Sabitlenmiş Tweet

witcheer
14K posts

@witcheer
community @NousResearch · sovereign compute advocate · ex @KPMG
Today's Hermes Agent Masterclass is the finale! Module 10 covers security, an important topic for running agents to ensure each agent can perform its tasks while minimizing exposure. Hermes has a ton of built-in security features. In this clip, I show how you can set approvals for each profile depending on your needs.


We're working on making the local model experience better in Hermes, what are the best local models at each weight class? My blind guess, please correct: 8-16 GB VRAM Gemma4 12B 24-32 GB VRAM Qwen3.6 27B Qwen3.6 35B 128 GB VRAM (Spark, M3 Max) ??? Can you do DSv4-Flash?


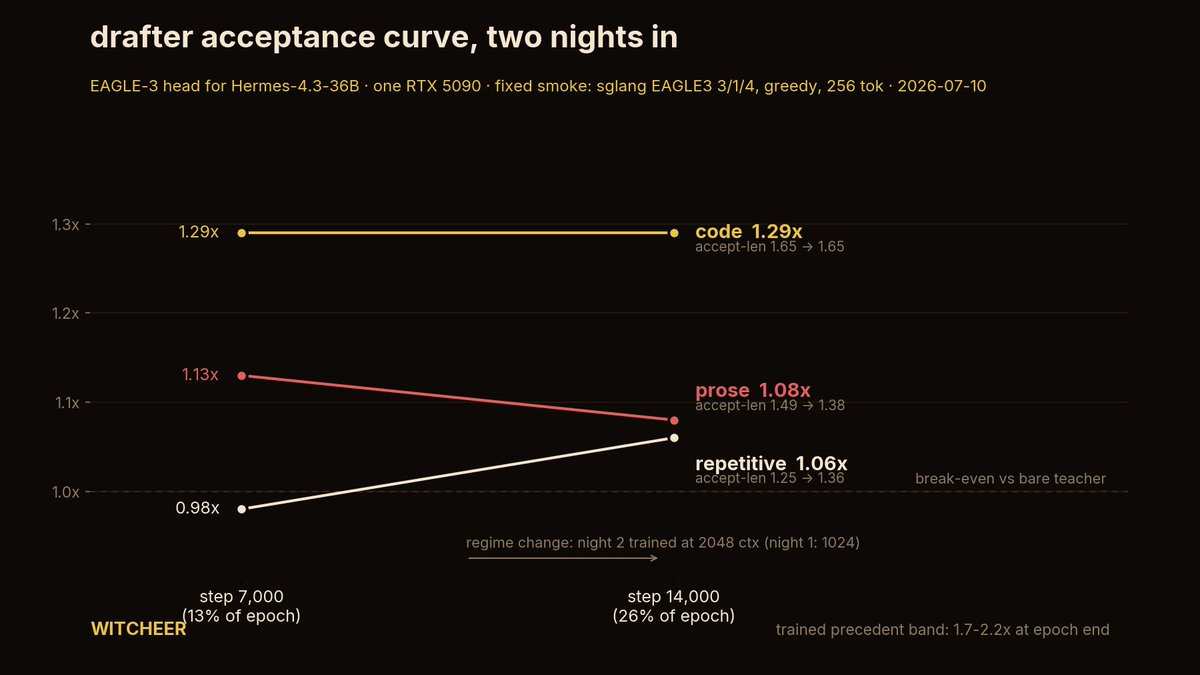
an EAGLE-3 draft head trains on the teacher's internal activations, not text. cache them to disk and a 36B teacher wants 4.5TB for the standard 54K-sample recipe. my disk is 570GB free only. so I chose online mode instead. the 4-bit teacher (19.5GiB, SGLang) stays resident and feeds the draft live, while fp32 optimizer state (8.4GiB) moves to system RAM with the step running on CPU. one more find: FSDP allocates gradient storage for frozen params, 1.5GiB for an embedding that never updates, so single-GPU skips the wrap entirely. ~~~ night 1 on one RTX 5090: 7,000 steps in 6h50m, expected acceptance 0.05 → 0.27 and still climbing. first drafter for Hermes-4.3-36B in training.





GPT-5.6 is now supported in Hermes Agent and available via Nous Portal




Grok 4.5 is now available in Hermes Agent - You can access it through your Nous Portal subscription, Grok/X Subscriptions and API, and OpenRouter! Enjoy