Ivan Zhang
347 posts


Ivan Zhang
@izzycodev
Developer, Failed Youtuber, and trying to fail at trading and AI




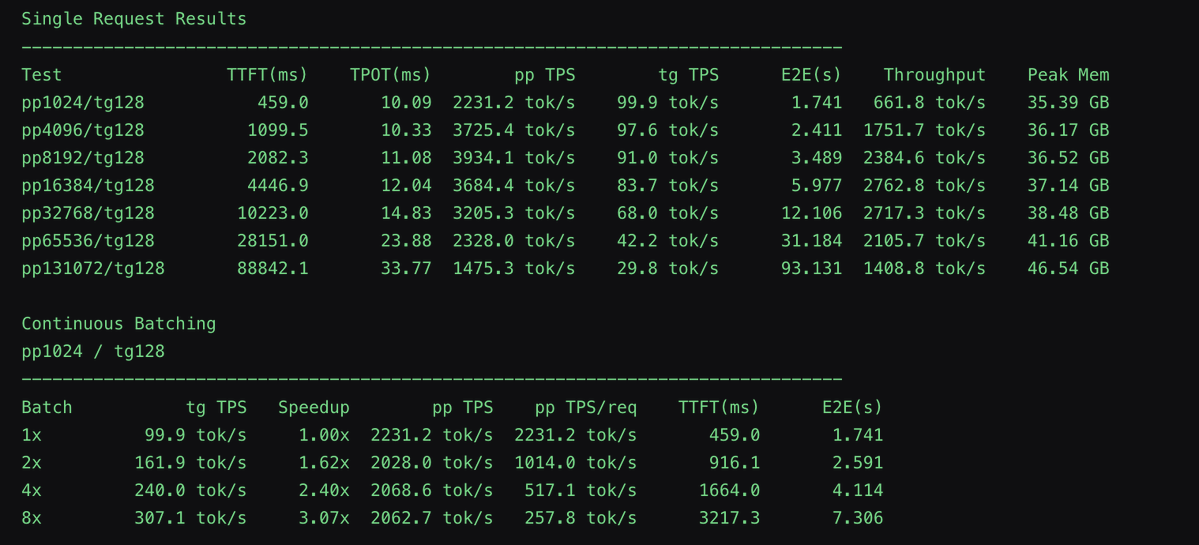
Trying to get @__tinygrad__ running with my m4 mini and a 5070 Seeing if it’ll run with a decent enough modem for Hermes Agent from @NousResearch Don’t know if 12gb is going to cut it






🔥 DFlash x MLX is happening! Shoutout to @aryagm01 for the early work on this. We're building on the momentum. Native MLX support, more models (Qwen3.5), up to 4x faster. Lossless! 👉 github.com/z-lab/dflash

Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…