
unbug
2.4K posts
unbug
@unbug
https://t.co/5sKsiEXX8Y, CODELF (Github star 14k, https://t.co/z1Mfw3yNcy), #MIHTool (Mentioned in Google I/O'13, https://t.co/HS3Jxj8Zho)
Los Angeles, CA انضم Ocak 2008
670 يتبع1.2K المتابعون

I've been using nemotron here and there with hermes and not having this problem. It's probably not the model but hermes itself.
little tests that may help:
1. try with a fresh conversation (shorter context) and see if the gibberish goes away. If it does, their KV cache is corrupting under memory pressure.
2. if OpenRouter is running this at aggressive quant (Q4 on a 120B model) the KV cache might be quantized too aggressively. try a different provider or model variant.
3. if you're self hosting (not sure based on the screenshot) check if KV cache quantization is enabled. the mixed-script output is a dead giveaway of corrupted attention values
English

ran a NIAH-style check on the mlx-vlm triattention PR using the same model (gemma-4-26b-a4b 4-bit).
inserted “PURPLE ELEPHANT 7742” at start / middle / end of a ~6.6k token context and asked the model to retrieve it.
baseline: middle PASS, end PASS
TA-512: middle FAIL, end PARTIAL (drops “ELEPHANT”)
TA-1024: middle FAIL → outputs “PURPLE RAIN 774”
TA-2048: matches baseline
the interesting part is the 1024 case. the model doesn’t just miss the needle, it hallucinates a semantically similar phrase. that’s consistent with the token being evicted but still partially activated.
at 2048 it looks fine, but that’s also a low-pressure regime relative to context length.
this is the gap i was pointing at earlier. MATH500 is mostly self-contained, so it doesn’t stress whether the eviction policy is keeping the right tokens under pressure.
NIAH directly tests that. if important info gets dropped, you either see a miss or this kind of near-semantic hallucination.
implementation looks solid. i think adding a targeted long-context retrieval test would give a more complete picture.
English

TriAttention MLX benchmark run on the full MATH500 is done after ~30h.
We ran Gemma4-26B (5-bit) on M3 Ultra with KV cache budgets of 512, 1024, and 2048:
→ TA-2048: 76.6% vs 77.4% baseline — 4 problems lost out of 500 (-0.8%)
→ TA-1024: 75.6% — 9 problems lost (-1.8%)
→ TA-512: 72.0% — 27 problems lost (-5.4%)
→ Speed: ~76 tok/s across all modes — zero overhead
For reference, the original paper reports TriAttention on Qwen3-8B:
→ 512: 55.5%, 1k: 68.5%, 2k: 69.0%, 3k: 69.8% (baseline ~70%)
Our results on a different model family and scale track the same pattern.
The 30-sample pilot estimated -3.4% for TA-2048. Full eval: -0.8%. Scaling up the eval mattered.
Paper link: arxiv.org/pdf/2604.04921

Prince Canuma@Prince_Canuma
🧮 MATH 500 results for TriAttention on Gemma4-26B-A4B-it (5-bit quantized, M3 Ultra 512GB) using MLX-VLM TA-2048 preserves 96% of baseline accuracy (22/30 vs 23/30) with KV cache capped at 2048 tokens, regardless of reasoning length. Throughput stays rock-solid at ~77 tok/s across all modes. Our gap is larger than the paper's (-3.4% vs -1.2% at budget=2048) because: 1. We ran Gemma4 A4B in non-thinking mode 2. Only 5 full-attention layers (50 are sliding window), less surface area for TriAttention. 3. 5-bit quantization maybe adding noise on top of KV compression The takeaway: TriAttention works on Apple Silicon with MLX. Even on a non-reasoning mode with aggressive quantization, TA-2048 keeps accuracy intact. 🍎
English

If you look at GPT 5.4-Cyber and it's ability for closed source reverse engineering, I have bad news for you.
I do very much feel the pain though, there's hundreds of teams that try to poke holes into @openclaw. Our response has been of rapid iteration and code hardening. Which did introduce occasiaonal regression (and yes you all been yelling at me), but I see as the only way forward.
I would be very careful of other open source projects/harnesses that ignore this work and do not publish their advisories. github.com/openclaw/openc…
Bailey Pumfleet@pumfleet
Open source is dead. That’s not a statement we ever thought we’d make. @calcom was built on open source. It shaped our product, our community, and our growth. But the world has changed faster than our principles could keep up. AI has fundamentally altered the security landscape. What once required time, expertise, and intent can now be automated at scale. Code is no longer just read. It is scanned, mapped, and exploited. Near zero cost. In that world, transparency becomes exposure. Especially at scale. After a lot of deliberation, we’ve made the decision to close the core @calcom codebase. This is not a rejection of what open source gave us. It’s a response to what risks AI is making possible. We’re still supporting builders, releasing the core code under a new MIT-licensed open source project called cal. diy for hobbyists and tinkerers, but our priority now is simple: Protecting our customers and community at all costs. This may not be the most popular call. But we believe many companies will come to the same conclusion. My full explanation below ↓
English


@TheGeorgePu That’s why you tokens routers making money, they don’t pay for a dc
English

I've been GPU shipping for my company.
One H100 on Google Cloud: $8,000 a month.
Retail price: $30,000.
Just renting for 4 months you could own them for life.
With cloud GPUs, you don't own ANYTHING.
You're just paying someone else's GPU mortgage.
Can't host it at your house because of noise/cooling?
Try a colo place - I have one right next to my office.
Starting at $1k/mo. Makes sense fast.
Here's where I think this is going:
Personal use - a Mac Mini or two running local models. Forever.
Business - stacking Mac Studios first. Then own GPUs in a colo rack.
Everyone's arguing about which model is best.
Nobody's asking who owns the computer it runs on.
Testing both paths now. Will document everything.
English
@basecampbernie That’s shame, my 9yrs old v100 almost runs better , and it’s only $200
English

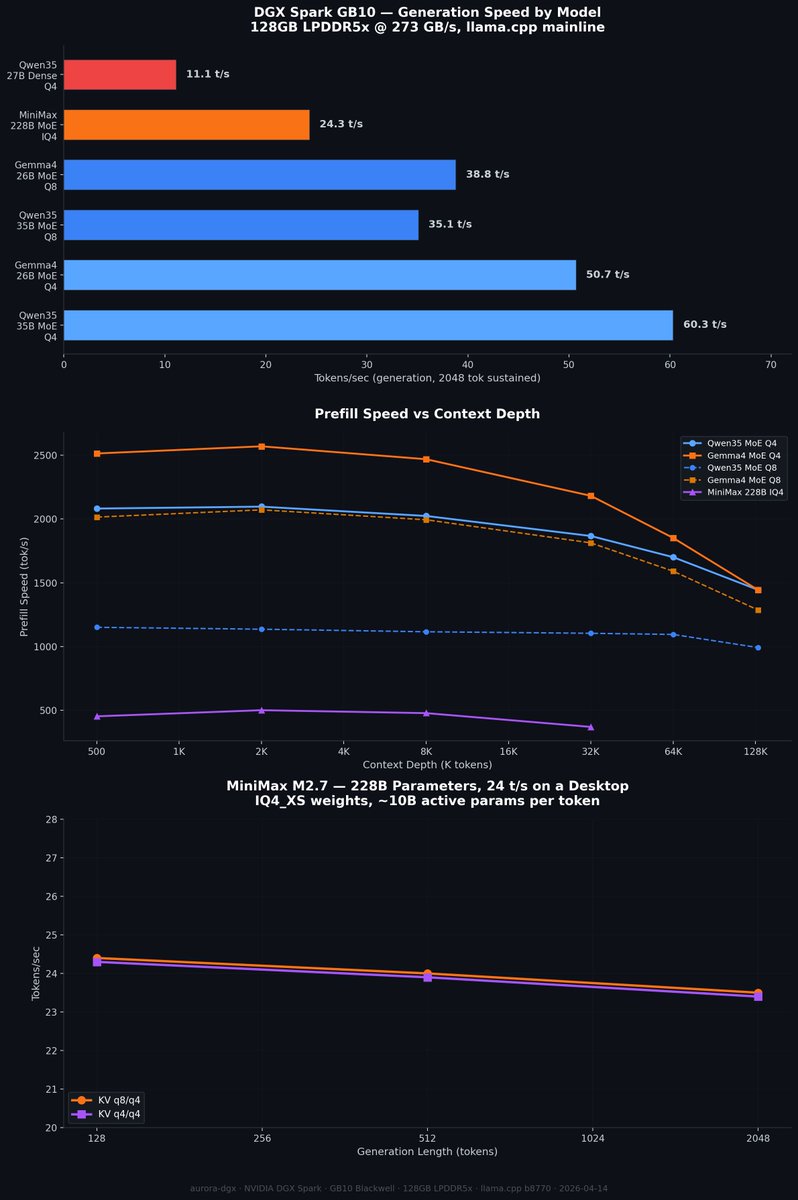
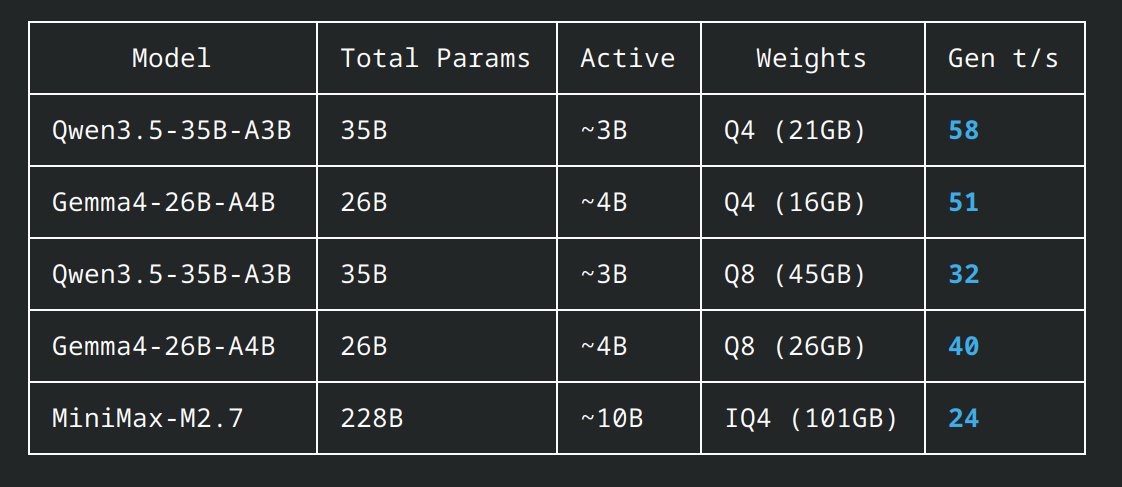
Small model MoE shootout on DGX Spark GB10. 262K context, 2048 tok generation:
Qwen3.5-35B-A3B MoE (Q4_K_XL q8/q8): 60 t/s
Gemma 4 26B-A4B MoE (Q4_K_XL q4/q4): 51 t/s
Qwen3.5-35B-A3B MoE (Q8_K_XL q8/q4): 35 t/s
Gemma 4 26B-A4B MoE (Q8_K_XL q4/q4): 39 t/s
MiniMax-M2.7 228B MoE (IQ4 101GB): 24 t/s
3-4B active params pushing 60 t/s at full 262K context. The MoE efficiency is wild.
Qwen 3B active outpaces Gemma 4B active on raw speed, but Gemma's
reasoning edge closes the gap on quality.
All llama.cpp on a single GB10. These small MoEs are the real hero models of 2026.


Indonesia
@TheAhmadOsman Man could you compare them to qwen3-code-next? I just don’t have the vram to test it but plan to double vram.
English
@ollama @GoogleDeepMind @sgl_project @radixark So when we gonna be able to get TurboQuant on Ollama?
English

Ollama and Google Gemma team is hosting an Ollama Gemma Day in Palo Alto tomorrow night (Wednesday, April 15th at 6pm).
Lots of amazing speakers from @GoogleDeepMind and @sgl_project / @radixark!
Looking forward to seeing many of you!
RSVP + Approval required:
luma.com/ollama-gemma4
English
@TheAhmadOsman nice map, I like you put all things on the table, everyone got what he want from it
English

MiniMax M2.7 Benchmarks on 4x DGX Spark + vLLM
- 45k / 110k / 178k requests, 1.63k prefill + 14.30 decode token/sec
- 25k / 49k / 74k requests, 2.52k prefill + 23.38 decode token/sec
- 4k / 8k / 16k requests, 3.45k prefill + 33.44 decode token/sec
What else do you wanna see?

Ahmad@TheAhmadOsman
MiniMax M2.7 at home running on 4x DGX Sparks vLLM serving full BF16 weights, 200k context OpenCode having the model monitor its own hardware and report thermals, tokens/sec, TTFT, and other runtime stats in real time What benchmarks / workflows / things do you wanna see next?
English

Introducing Kernels on the Hugging Face Hub ✨
What if shipping a GPU kernel was as easy as pushing a model?
- Pre-compiled for your exact GPU, PyTorch & OS
- Multiple kernel versions coexist in one process
- torch.compile compatible
- 1.7x–2.5x speedups over PyTorch baselines
English

Red Hat AI: Gemma 4 31B comprimido via LLM Compressor = 2x tokens/sec, metade da memoria, 99%+ accuracy retida rodando em vLLM.
e o argumento central do local AI — o teto nao ta no modelo maior, ta na quantizacao que preserva qualidade. mesmo modelo, 2x mais rapido, 50% VRAM. consumer GPU ganha um tier inteiro
Português
@nvidianewsroom come on Nvidia, I know you are rich, so why not open source a 80b MoE like coding model which is the best kind, I know can do it! I am sick of the price of xxxCode
English

Introducing NVIDIA Ising, the world’s first open AI models to accelerate the path to useful quantum computers.
Researchers and enterprises can now use AI-powered workflows for scalable, high-performance quantum systems with quantum processor calibration capabilities and quantum error-correction decoding.
Learn more: nvidianews.nvidia.com/news/nvidia-la…
English

Microsoft made 100B parameter models run on a single CPU.
bitnet.cpp: The official inference framework for 1-bit LLMs.
The math behind 1-bit LLMs is what makes them revolutionary.
Traditional LLMs use 16-bit floating point weights. Every parameter is a number like 0.0023847 or -1.4729.
When you run inference, you multiply these floats together. Billions of times. That's why you need GPUs, they're optimized for floating point matrix multiplication.
BitNet b1.58 uses ternary weights: {-1, 0, 1}.
That's not a simplification. That's a fundamental change in the math.
When your weights are only -1, 0, or 1:
→ Multiply by 1 = keep the value
→ Multiply by -1 = flip the sign
→ Multiply by 0 = skip entirely
Matrix multiplication becomes addition and subtraction.
No floating point operations. No GPU required.
This is why bitnet.cpp achieves:
→ 2.37x to 6.17x speedup on x86 CPUs
→ 1.37x to 5.07x speedup on ARM CPUs
→ 71.9% to 82.2% energy reduction on x86
→ 55.4% to 70.0% energy reduction on ARM
The speedups scale with model size. Larger models see bigger gains because there are more operations to simplify.
A 100B parameter model running at human reading speed (5-7 tokens/second) on a single CPU.
That's not optimization. That's a different paradigm.
Why 1.58 bits? Because log₂(3) ≈ 1.58. Three possible values = 1.58 bits of information per weight.
The key insight: These models aren't quantized after training. They're trained from scratch with ternary weights. The model learns to work within the constraint. No precision loss. No quality tradeoff.
English

Everyone said 16GB isn’t enough for a 35B model. They were right. Until this one flag.

leopardracer@leopardracer
English



What local model are you running the most right now?
English