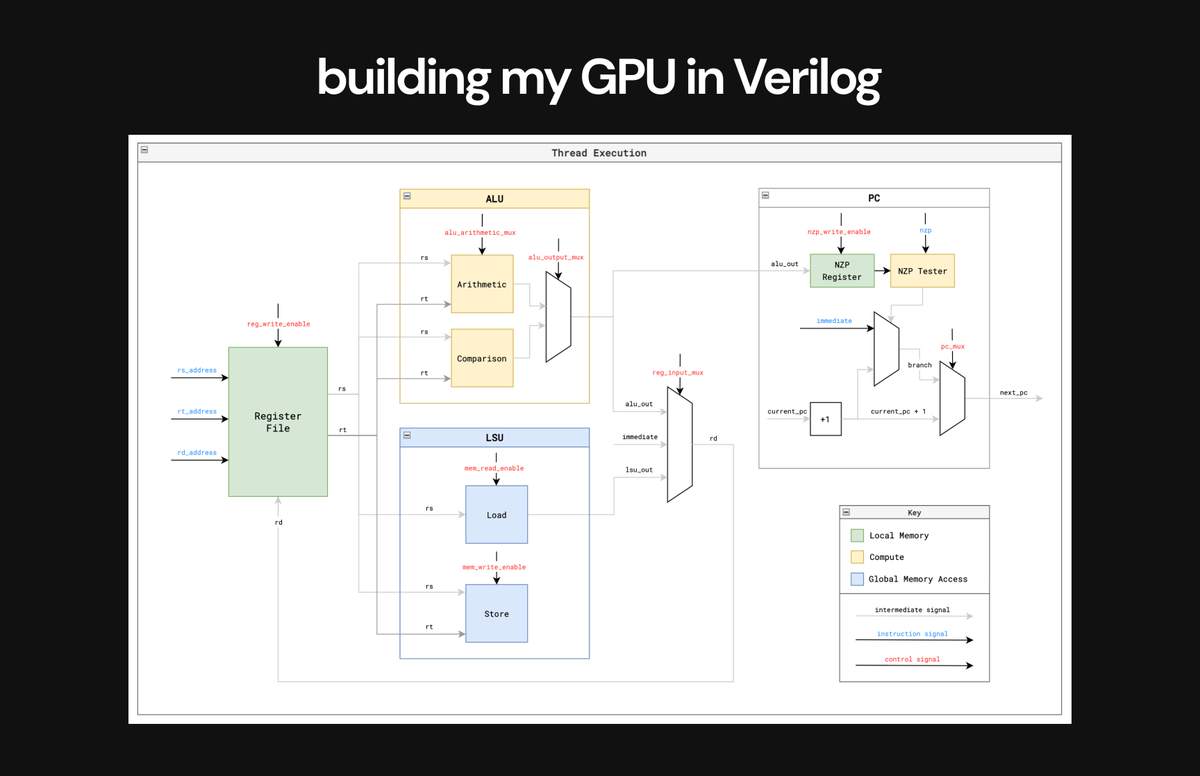
Step 5 ✅: Building my GPU in Verilog & running my kernels
After designing everything I needed to, I finally started building my GPU design in Verilog.
This was by far the hardest part. I ran into so many issues, and learned the hard way. I rewrote my code several times.
Rewrite 1:
I initially implemented global memory as SRAM (synchronous).
I ran into @realGeorgeHotz who gave me feedback that this defeats the entire purpose of building a GPU - the biggest design challenge of GPUs is managing the latencies of accessing async memory (DRAM) w/ limited bandwidth.
So, I ended up rebuilding my design using external async memory instead & eventually realized I also needed to add memory controllers.
Rewrite 2:
I implemented my GPU with a warp-scheduler (big mistake, far too complex and unnecessary for the goals of my project) initially.
Again feedback from @realGeorgeHotz helped me realize that this was an unnecessary complexity.
The irony is that when I first got the feedback, I didn't have enough context to fully understand it. So I spent time trying to build out a warp scheduler, and only then realized why it was a bad idea lmao.
Rewrite 3:
Didn't implement scheduling within each compute core correctly the first time around, had to go back and design my compute core execution in stages to get the control flow right.
But, despite the difficulty, this is the step where so much of my learning really sunk into deep intuitions.
By running into issues head on, I got a much more visceral feeling for the challenges that GPUs are built to work around.
> When I ran into memory issues, I really felt why managing access from bottlenecked memory is one of the biggest constraints of GPUs.
> I discovered the need for memory controllers from first principles when I when my design wouldn't work because multiple LSUs tried to access memory at once and realized I would need a request queue system.
> As I implemented simple approaches in my dispatcher/scheduler, I saw how more advanced scheduling & resource management strategies like pipelining could optimize performance.
Below is the execution flow of a single thread I built into my GPU in Verilog - it closely resembles a CPU in it's execution.
English
