

The observable universe is 93 billion light-years across.
If you compressed it to the size of Earth, our galaxy would be smaller than a grain of sand. Our solar system would be invisible inside that grain. Not small. Invisible.
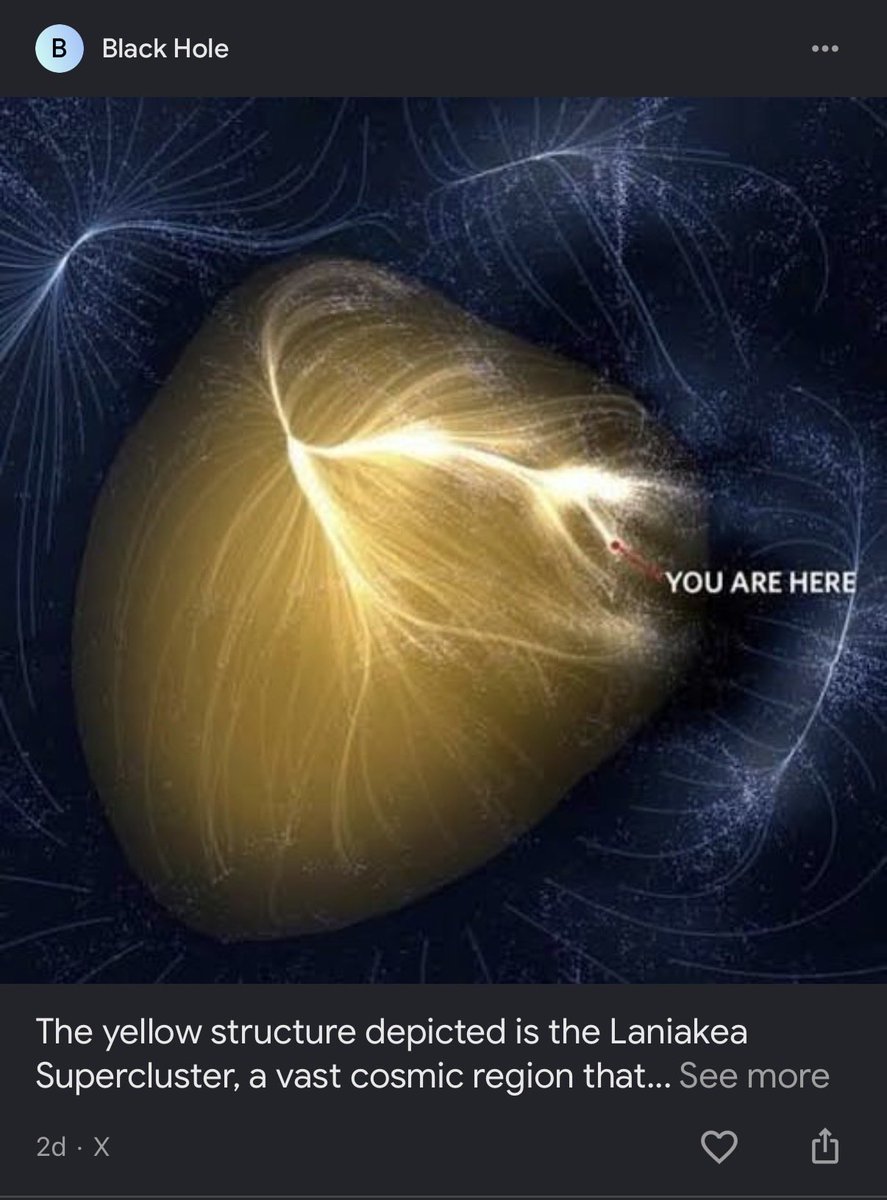
You live on a wet rock orbiting a medium star inside a supercluster called Laniakea that contains 100,000 galaxies inside an observable universe that might be a rounding error inside whatever the actual universe is.
That is your address.
And today you asked an AI to rewrite a paragraph because the tone wasn’t right.
I prompt AI all day. That is my job. I think, I type, a machine that holds the sum of human knowledge writes me things, I adjust, I type again. That is the loop.
While I do this, the planet is spinning at 1,600 km/h. Orbiting the sun at 107,000. The solar system moving through the galaxy at 800,000.
Nobody feels it. You just sit there with your coffee and your carefully worded prompt.
We built machines that process more information per second than any human could in a lifetime. Every civilization before us would have called that divine. We use it to write captions.
I am not complaining. I like my life. I go outside. I touch grass.
But sometimes you look up from the screen and the gap between what is actually happening and what it feels like is the funniest thing in the world.
Pascal had no telescope. He just looked up and did the math and realized the universe was not built to care.
Marcus Aurelius governed Rome and spent his evenings writing reminders that none of it mattered. He commanded legions. Shaped civilizations. Every night he wrote the same thing. You are a temporary arrangement of atoms.
He didn’t stop governing. He governed better.
The reminder kept his grip loose.
Laniakea contains the mass of a hundred quadrillion suns. Everything humans have ever done happened in a region so small that rounding it to zero is more accurate than measuring it.
You are typing prompts into the void. The void doesn’t read them.
But you got to be conscious for a few decades on a planet where the sunsets are absurd and the machines are interesting and none of it was guaranteed.
Go outside. Look up. Come back. Keep building.
Hold it looser.
English










