Angehefteter Tweet
DHD
26 posts



Memory Loss Breakthrough
New study reverses memory loss by reactivating the gut–brain connection and achieving a full cognitive reset.
Stanford researchers discovered that age-related decline may start in the gut, not the brain, and can potentially be reversed.
This groundbreaking study revealed that aging gut bacteria can silence the vagus nerve, effectively "switching off" the brain's memory center. Researchers found that specific microbes, particularly Parabacteroides goldsteinii, produce metabolites that trigger intestinal inflammation.
This inflammation interferes with vagus-nerve signaling, reducing communication between the gut and brain and weakening activity in the hippocampus, the brain's memory center.
By restoring vagus-nerve activity and correcting the gut microbiome, scientists were able to make the brains of old mice function like those of 2-months old mice.
This "remote control" strategy suggests that memory loss may not be an inevitable brain disease, but a communication failure that can potentially be repaired through the digestive system.

English
DHD retweetet

Universality of Neural Network Field Theory
arxiv.org/pdf/2601.14453
Christian Ferko, James Halverson, Aaron Mutchler.
arxiv.org/abs/2601.14453
English

DHD retweetet

Solving PDEs on photonic quantum computers—without nested gradients
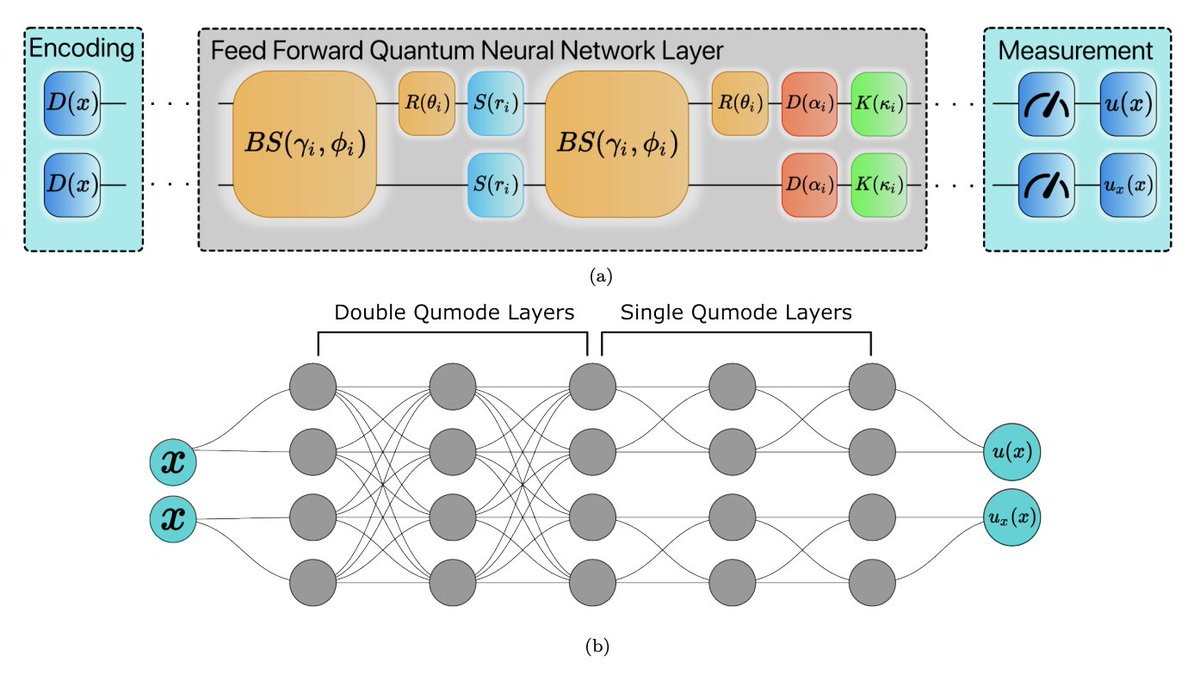
Physics-informed neural networks (PINNs) are powerful tools for solving differential equations, but they hit a wall when you need higher-order derivatives: nested gradient calculations explode in complexity and often compromise accuracy. For quantum implementations—where gradient computation is already challenging—this becomes a serious bottleneck.
Giorgio Panichi, Sebastiano Corli, and Enrico Prati take a different route. Working with continuous-variable quantum computing—where information lives in the quadratures of light rather than discrete qubits—they design a quantum neural network architecture that sidesteps nested differentiation entirely. The trick: use multiple output modes from the same circuit, training one to approximate the solution and another to approximate its derivative, enforced through a "consistency loss" that keeps them aligned. This lets you compute second-order derivatives (and higher) with just one level of automatic differentiation.
Using Strawberry Fields and TensorFlow, they demonstrate the approach on two classic problems: the 1D Poisson equation (RMSE ~ 10⁻⁴) and the heat equation as a proof-of-concept PDE (RMSE ~ 10⁻²)—matching or slightly outperforming classical PINNs with equivalent parameter counts. Crucially, they also characterize real photonic hardware—Xanadu's X8 processor—to model optical losses, and show that their variational algorithm naturally compensates for systematic noise through parameter adaptation.
The broader point: photonic quantum computers offer unique advantages for edge deployment—room-temperature operation, immunity to decoherence, portability to satellites or underwater vehicles. By extending QPINNs to handle PDEs without the nested gradient problem, this work opens a path toward quantum-assisted simulation of physical systems in environments where classical hardware struggles. Future directions? Integrating quantum sensing data to tackle many-body Schrödinger equations that remain classically intractable.
Paper: journals.aps.org/prapplied/abst…
English
DHD retweetet

Like @davidbessis and others, I think that Hinton is wrong. To explain why, let me tell you a brief story.
About a decade ago, in 2017, I developed an automated theorem-proving framework that was ultimately integrated into Mathematica (see: youtube.com/watch?v=mMaid2…) (1/15)
YouTube
vitrupo@vitrupo
Geoffrey Hinton says mathematics is a closed system, so AIs can play it like a game. They can pose problems to themselves, test proofs, and learn from what works, without relying on human examples. “I think AI will get much better at mathematics than people, maybe in the next 10 years or so.”
English
Emergence are observer, glhf for the measurement :)
arxiv.org/pdf/2102.04032
arxiv.org/pdf/2407.12895
arxiv.org/pdf/2509.14185
arxiv.org/pdf/2503.01800
arxiv.org/pdf/2209.10488
arxiv.org/pdf/1307.0827
shorturl.at/djZ7q
English

@godofprompt Happen a lot with multi loss in RL. Reward is basically a validation loss. Example with muzero stochastic
github.com/DHDev0/Stochas…
github.com/DHDev0/Stochas…
English

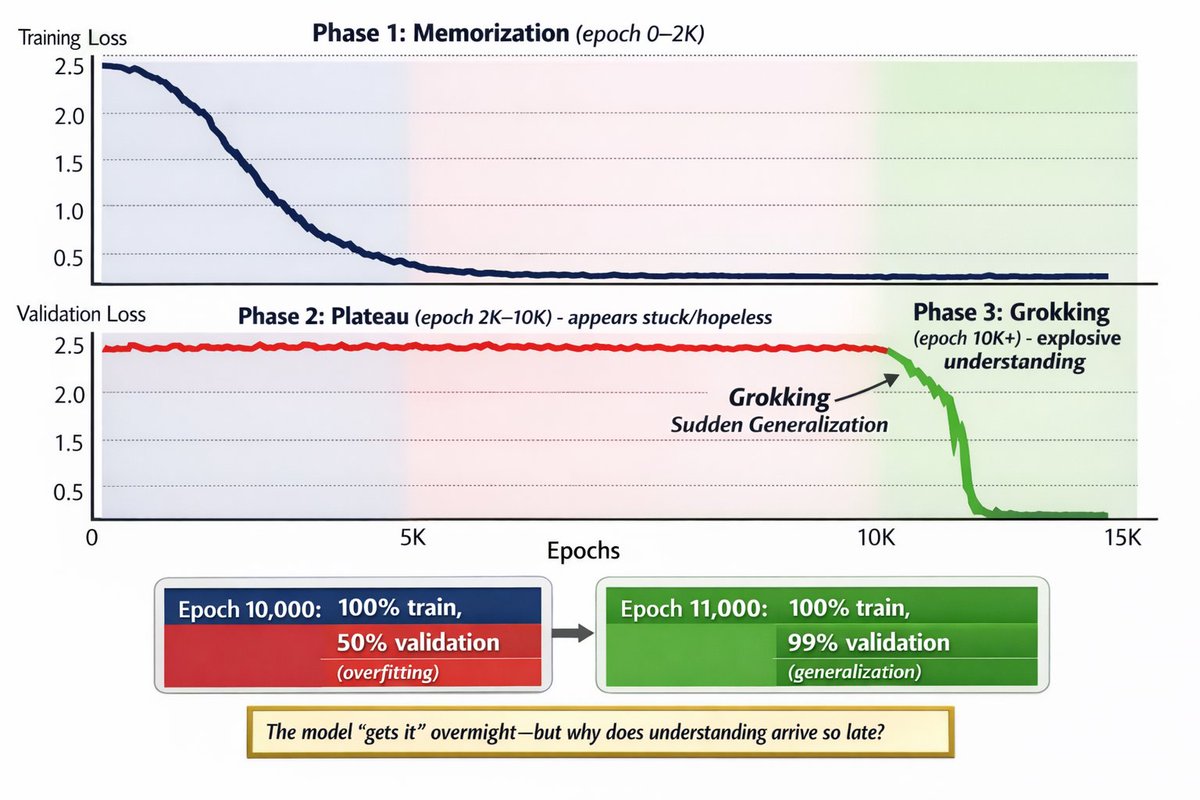
🚨 DeepMind discovered that neural networks can train for thousands of epochs without learning anything.
Then suddenly, in a single epoch, they generalize perfectly.
This phenomenon is called "Grokking".
It went from a weird training glitch to a core theory of how models actually learn.
Here’s what changed (and why this matters now):
English