Desh Raj@rdesh26
Voice AI has grown a lot recently, and definitions of models/systems have become somewhat vague. Let's put down some basics.
1. AI "models" are not AI "systems".
Models are the core units that build up a system. For text-only systems, the two are trivially equivalent (discounting the BPE tokenizer/detokenizer), but not for voice. For voice AI systems, examples of model may be ASR, TTS, LLM, SpeechLLM, OmniLLM, etc.
2. A model is the smallest replaceable unit within a system.
For example, an STT model (user speech in / agent text out) often contains a speech encoder + an LLM, but neither of these components can be replaced without having to train the model again.
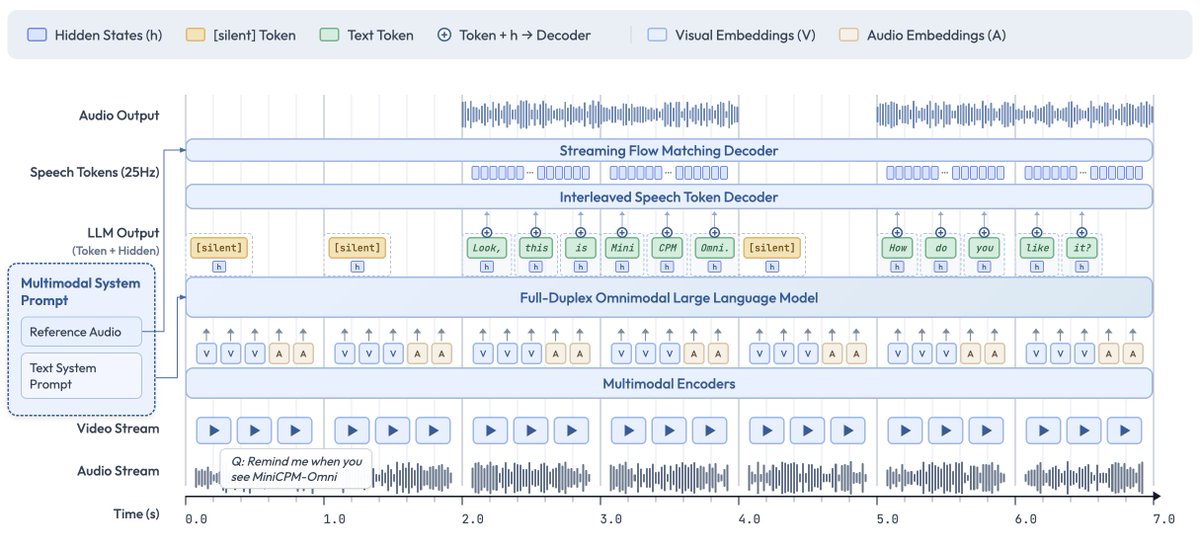
3. A speech-to-speech "system" (often called a voice agent) may take many forms and comprise many components, but it is always based on two requirements:
(A) response generation --> what/how to respond
(B) duplex control --> when to talk.
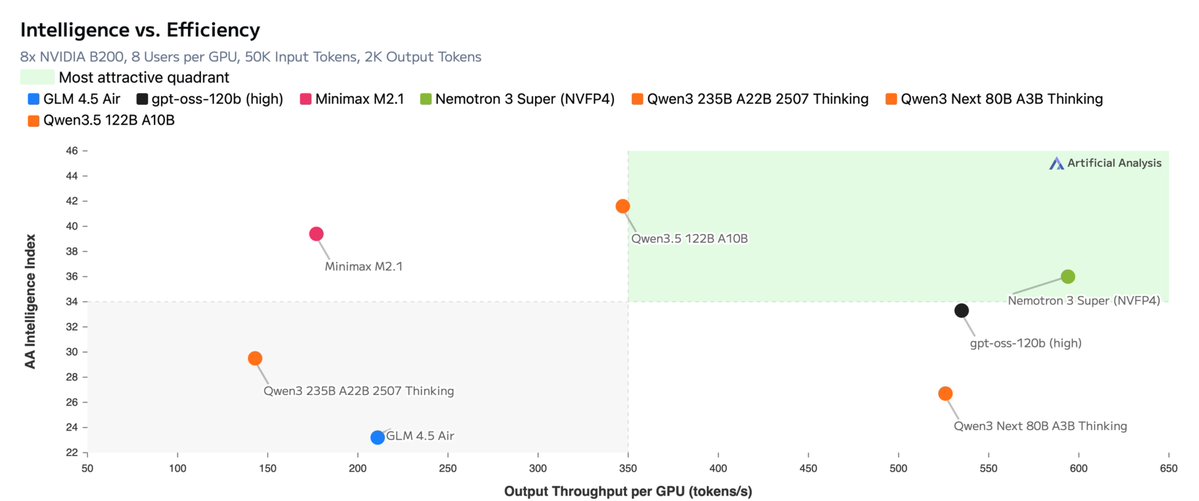
Traditionally, (A) has been handled through an ASR/LLM/TTS cascade. Most of the current S2S modeling research aims to replace this pipeline with fewer models (either STT+TTS or S2S).
Most systems still rely on external VADs and WebRTC for (B), with the famous exception of "full-duplex" models like Moshi.
4a. A SpeechLLM is a model that takes text+speech input, but only generates text output. It is also called a "speech understanding" model.
4b. An OmniLLM is a SpeechLLM that also generates speech (either codecs or continuous latents). It is also called a "speech generation" model (not to be confused with a TTS).
5. A speech-to-speech system is considered "realtime" if it satisfies 3 conditions: low latency (< 1s), streaming audio in/out, and barge-in/interruption handling. It can also be called a full-duplex system (not to be confused with a full-duplex "model").