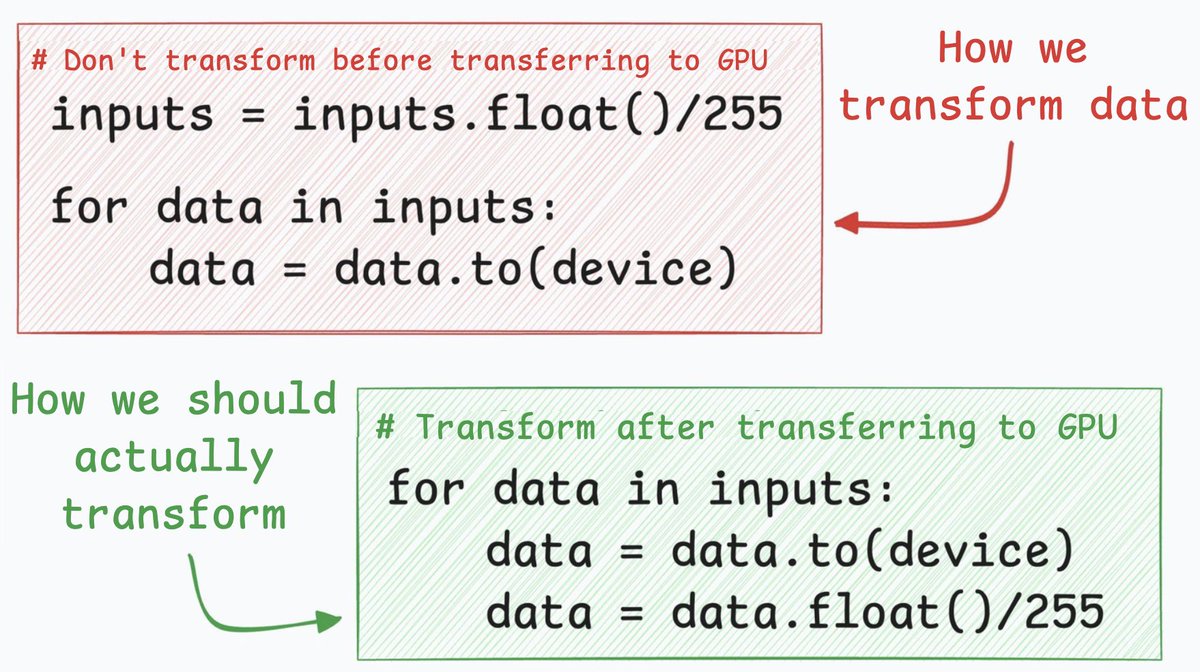
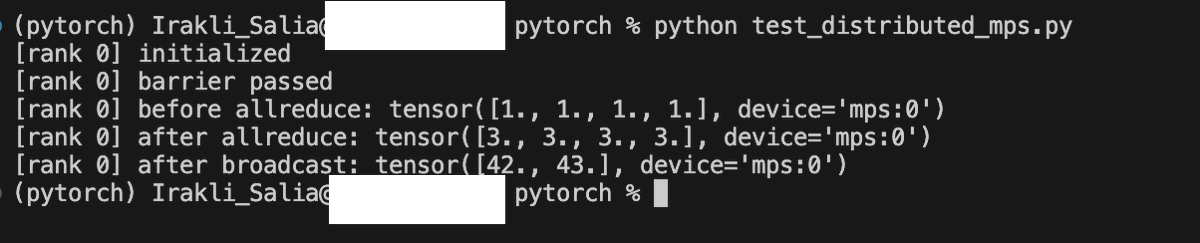
@baggiponte Agree on it being second-class citizen. AFAIK there is no official roadmap, but it should become much better/faster in next 2 releases (2.13/2.14)
English
Isalia20
607 posts
@Is36E
PyTorch enjoyer @ HF 🤗 https://t.co/G5bfywg70T


This marks the end of my first week at @huggingface! I'm joining as a founding engineer on HF's PyTorch team. My first project: safetensors on Mac is up to 3x faster🚀 Parallel reads straight into MPS unified memory, no CPU staging. MB Pro M5 Pro - Cold 16 GB: **2.97 → 8.23 GB/s** (2.8×) - Warm 3 GB: **10.3 → 26.6 GB/s** (2.6×)





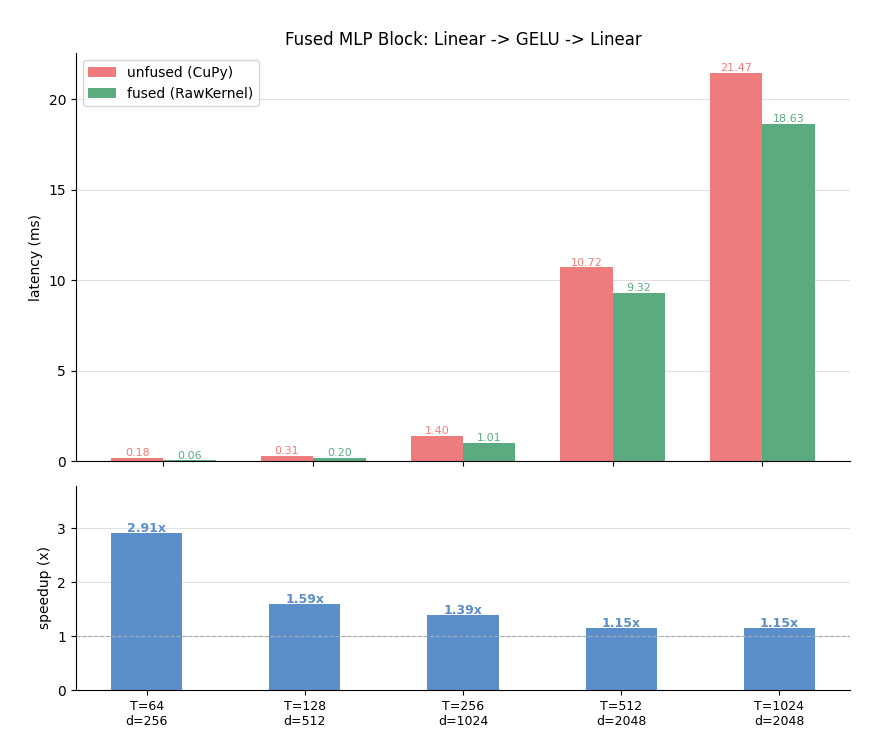
ML interview question: Suppose you are implementing Knowledge distillation, and you have a teacher and a student model. However you simply do not have the necessary GPU resources to fit both the teacher and the student into the GPU at the same time. What is your solution?


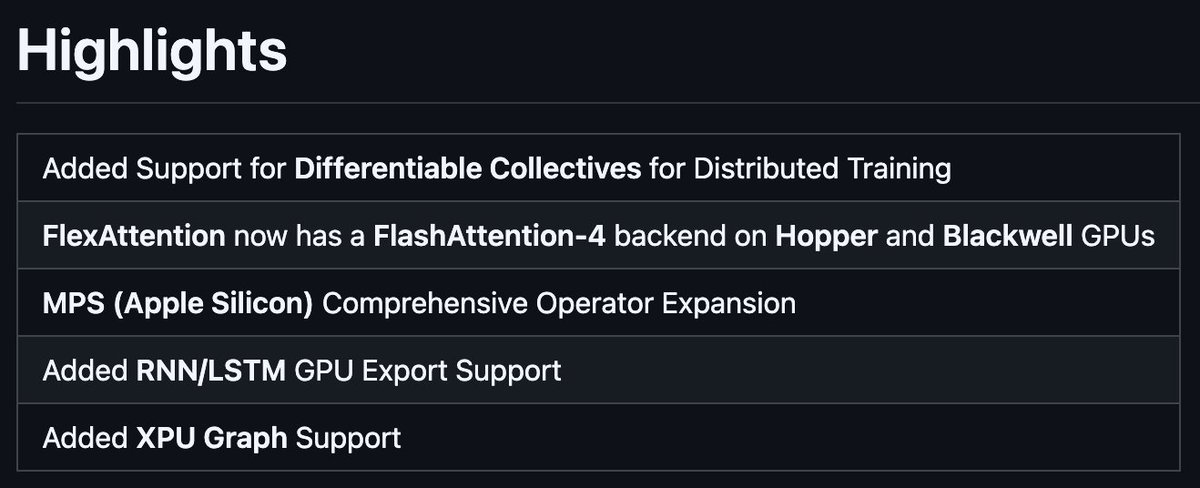

recently learned that "volatile gpu utilization" (in nvidia-smi) shows the % of time AT LEAST ONE kernel was executing if we have a single kernel running an infinite loop on one block, nvidia-smi would show gpu util as 100% despite most of the gpu being idle