تغريدة مثبتة
Kadir Nar
1.2K posts


Kadir Nar
@kadirnardev
AI Research Engineer 🤖 Building Omni & TTS Models 👨🍳 at Vyvo
Remote انضم Ocak 2025
884 يتبع1.5K المتابعون






@ChristophSchuh6 Aratako had 30k hours of emotion data in their dataset. There are very few open-source emotion datasets for English. So making a voice design model can be very difficult. Maybe I can do this by producing synthetic data with echo and qwen3-tts, but it might not sound natural.
English


@ChristophSchuh6 Do you want the English version of the irodori-tts model?
English
@kadirnardev I think it would be interesting to train an Echo-like diffusion transformer that ingests SNAC artifact-corrupted audio and outputs high-quality 48 kHz DAC VAE without artifacts. Maybe a 400-million-parameter model or something like that could do it, just fixing artifacts. 🙂
English

@kadirnardev Vyvo veya orpheus farketmez aslında. Single GPU üzerinde paralelde latency çok yükselmeden ne kadar request karşılayabiliyor onu merak ediyorum. Flow matching tabanlı bir model üzerinde çalıştım scale etmek çok zor autoregressive de çalışmıyorlar ttft çok yükseliyor paralelde.
Türkçe
@kadirnardev Paralel istek durumunda latencyler ne durumda? Single H100 üzerinde kaç tane paralel requesti karşılayabilir?
Türkçe

The Qwen team is no longer releasing their models as open source, and this is a big problem for us. We need small models to train many models like TTS, STT, Omni, and others. Previously there was LLaMA, but they're no longer releasing either. The Qwen team won't be releasing anymore either. Our only hope is the LFM models.
Minimax, Kimi, and GLM teams are releasing great models for open source, but none of them release small models. And if these companies also stop releasing open source, it's going to be really bad :(
English
@foreignsplat Yes, I saw your new models and I'm very happy about it.
English

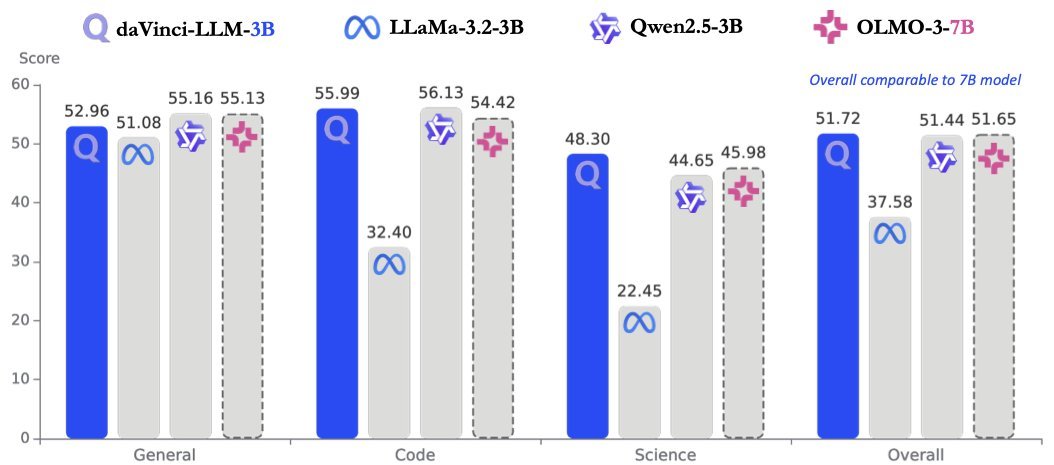
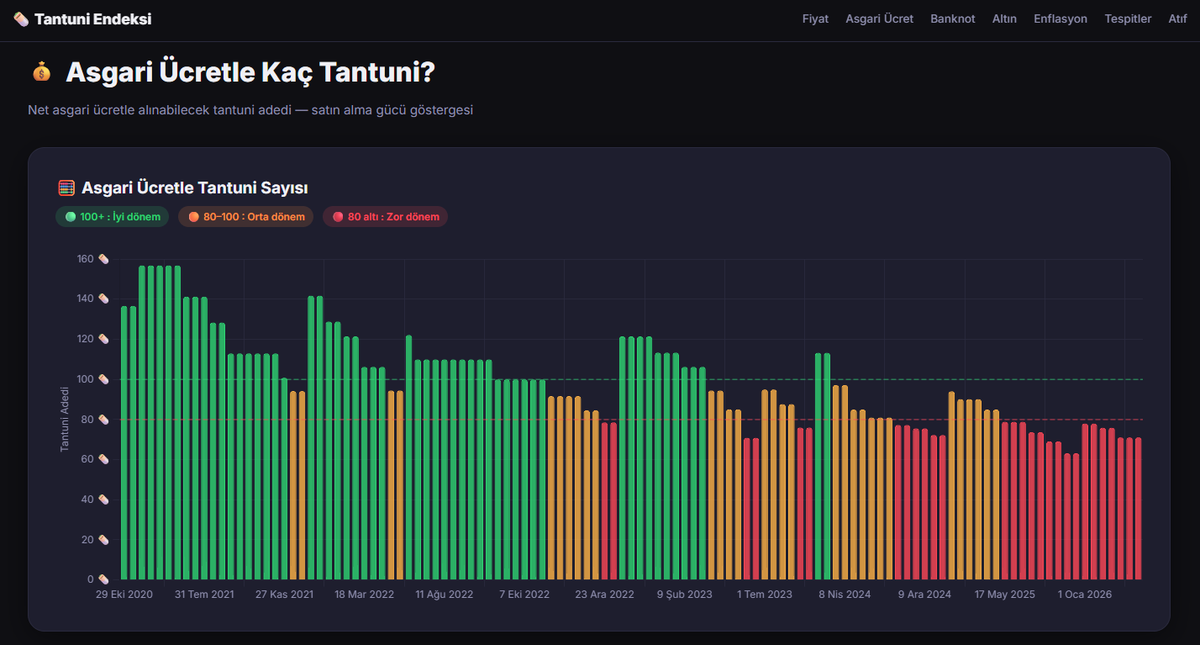
These models perform great since they're newly released, but in 3-4 months we'll need better models.
For example, if the LFM team doesn't release new small models, would it be okay for you to use old Gemma models? New models should be released constantly. When Gemma was first released, they were great models, but now they're not up to date.

English
@overlordayn They didn't release the TTS model. Why aren't we training multiple LFM-based models?
English

@kadirnardev They have an audio model that does tts and stt both (lfm2.5 audio)
English
Should I train TTS with the LFM2.5-350M model or the Omni model?
Liquid AI@liquidai
Today, we release LFM2.5-350M. Agentic loops at 350M parameters. A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle. <500MB when quantized, built for environments where compute, memory, and latency are constrained. 🧵
English
@billyG881 The Neucodec model quality isn't good. I'm thinking of using a better codec.
English

@kadirnardev Hopefully with NEUCODEC codec as its SOTA and has been trained on plenty of multi-lingual data 🤓🤓🤓
English

@kadirnardev Would this one work? datacollective.mozillafoundation.org/datasets/cmn4z…
English
@kadirnardev Are you considering training any TTS model with multilingual datasets or Spanish data? I’ve been using Queen 3 TTS, but the VRAM consumption I get even with quantized models is a bit high for a 12GB card like mine…
English
@WaelShaikh I had trained LFM models before, training them again could be good.
x.com/kadirnardev/st…
Kadir Nar@kadirnardev
We have released our LFM2-350M based TTS model as open source 🚀 We have also released many different FT models. GPU Platform: @hyperbolic_labs Data: Emilia + Emilia Yodas(EN) LLM Model: LFM2-350M @liquidai Disk and Space: @huggingface I'm very happy to have released this model as open source. Many thanks to @VyvoSmartChain #opensource #speech #tts #huggingface #lfm #gpu
English

@kadirnardev Definitely on the 350M model. Would love to see how it performs. LFM makes some of the fastest LLMs, I wonder if the speedup would even benefit the TTS.
English

Today, we release LFM2.5-350M. Agentic loops at 350M parameters.
A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle.
<500MB when quantized, built for environments where compute, memory, and latency are constrained.
🧵

English