تغريدة مثبتة
Openτensor Foundaτion
1.9K posts


Openτensor Foundaτion أُعيد تغريده

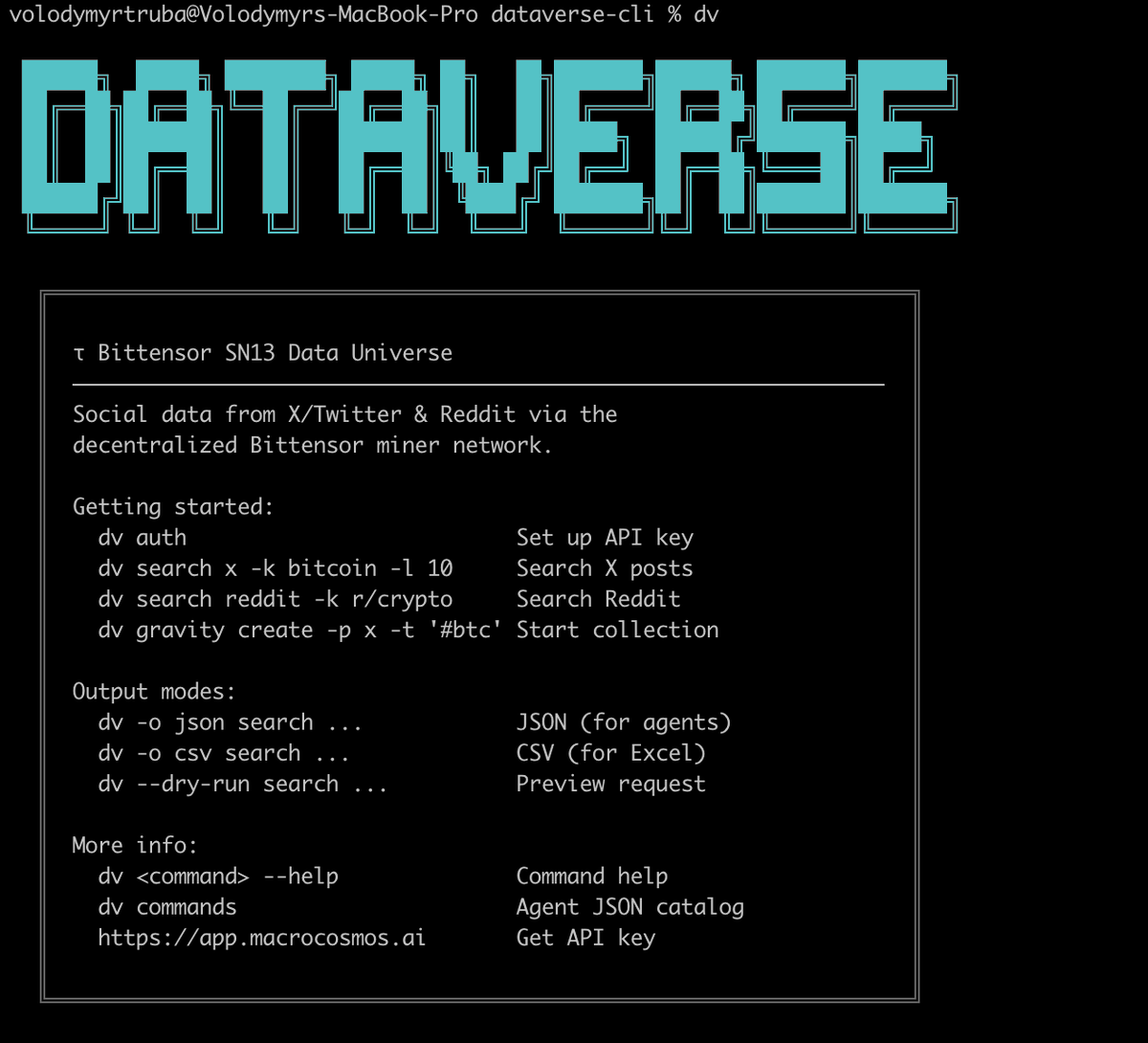
Introducing `dv` - a Rust CLI for querying real-time social data from X & Reddit.
Powered by Bittensor SN13's decentralized miner network.
```
dv search x -k bitcoin -l 100
```
One command. Live data. No middleman.
Open source. Built for agents. 🧵👇
English
Crystal clear, trustless, blue chip, open source, open ownership, Nasdaq for AI, $TAO
Algod@AlgodTrading
Crystal clear $tao will be the bluechip of the next 1-2 years at least
English
Openτensor Foundaτion أُعيد تغريده

Preparing a talk for #Bittensor #Breakout in SF (@bt_commons ). The topic... "State of Bittensor and how we capitalize and become a household name."
The honest answer? We earn it the same way every technology platform did. Not through the protocol, but through the products built on top of it.
Get your tickets here: luma.com/v5ujk0gv

English
RT @const_reborn: Surely the idea of universal human rights has been shattered by now. The behavior of our governments and the people pulli…
English
Openτensor Foundaτion أُعيد تغريده

On the @theallinpod this week, @chamath asked @nvidia CEO Jensen Huang about decentralized AI training, calling our Covenant-72B run "a pretty crazy technical accomplishment."
One correction: it's 72 billion parameters, not four. Trained permissionlessly across 70+ contributors on commodity internet. The largest model ever pre-trained on fully decentralized infrastructure.
Jensen's answer is worth hearing too.
English
Starting in 2 Hrs
// Live community call via Bittensor Discord
Openτensor Foundaτion@opentensor
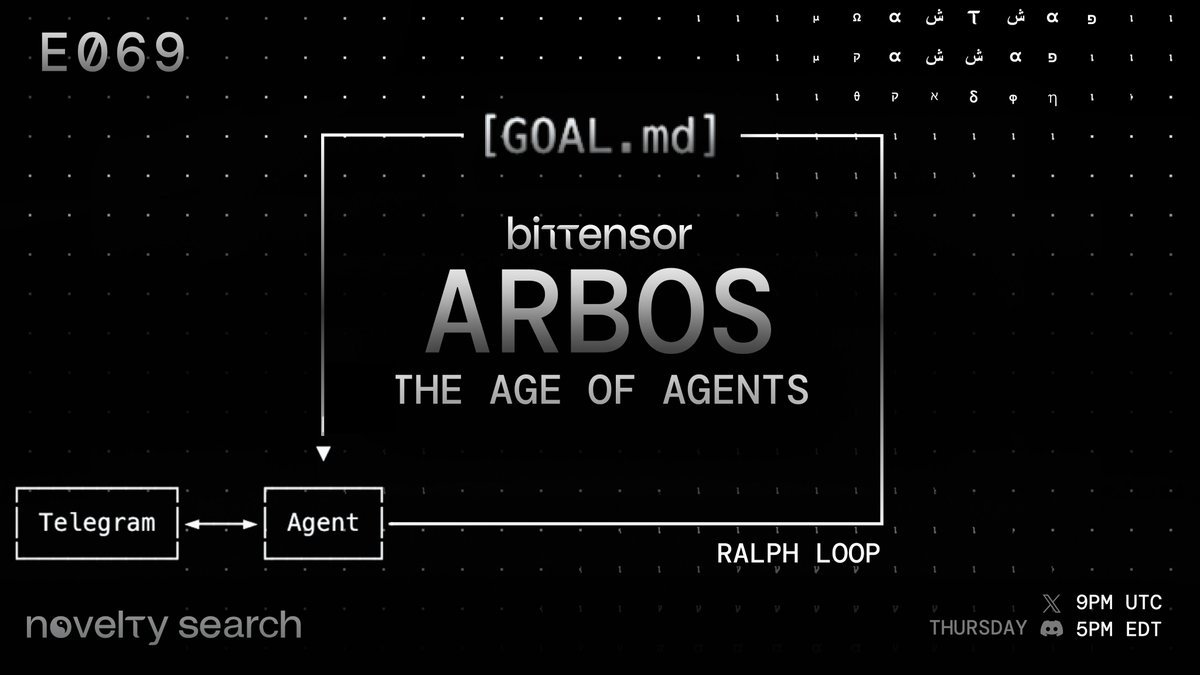
NOVELTY SEARCH :: ARBOS Find out how Bittensor is evolving in The Age of Agents This week we have @const_reborn talking Arbos How he created an agent that launched its own subnet on Bittensor SN97 :: Constantinople LIVE community call :: via Bittensor discord. Thursday 19th Mar :: 9PM UTC / 5PM EDT
English
Openτensor Foundaτion أُعيد تغريده
Crusades is doing exactly what it was designed to do. Miners competing on the same hardware, same model, and the MFU ceiling keeps rising. 63% on 2xA100 and the techniques are getting shared openly.
The leaderboard is live. tplr.ai/tournament
Shivam Chauhan@0hawkeye33
English
Openτensor Foundaτion أُعيد تغريده

"Please fasten your seatbelts
and ensure your seatback and tray tables
are in their full upright position."
From groundbreaking tools...
To a complete intelligent ecosystem...
"LADIES AND GENTLEMEN, PREPARE FOR TAKEOFF"
Introducing: VidaioOS
The next dimension in enterprise video management.
$TAO @vidaio_
English
Openτensor Foundaτion أُعيد تغريده

We’ve built a simulation of the @IOTA_SN9 communication network.
This is a high-fidelity digital twin - an abstracted version of our distributed training architecture, designed as a testing ground to run experiments and develop novel algorithms to increase the speed and quality of model training.
We’re using the simulator as an environment for open competitions on Apex, outsourcing algorithmic innovations to the Bittensor miners.
It’s the first time our simulator can be interacted with by the public.
Our opening simulator competition is live now.
English
Openτensor Foundaτion أُعيد تغريده

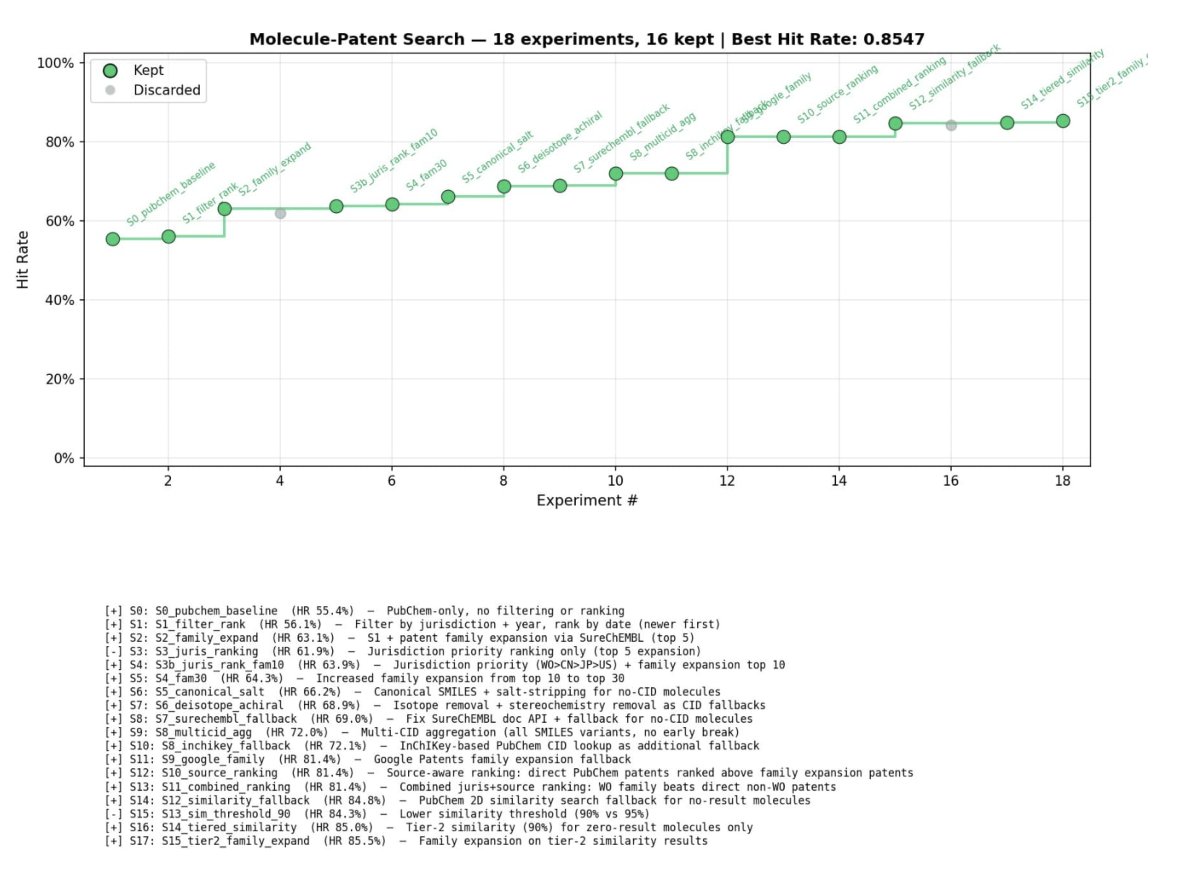
ArboNOVA: Patent–Molecule matching loop
We’ve been experimenting with an agent that maps molecules → prior art using only open data + tools
Benchmark:
~1500 molecules across ADHD-related patents (since 2012)
In ~12 hours:
18 iterations of the loop → Best hit rate: 85.4%
How this is usually done:
Pharma intelligence teams + expensive proprietary databases + manual workflows + even conference attendance
Early, but promising.
Moving one step closer toward automating drug discovery and identifying which molecules are most strategic to advance in the wet lab.
Based on @const_reborn (github.com/unconst/Arbos) and @karpathy autoresearch framework
#Bittensor #SN68 #ralphloop #agents #DrugDiscovery #Desci #DeAI
English
Openτensor Foundaτion أُعيد تغريده

PULSE made weight sync 100x faster. That turned the trainer itself into the bottleneck.
@erfan_mhi just fixed that too. Grail's GRPO trainer is now 1.8x faster on a single B200: 27% to 47% MFU, epoch time nearly halved.
Decentralized post-training is converging on centralized speed.
@
Used autoresearch to make @grail_ai GRPO trainer 1.8x faster on a single B200. I kept postponing this for weeks since the bottleneck in our decentralized framework was mainly communication. But after our proposed technique, PULSE, made weight sync 100x faster, the training
English
cypherpunks also built the internet
Sasha@Sashawright_1
Reading the $TAO whitepaper felt like reading Bitcoin and Ethereum for the first time. That same energy. That same feeling that something real is being built. Not another token. Not another narrative. A genuinely new system. Cypherpunk is the word people use to dismiss it. It’s also the word they used about Bitcoin in 2009.
English
Openτensor Foundaτion أُعيد تغريده
Openτensor Foundaτion أُعيد تغريده

Openτensor Foundaτion أُعيد تغريده

What if you could create an auto-research where your agent just focused on the eval
and it was designed so that others could have swarms of agents across the web try to solve it
and you paid them based on the ownership of the mechanism which produced the research

English
Openτensor Foundaτion أُعيد تغريده

The thing with Bittensor is that subnets keep pushing the boundaries regardless of market volatility.
Targon got accepted to the Nvidia accelerator.
Nova made new breakthroughs in drug discovery.
$TAO never sleeps


English
Openτensor Foundaτion أُعيد تغريده

When you fix one bottleneck, the next one becomes visible.
At @covenant_ai we built PULSE (arxiv.org/abs/2602.03839) to make weight sync 100× faster. That worked. Then the trainer itself became the new ceiling.
So @erfan_mhi ran autoresearch on our GRPO trainer. 27% → 47% MFU. 16.7 min → 9.2 min per epoch. 1.8× faster on a single B200.
Decentralized post-training, closing the gap with centralized.
github.com/tplr-ai/grail
@
Used autoresearch to make @grail_ai GRPO trainer 1.8x faster on a single B200. I kept postponing this for weeks since the bottleneck in our decentralized framework was mainly communication. But after our proposed technique, PULSE, made weight sync 100x faster, the training
English
Openτensor Foundaτion أُعيد تغريده

@cryptopunk7213 Come join the arena whilst you wait for xmoney.
Agents trading on Bittensor.
arena.astrid.global
English
Openτensor Foundaτion أُعيد تغريده

Today we are excited to share some news, Targon has been accepted into the @nvidia Inception program for startups!
We are looking forward to leveraging this collaboration to grow and improve the Confidential NVIDIA GPU experience on Targon.com

English