تغريدة مثبتة

茨威格是个精神活在旧时代的宅男。他也死在了新时代的黎明里。他的观点落后中国古人一个身位的精神境界:中国人讲究读万卷书,行万里路。没有实践的阅读,是脑力工作者的精神自杀。
停雲@tingyun97
#世界读书日 读书人共勉。
中文
Poincaré
2.6K posts
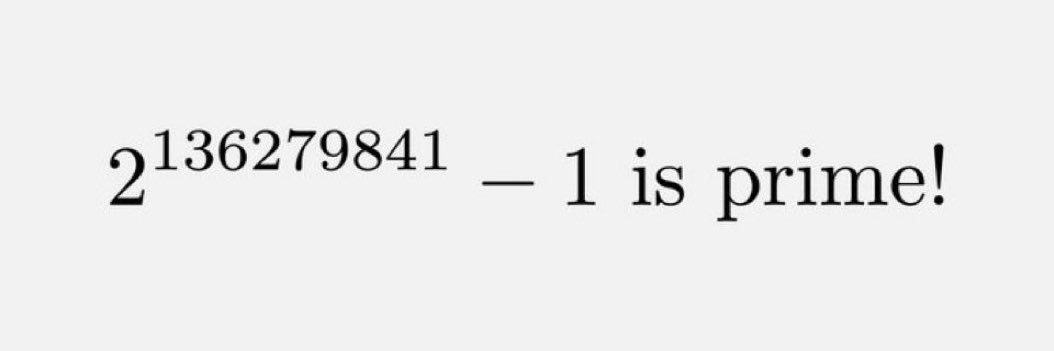
#世界读书日 读书人共勉。









Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip




@royxy 特朗普发动战争可能是错的,但是特朗普放任霍尔木兹海峡被封锁割肉止损是对的。












