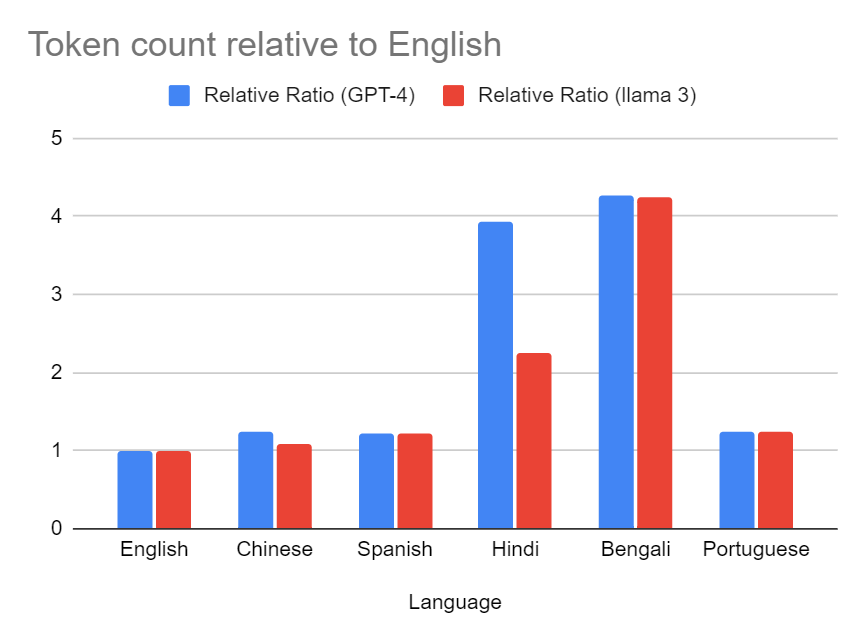
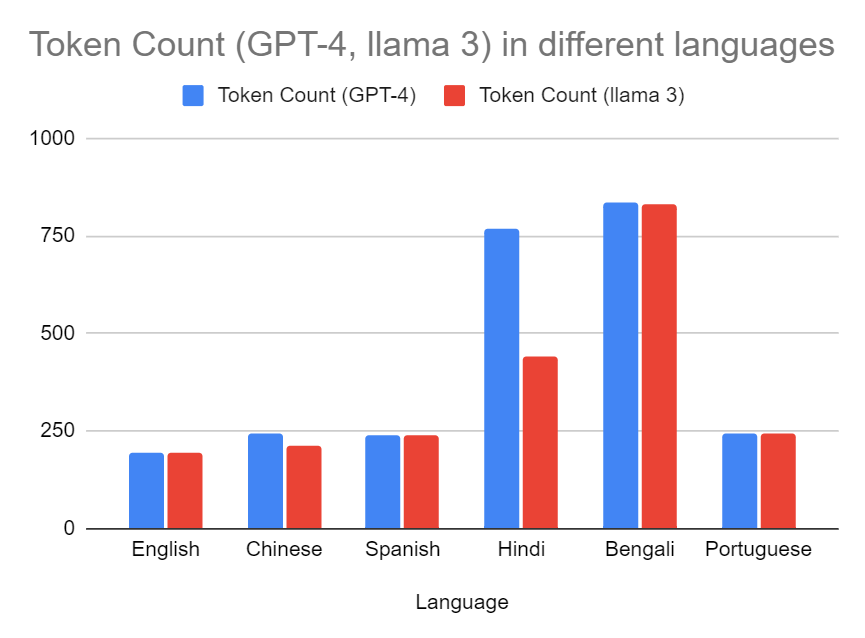
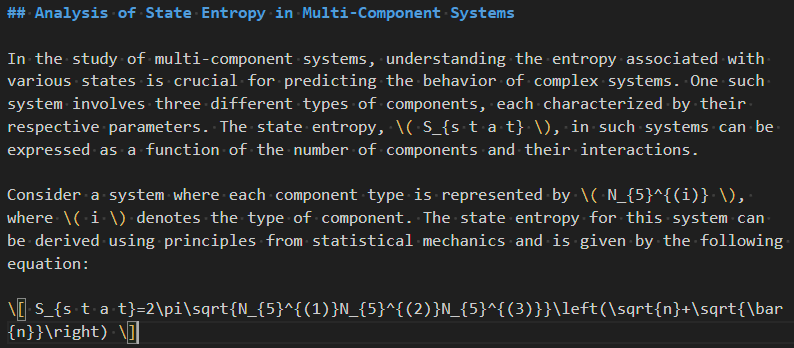
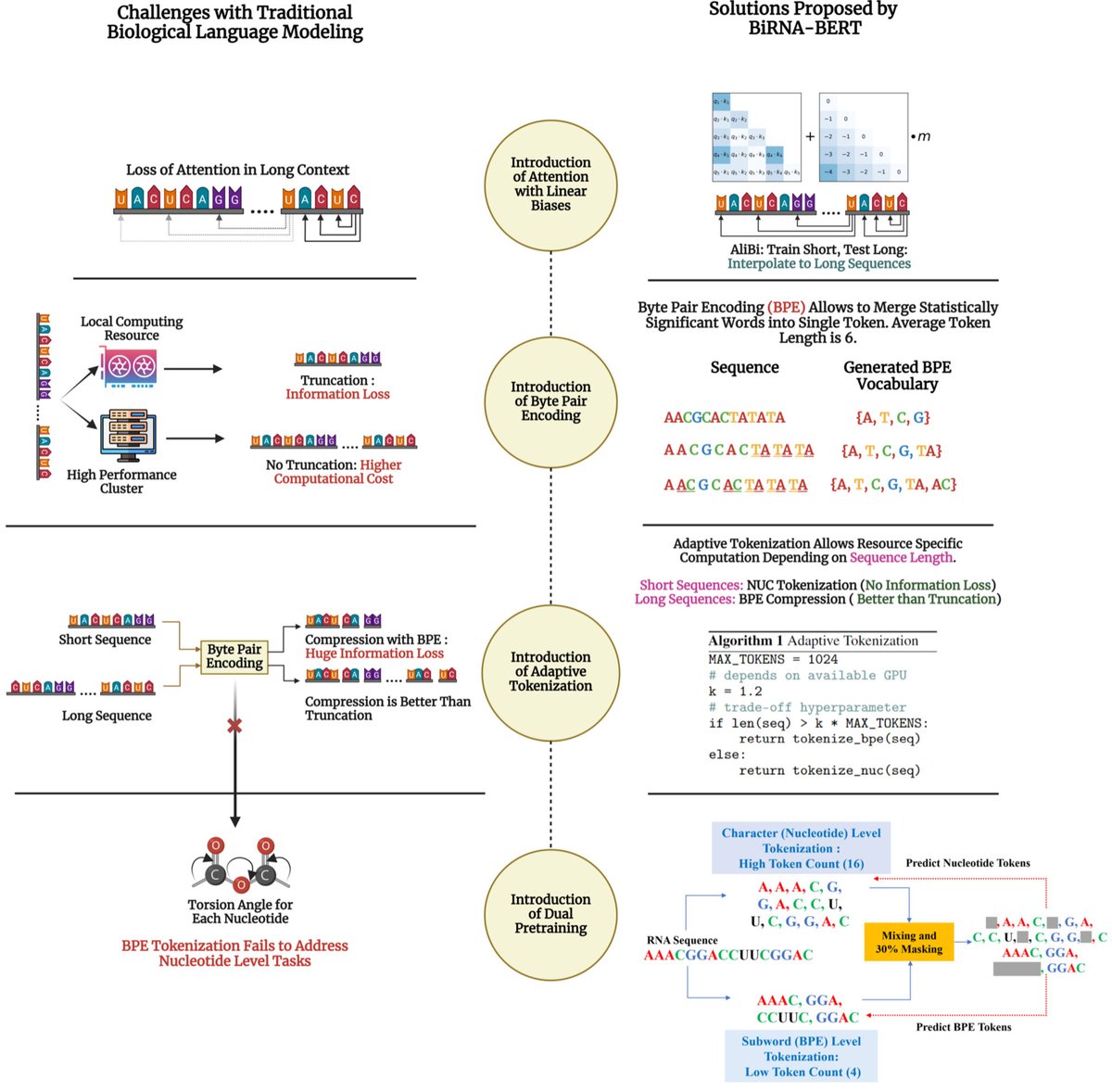
تغريدة مثبتة

Our IllusionVQA paper has been accepted at @COLM_conf ! 🥳
Haz Sameen Shahgir@sameen2080
Can multimodal models like GPT4V comprehend optical illusions? Can they tell apart illusions from ordinary objects? 🚀 Introducing IllusionVQA 👁️🧠 📄 Paper: arxiv.org/abs/2403.15952 🌐 Website: illusionvqa.github.io
English