
Takayuki Fukuda
32.1K posts
Takayuki Fukuda
@hedachi
Game Developer / Software Engineer / 株式会社ミリオンダウト代表取締役 / Ex-Electronic Arts / 生成AIでいろいろ作ってます。ハイライトからご覧ください
Tokyo انضم Ocak 2008
1.8K يتبع3.1K المتابعون
AI業界をLLM中心に3年ウォッチしてきた印象
自然言語をインターフェースにするというLLMの性質により、乗り換えコストが低い。
そのため、ChatGPTとか、Claude Codeとか、CursorみたいにAIのよい使い道を見つけたところが一気に稼ぐが、1年ぐらいで他も追いついてくるので、また次の稼ぎどころを見つけないといけなくなる構造になっている。
だいたいは、1番手が多くの稼ぎをもっていき、2番手が少し稼げるぐらい。
Googleは技術的にはすごいが、他の真似ではなく良い使い道を自分で見つける能力がないので、永遠の3番手以下という状態になっていて、ずっと美味しいところを取れない。
と見せかけて、効率性が異常に高くてインフラとユーザーベースが巨大なので、3番手以下で参入した出がらしの市場で、流行りが過ぎたあとにコスパの良い選択肢として地味に稼げる構造になっているように見える。
というパターンからすると、コーディングエージェントも5時間後から開催されるGoogle I/Oでいい感じのを出してきて、ここから割とシェアを取っていくかもしれないな。
日本語
文章の難しいところをクリックすると簡単にしてくれるChrome拡張
deepseek-v4-flashを試してみたけど、これでもだいぶちゃんと動く
一回0.04円とかで爆安
日本語
ClaudeにHTMLを出力させるのはめっちゃ良くて、自分は数ヶ月前から常用している。
でも、実際に常用してみると、毎回テキストの内容にあったフォーマットや表現技法を用いて綺麗に整理されているのに、意外と頭に入ってきにくかったりする。
一方、ChatGPTとかClaude Codeみたいなテキストベースのものは、テキストばっかりだしてくるから読むのがだるいこともあるけど、下の方にでてくるテキストを読んでればいいというのはわかりやすい面もある。
HTMLで出力させると、最初に情報のレイアウトを把握する必要があり、それがだるい時もある。
人間の認識における位置というものの重要性が見落とされがちな気がする。
Cursorが流行ったのもVScodeのUIの位置を概ね踏襲してたからだと思う。
テキストベースのAIはテキスト打ってりゃ操作できるから、ボタンの位置とかを把握しなくて済む所が流行ってる理由だと思う。
Andrej Karpathy@karpathy
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status… There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
日本語
文章の難しいところをクリックすると簡単にしてくれるやつ、Chrome拡張にしてみた
Takayuki Fukuda@hedachi
文章の難しいところをクリックすると簡単にしてくれるアプリを作ってみた
日本語
日本人も、物価が日本の半分のイタリア・フランス・ドイツみたいな国があったら行きたいと思うけど
今の日本は欧米から見るとそういう国なんだろうな
エキゾチック、安全、清潔、先進国、多様な歴史・文化・自然
適当に飲食店入ってもだいたいうまいし、まずくても100円200円だったら許せるもんな
Steph Smith@stephsmithio
The American mind cannot comprehend this 12-piece sashimi and 10-piece sushi in Japan costing $3 and $2 respectively. And it genuinely tastes better than most restaurants back home.
日本語
ChatGPT Images 2.0(Thinking)に画像を翻訳させてみた。完璧な翻訳に見える

Marc Andreessen 🇺🇸@pmarca
This is almost as true in the US.
日本語

パンチとかキックとか買えるのSaGaっぽい

CyberRobo@CyberRobooo
Unitree has just launched UNISTORE the humanoid robot version of the App Store The platform lets users create, develop, publish, purchase, and deploy robot actions, skills, and apps with one click, supporting all Unitree models. It’s still early stage: only the motion library is live (basic moves, dances, martial arts, etc.), all officially published and available as limited-time free downloads. The dataset module (which many are eager to see) is currently restricted to approved developers only. It’s unclear yet whether datasets will be tradable in the future.(what do you think?) Unitree is clearly building a full ecosystem platform. Currently available only in China, with the international version expected soon. unistore.unitree.com
日本語
CodexとClaudeに調査させてスプレッドシートを作らせた
Codexは正しく調査できたけど表がめちゃくちゃ見にくい
Claudeは調査が間違っていたけど表はとても見やすい

日本語


カタカナ表記の「コミュニケーション」って使用頻度高い言葉だから2トークンぐらいかなと思ってたけど、5トークンも食うとは

日本語


トークン数を調べるのはこのOpenAI公式のTokenizerで簡単にできます
platform.openai.com/tokenizer
日本語
Codex CLIでeffort変えるのめんどいってClaudeとCodexのチャンネルで聞いてみたら、Claudeがショートカットを見つけてくれた
Codexはなぜか発見してくれなかった笑

Takayuki Fukuda@hedachi
SlackでClaudeとCodexと話すチャンネルを別に作ってたんだけど、混ぜたらいい感じになった 基本的に両方とも個別に調べて回答してくれるけど、もう一方の会話も見ていて、2人で相談してって言えばしてくれる
日本語
他の日本語トークン数が多い言葉
アイデンティティ 5
identity 1
プレゼンテーション 5
presentation 1
サブスクリプション 6
subscription 1
プロフェッショナル 5
professional 1
インテグレーション 5
integration 1
デジタルトランスフォーメーション 10
digital transformation 2
日本語

Qwen3.6だと、コミュニケーションも話すも1トークン。
Gemma 4は話すが2トークン
gpt-ossはコミュニケーション5トークン、話すも2トークン
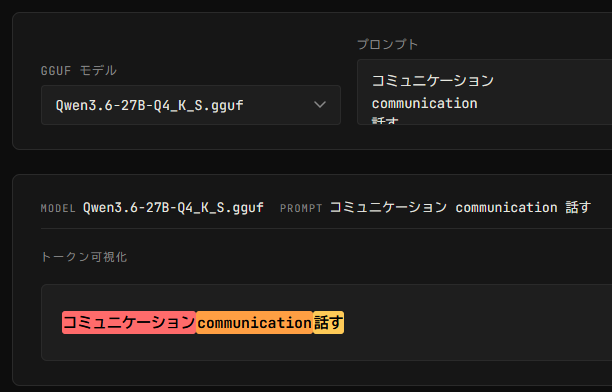
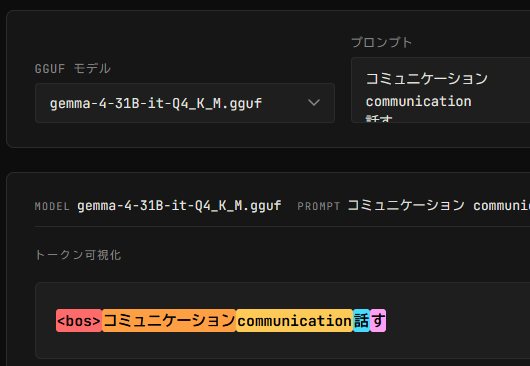
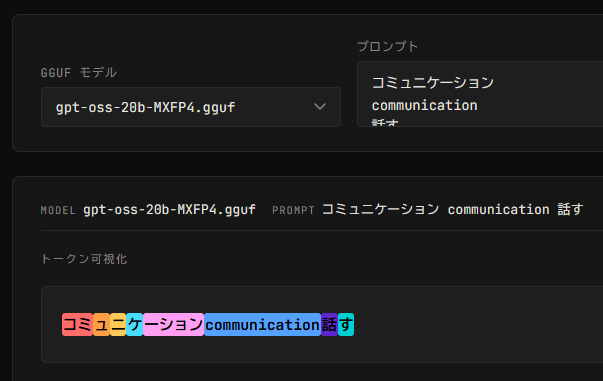
Takayuki Fukuda@hedachi
カタカナ表記の「コミュニケーション」って使用頻度高い言葉だから2トークンぐらいかなと思ってたけど、5トークンも食うとは
日本語